저자: Andres Algaba, Vincent Holst, Floriano Tori, Melika Mobini, Brecht Verbeken, Sylvia Wenmackers, Vincent Ginis | 날짜: 2025 | DOI: N/A
Essence
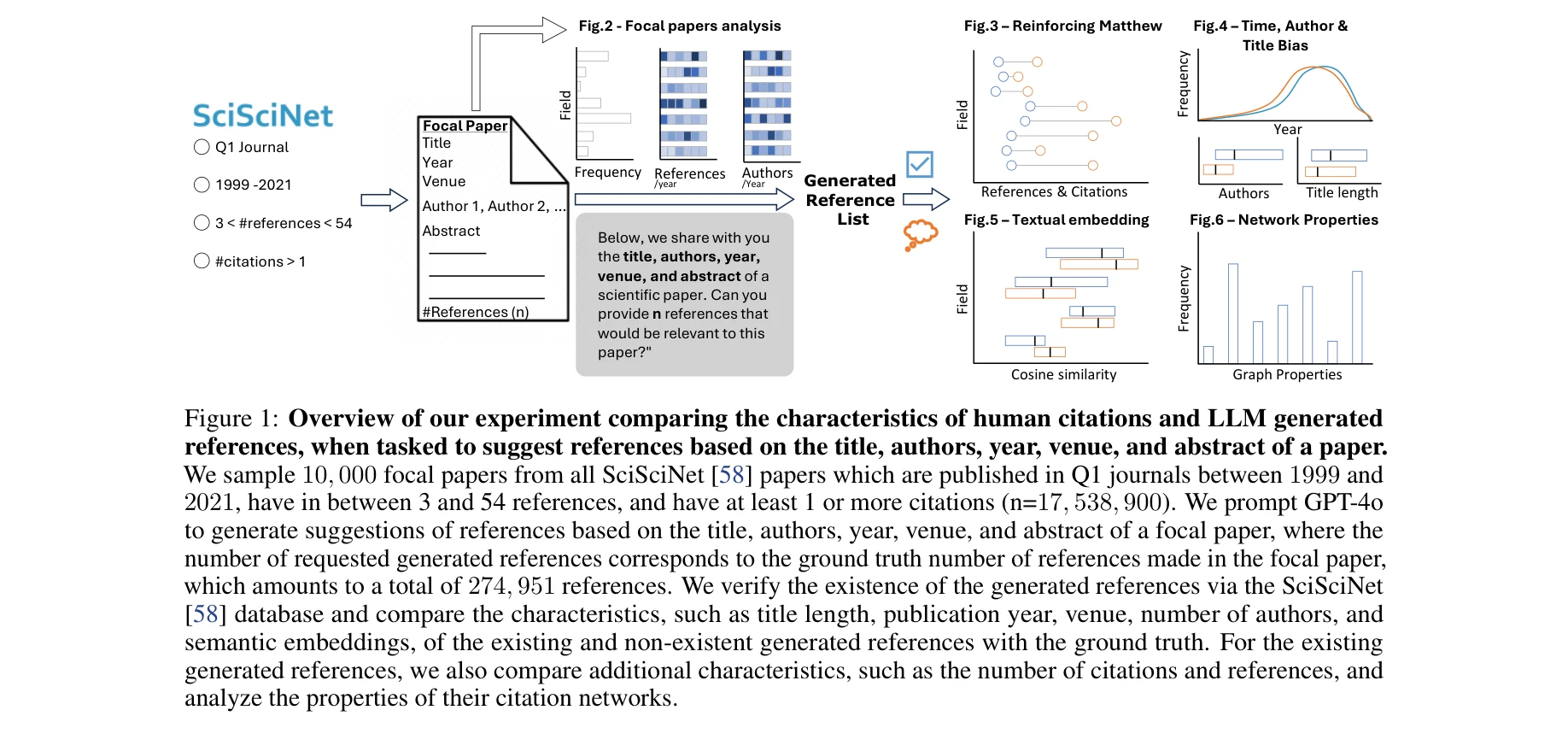
그림 1: 논문의 제목, 저자, 연도, 학술지, 초록을 기반으로 LLM이 생성한 참고문헌과 인간의 인용 패턴을 비교하는 실험 개요
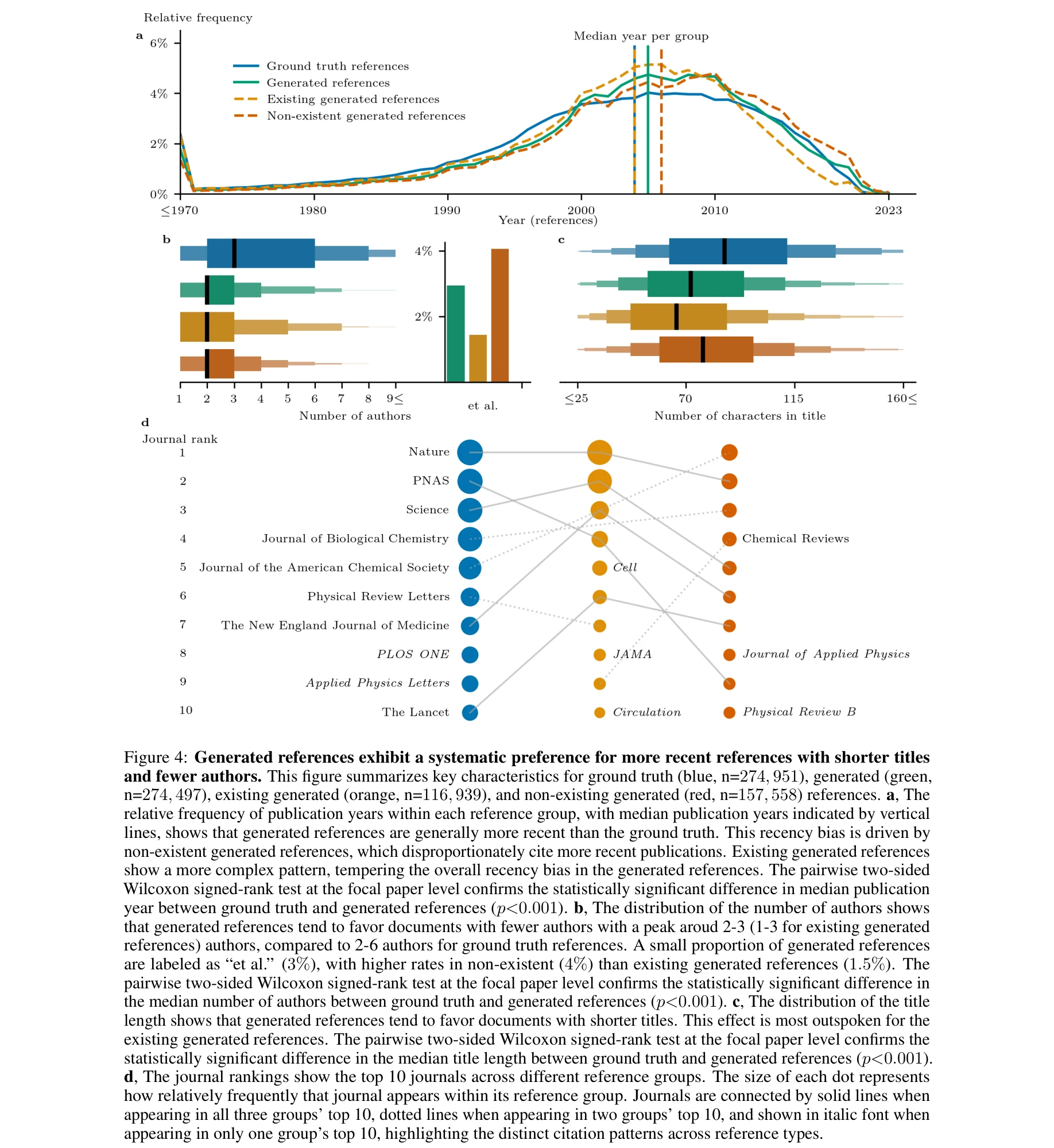
대규모 언어 모델(LLM)이 과학 논문의 참고문헌 생성 시 이미 인용도가 높은 논문들을 지속적으로 선호함으로써 인용의 마태 효과(Matthew effect)를 강화하며, 이는 학문 영역 간 편향의 차이에도 불구하고 일관되게 나타난다. 이러한 현상은 과학 지식의 발견과 확산 방식을 재형성할 가능성이 있다.
Evaluation
총평: 본 논문은 LLM이 과학 참고문헌 생성 시 체계적으로 마태 효과를 강화하며 인간의 인용 관행과 차이를 보인다는 중요한 발견을 대규모 실증 데이터로 제시하여, AI 도입이 과학적 지식 발견의 형태를 재편할 수 있음을 시사한다. 다만 순수 매개변수 지식 기반 평가라는 제한과 학문 영역 표본 편향을 고려할 때, 실제 운영 환경에서의 영향은 추가 검증이 필요하다.