저자: Mengkang Hu, Yao Mu, Xinmiao Yu, Mingyu Ding, Shiguang Wu, Wenqi Shao, Qiguang Chen, Bin Wang, Yu Qiao, Ping Luo | 날짜: 2023 | DOI: N/A
Essence
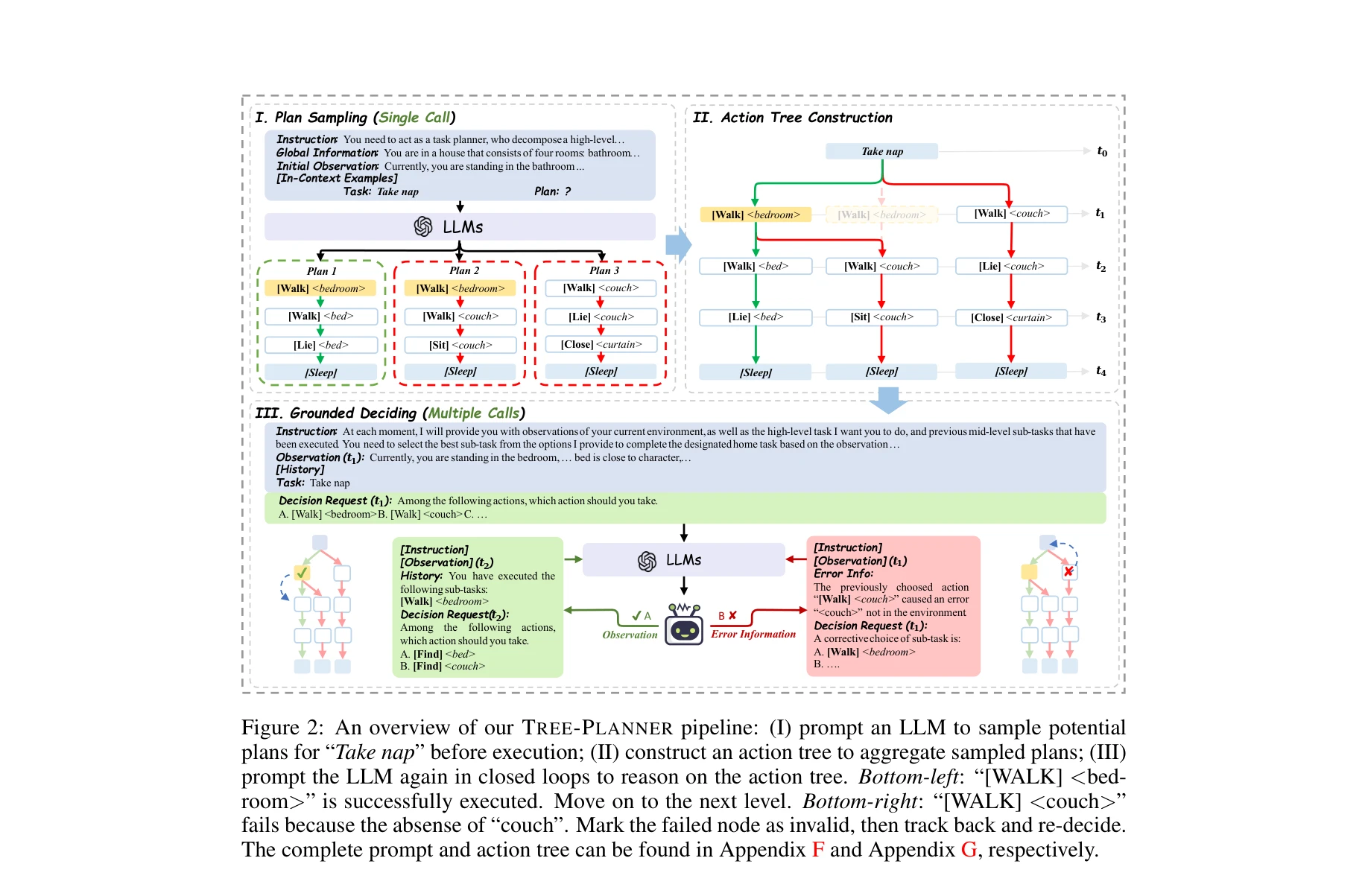
TREE-PLANNER의 3단계 파이프라인: (I) 실행 전 잠재적 계획 샘플링, (II) 샘플링된 계획들을 집계하여 액션 트리 구성, (III) 폐루프에서 LLM이 액션 트리 상에서 의사결정
대규모 언어모델(LLM)을 활용한 폐루프 태스크 플래닝에서 토큰 효율성과 오류 수정 효율성을 동시에 개선하는 TREE-PLANNER를 제안한다. 기존의 반복적 플래닝(iterative planning) 대신 계획 샘플링-액션 트리 구성-그라운디드 의사결정의 3단계로 재구조화하여 토큰 소비 92.2% 감소와 오류 수정 40.5% 감소를 달성한다.
How
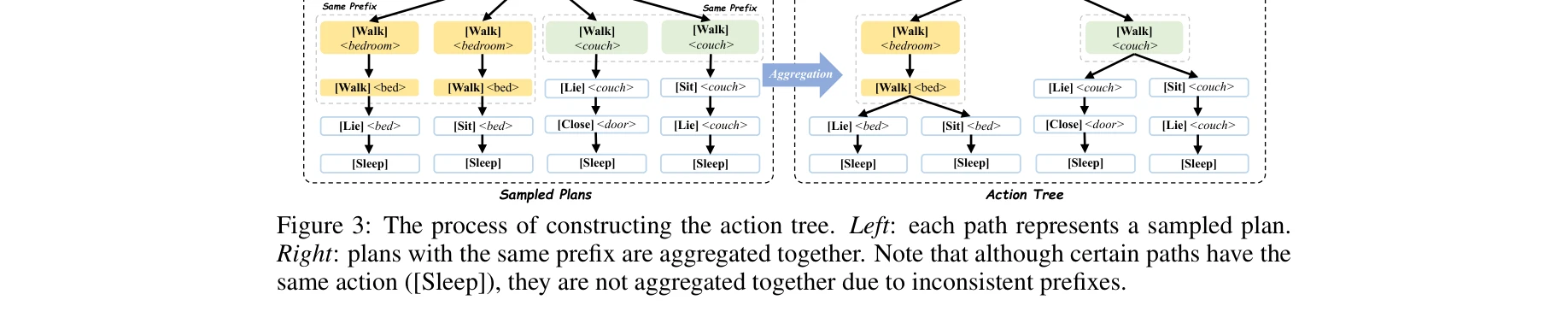
액션 트리 구성 프로세스: 샘플링된 계획들의 공통 프리픽스를 집계하여 트리 구조로 변환
Stage I. 계획 샘플링 (Plan Sampling)
- LLM(ρ_ps, g) = {c₁, c₂, ..., c_N}을 통해 N개의 잠재적 계획을 단일 호출로 샘플링
- 프롬프트 구성: 명령어(instruction), 환경 정보(global information), 초기 관찰(initial observation), 문맥 예시(in-context examples)
- LLM의 상식 지식을 먼저 추출하는 단계로, 실행 전 다양한 계획 후보 생성
Stage II. 액션 트리 구성 (Action Tree Construction)
- 샘플링된 계획들의 공통 프리픽스를 식별하고 집계
- 동일한 초기 액션 시퀀스를 공유하는 계획들의 중복을 제거하며 트리 구조로 병합
- 이를 통해 계획들 간의 공통성을 활용하고 의사결정 공간을 체계화
Stage III. 그라운디드 의사결정 (Grounded Deciding)
- 폐루프: 환경 관찰을 받아 액션 트리를 top-down 방식으로 탐색
- 각 타임스텝에서 현재 노드의 자식 노드(가능한 다음 액션) 중 최적을 선택
- 액션 실패 시 해당 노드를 무효 표시하고 백트래킹하여 대체 경로 탐색
- 부분 관찰 가능 마르코프 결정 과정(POMDP) 프레임워크에서 최적 정책 π(a_t|g, h_t, o_t) 추구
핵심 메커니즘
- 토큰 효율: 환경 설명과 예시 토큰이 계획 샘플링에서만 청구되고, 그라운디드 의사결정에서는 더 간결한 프롬프트 사용
- 수정 효율: 로컬 재계획(LOCAL)보다 조정 범위가 크고, 글로벌 재계획(GLOBAL)보다 비용이 적은 중간 지점 제공
