Essence

LLM과 인용 간의 상호 이익적 관계
대규모 언어 모델(LLM)과 학술 인용 분석 간의 상호 보완 관계를 체계적으로 정리한 최초의 종합 조사 연구이다. LLM이 인용 분석 작업의 성능을 향상시키고, 역으로 인용 데이터가 LLM의 텍스트 표현을 개선하는 양방향 이익 구조를 제시한다.
저자: Yang Zhang, Yufei Wang, Kai Wang, Quan Z. Sheng, Lina Yao, A. Mahmood, Wei Emma Zhang, Rongying Zhao | 날짜: 2023 | DOI: 10.48550/arXiv.2309.09727
LLM과 인용 간의 상호 이익적 관계
대규모 언어 모델(LLM)과 학술 인용 분석 간의 상호 보완 관계를 체계적으로 정리한 최초의 종합 조사 연구이다. LLM이 인용 분석 작업의 성능을 향상시키고, 역으로 인용 데이터가 LLM의 텍스트 표현을 개선하는 양방향 이익 구조를 제시한다.
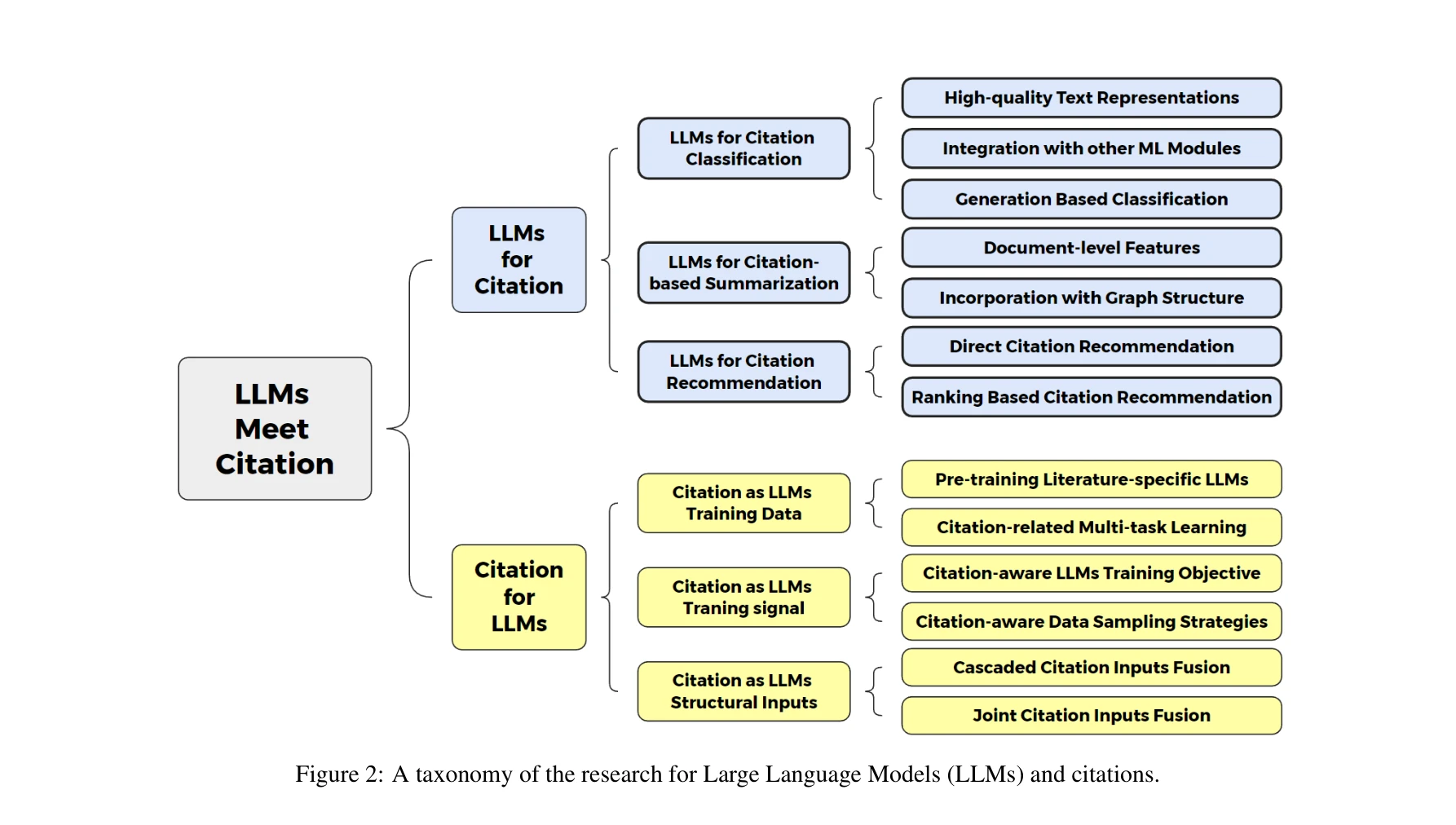
LLM과 인용 연구의 분류 체계

LLM이 인용 작업을 개선하는 경로
인용 분류(Citation Classification)
인용 기반 요약(Citation-based Summarization)
인용 추천(Citation Recommendation)
총평: 본 논문은 LLM과 인용 분석 간의 상호 이익 관계를 최초로 체계적으로 정리한 중요한 조사 연구이며, 향후 학술 정보 처리 및 LLM 개선 분야에 명확한 연구 방향을 제시한다. 다만 실증적 성과와 정량적 비교가 강화되면 더욱 강력한 기여가 될 수 있을 것으로 예상된다.