Essence
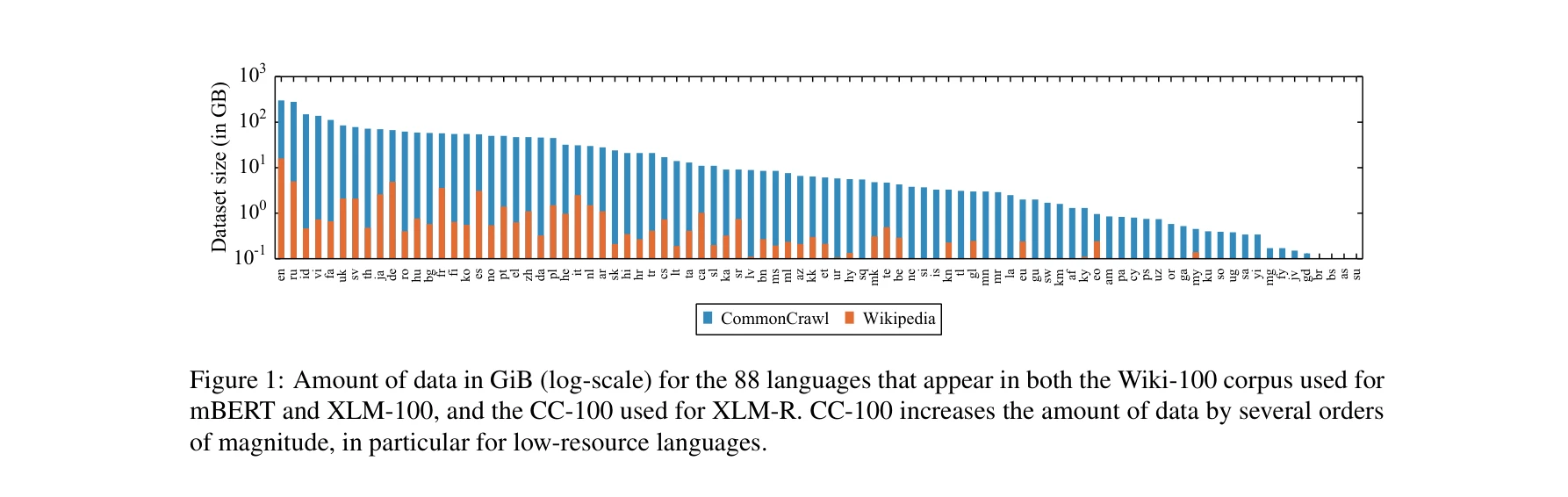
그림 1: 88개 언어에 대한 데이터 크기 비교 (GiB, 로그 스케일). CommonCrawl은 저자원 언어의 데이터를 수십 배 이상 증가시킴
본 논문은 100개 언어에서 2TB 이상의 필터링된 CommonCrawl 데이터로 사전학습한 XLM-RoBERTa (XLM-R)를 제시하며, 다언어 마스크 언어 모델링이 대규모로 학습될 때 교차언어 전이학습 성능을 크게 향상시킴을 보여준다.
저자: Alexis Conneau, Kartikay Khandelwal, et al. (Facebook AI) | 날짜: 2019 | DOI: arXiv:1911.02116
그림 1: 88개 언어에 대한 데이터 크기 비교 (GiB, 로그 스케일). CommonCrawl은 저자원 언어의 데이터를 수십 배 이상 증가시킴
본 논문은 100개 언어에서 2TB 이상의 필터링된 CommonCrawl 데이터로 사전학습한 XLM-RoBERTa (XLM-R)를 제시하며, 다언어 마스크 언어 모델링이 대규모로 학습될 때 교차언어 전이학습 성능을 크게 향상시킴을 보여준다.
총평: XLM-R은 대규모 다언어 데이터와 모델 확장이 교차언어 이해의 새로운 지평을 열 수 있음을 명확히 보여준 영향력 있는 연구로, 특히 다언어성의 저주 개념 도입과 저자원 언어 성능 혁신이 후속 연구에 미친 영향이 매우 큼. 다만 계산 효율성 측면의 개선 방안은 향후 과제로 남음.