Essence
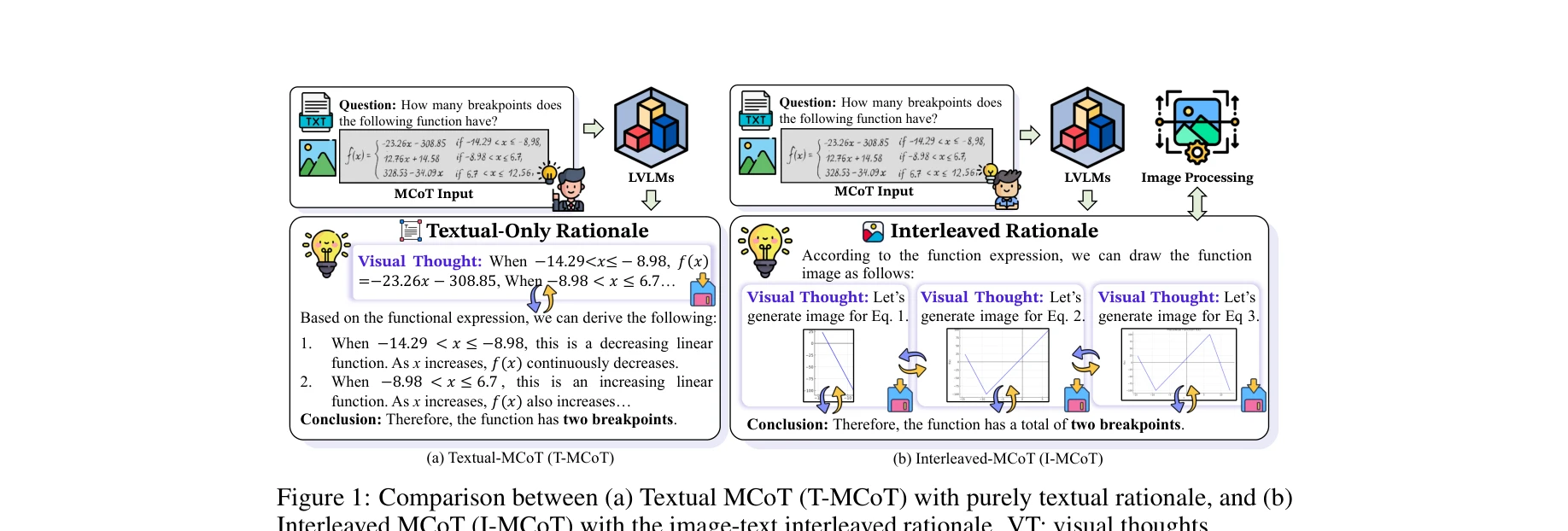
그림 1: (a) 순수 텍스트 근거를 사용하는 T-MCoT와 (b) 이미지-텍스트 교차 근거를 생성하는 I-MCoT의 비교
대규모 비전-언어 모델(LVLM)의 멀티모달 체인-오브-쏘트(MCoT) 추론에서 시각적 사고(Visual Thoughts)라는 통합된 메커니즘을 발견하였으며, 이는 텍스트 기반과 이미지 교차 방식의 MCoT 모두를 설명하는 새로운 관점을 제시한다.
저자: Zihui Cheng, Qiguang Chen, Xiao Xu 외 | 날짜: 2025 | DOI: arXiv:2505.15510
그림 1: (a) 순수 텍스트 근거를 사용하는 T-MCoT와 (b) 이미지-텍스트 교차 근거를 생성하는 I-MCoT의 비교
대규모 비전-언어 모델(LVLM)의 멀티모달 체인-오브-쏘트(MCoT) 추론에서 시각적 사고(Visual Thoughts)라는 통합된 메커니즘을 발견하였으며, 이는 텍스트 기반과 이미지 교차 방식의 MCoT 모두를 설명하는 새로운 관점을 제시한다.
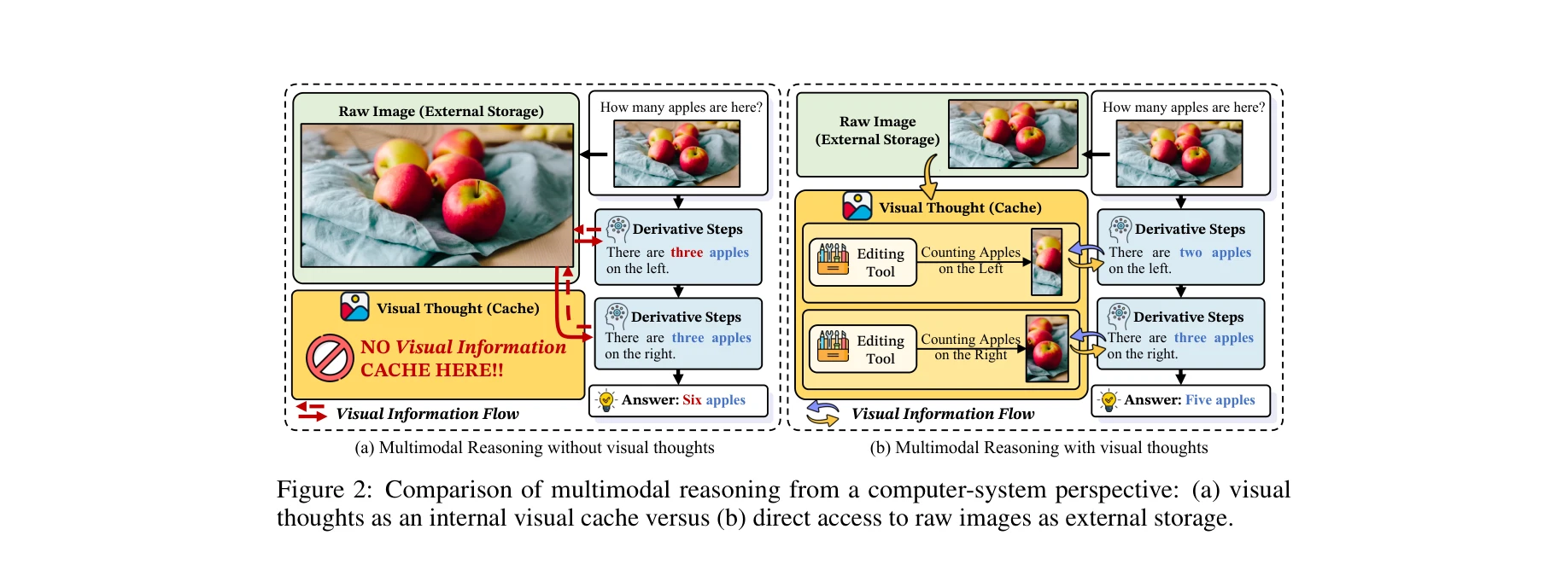
그림 2: 컴퓨터 시스템 관점에서의 멀티모달 추론 비교: (a) 시각적 사고를 내부 캐시로 활용 vs (b) 원본 이미지에 직접 접근
각 전략은 명확성과 효율성에서 차이를 보이며, 특정 시나리오에서 상이한 성능을 발휘한다.
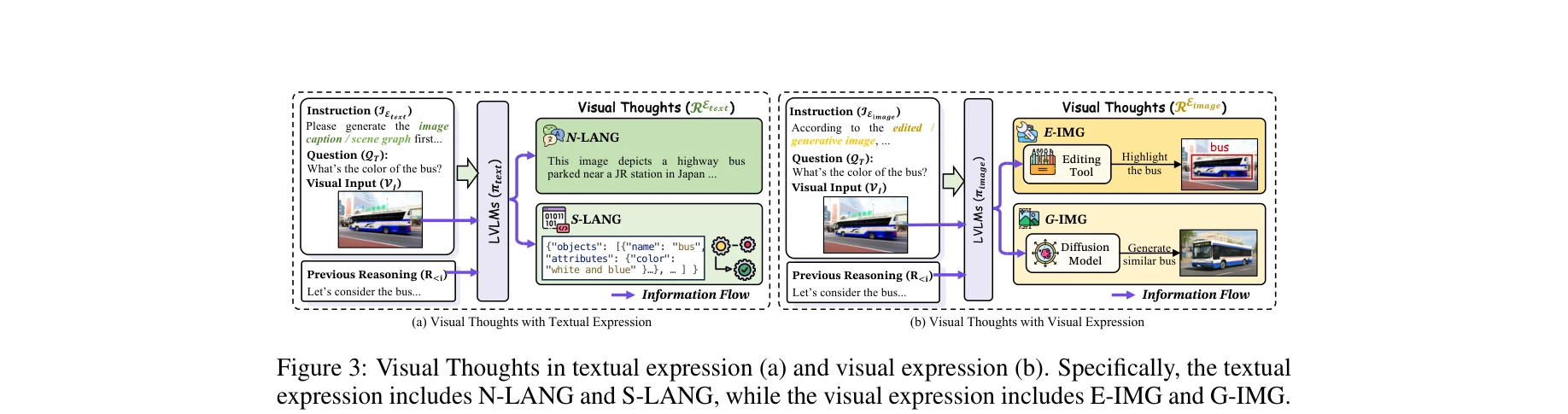
그림 3: 텍스트 표현 (a)과 시각 표현 (b)의 시각적 사고. 텍스트 표현은 N-LANG과 S-LANG, 시각 표현은 E-IMG와 G-IMG를 포함
총평: 본 논문은 멀티모달 추론 분야의 오랜 논쟁(T-MCoT vs I-MCoT)에 "시각적 사고"라는 새로운 이론적 렌즈를 제공함으로써 개념적 통합을 이루었으며, 4가지 표현 전략의 체계적 분류는 향후 MCoT 방법론 개발의 로드맵을 제시한다. 다만 내부 메커니즘 분석의 기술적 깊이와 실제 성능 이득에 대한 정량적 검증이 보강된다면 더욱 영향력 있는 기여가 될 것으로 예상된다.