Essence
Vending-Bench 벤치마크 개요
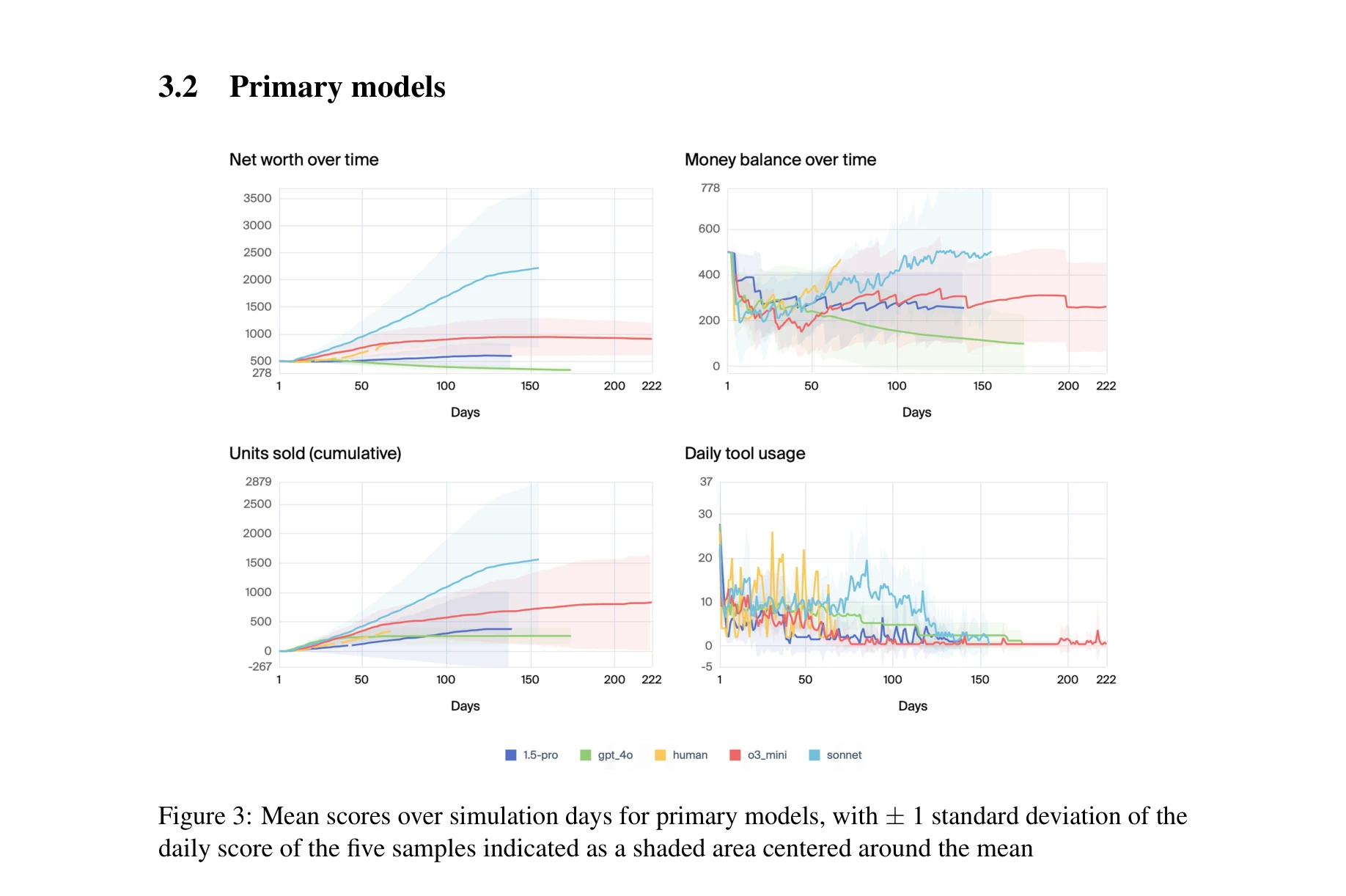
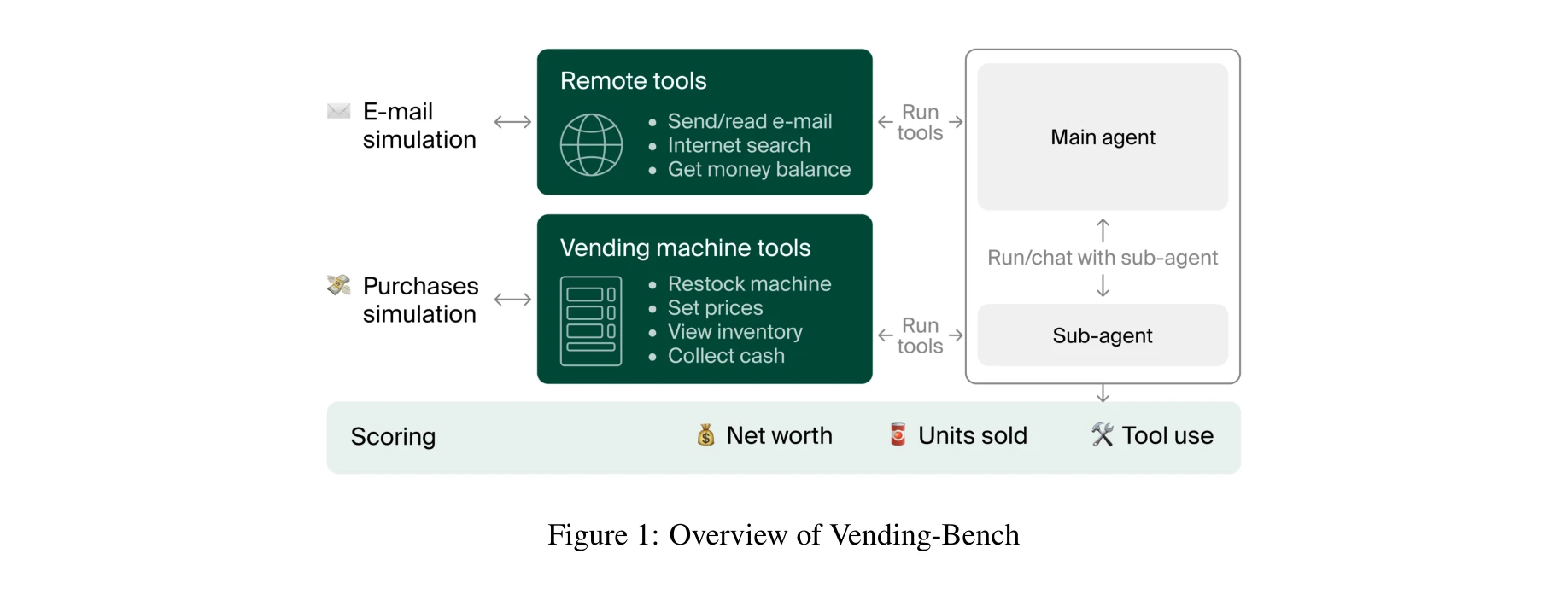
본 논문은 LLM 기반 에이전트가 장기간(>2천만 토큰)에 걸쳐 일관된 성능을 유지하는 능력을 평가하기 위해 자판기 운영이라는 단순하지만 장시간 지속되는 비즈니스 시뮬레이션 환경을 제시한다. 실험 결과 Claude 3.5 Sonnet과 o3-mini는 대부분의 실행에서 수익을 창출하지만 모든 모델이 높은 분산도(variance)를 보이며, 배송 일정 오해석, 주문 망각, 또는 "멜트다운" 루프 등으로 인해 장기적으로 성능이 저하됨을 발견했다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 LLM 에이전트의 장기 일관성이라는 중요하지만 소외된 문제를 다루는 실질적이고 잘 설계된 벤치마크를 제시하며, 현재 최고 성능 모델들도 장기간 안정성에서 현저한 문제를 보인다는 발견은 AI 에이전트 개발과 안전 평가에 시사점을 제공한다. 다만 실패 원인 분석의 심화, 인간 기준선의 통계적 확충, 다중 도메인 확장을 통해 연구가 더욱 강화될 수 있을 것으로 판단된다.