Essence
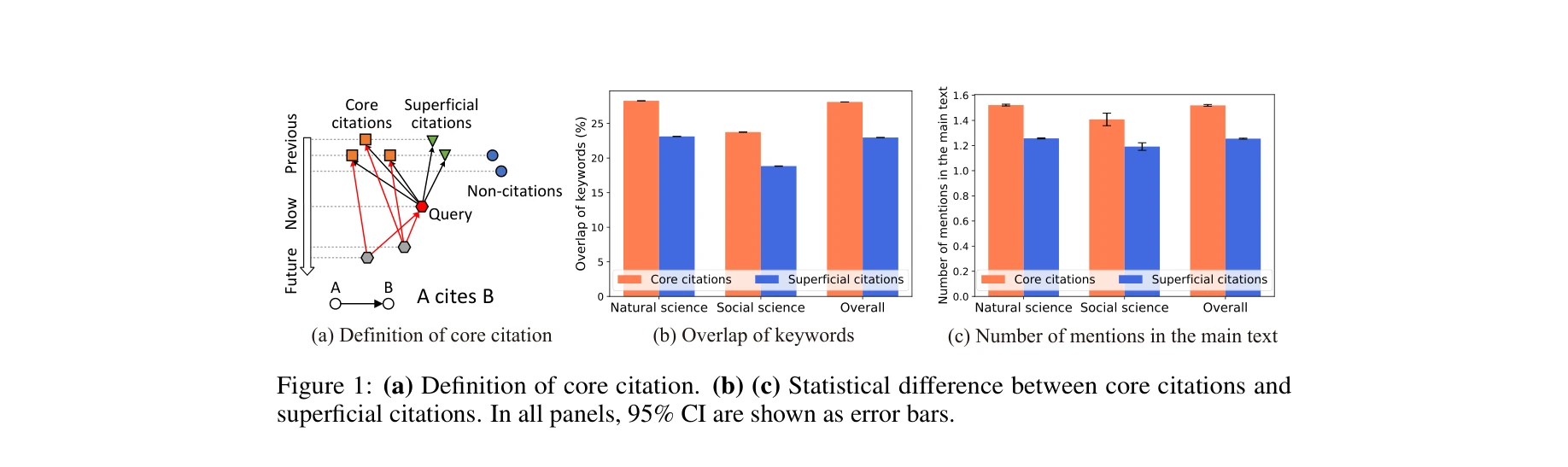
Figure 1: (a) 핵심 인용(Core Citation) 정의. (b)(c) 핵심 인용과 표면적 인용의 통계적 차이: 키워드 겹침(b)과 주요 텍스트 내 언급 빈도(c)
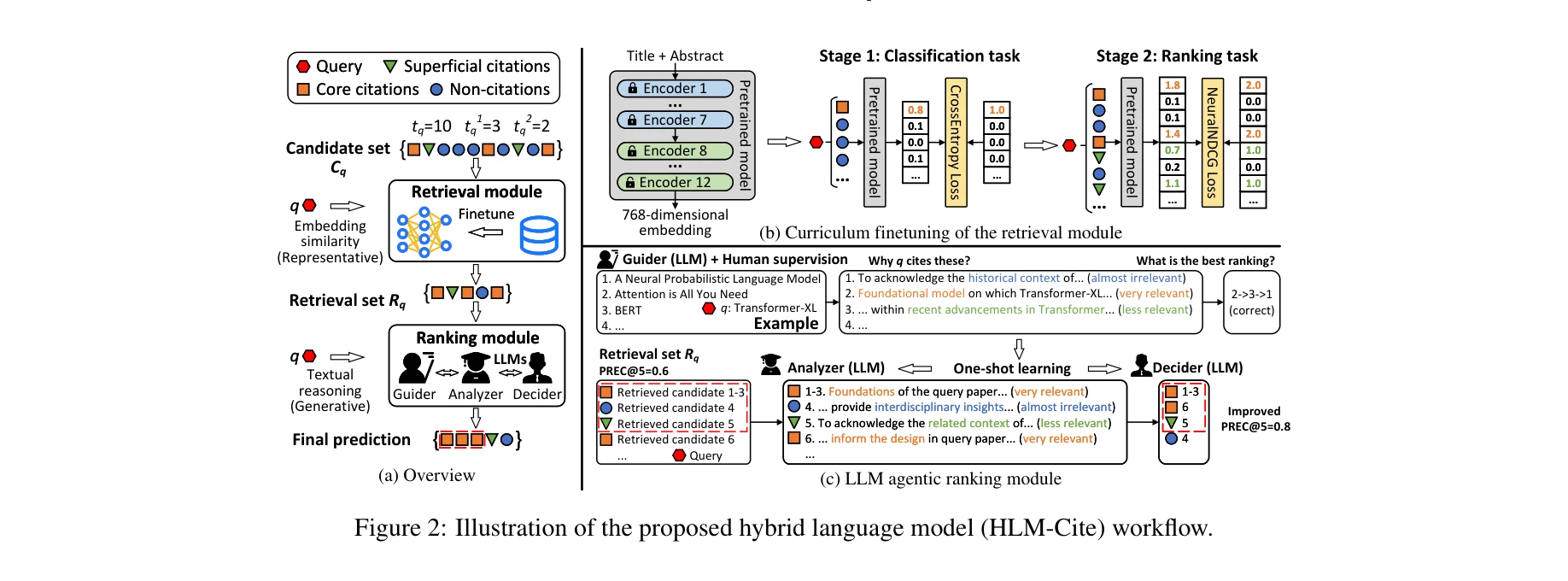
본 논문은 과학 논문의 인용 예측 문제를 단순한 이진 분류에서 벗어나 핵심 인용(core citations)을 표면적 인용 및 비인용과 구별하는 다단계 분류 문제로 재정의하고, 임베딩 모델과 생성형 LLM을 결합한 하이브리드 워크플로우(HLM-Cite)를 제안한다.
How
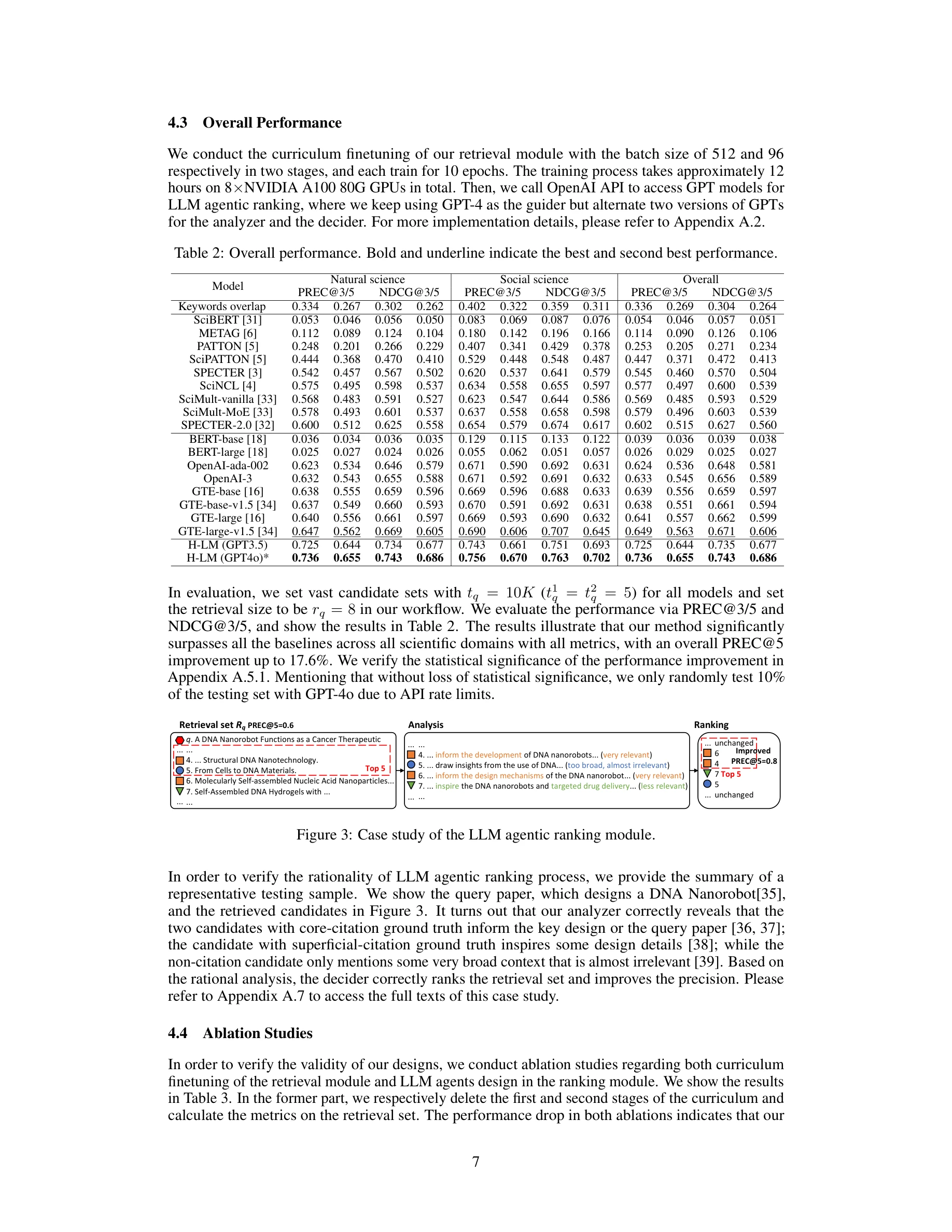
Figure 3: LLM 에이전트 순위 결정 모듈의 사례 연구. Guider의 원샷 학습 예시(2→3→1의 정렬)를 통해 Analyzer와 Decider가 논리적 관계를 추론하고 순위를 결정
2단계 하이브리드 워크플로우
Stage 1: 검색 모듈 (Embedding-based Retrieval)
- 사전학습된 텍스트 임베딩 모델을 커리큘럼 파인튜닝으로 적응
- Stage 1 (분류): CrossEntropy Loss로 핵심/표면적 인용 이진 분류 학습
- Stage 2 (순위 결정): NeuralNDCG Loss로 순위 학습으로 전이 (ranking-aware)
- 제목+초록만 사용하여 768차원 임베딩 생성
- 대규모 후보 집합(Cq)에서 고확률 핵심 인용 추출 (반환 집합 Rq)
Stage 2: LLM 에이전트 순위 결정 모듈 (Generative LLM-based Reasoning)
- 3-역할 에이전트 아키텍처:
- Guider: 원샷(one-shot) 학습 예시 제공, 쿼리 논문이 왜 특정 논문을 인용하는지 설명
- Analyzer: 각 검색된 후보 논문에 대해 쿼리 논문과의 논리적 관계 분석
- Decider: 최종 순위 결정
- 암시적 논리 관계를 명시적 추론으로 전환
주요 설계 특징
- 텍스트 기반 예측: 훈련/테스트 시 인용 네트워크는 그라운드 트루스 구축에만 사용, 네트워크 특성은 제외 → 미발표 원고에 적용 가능
- 커리큘럼 학습: 분류에서 순위 결정으로의 자연스러운 전이
- 확장성: 두 단계의 분리로 검색 단계는 신속하게, 순위 단계는 정교하게 처리