Essence
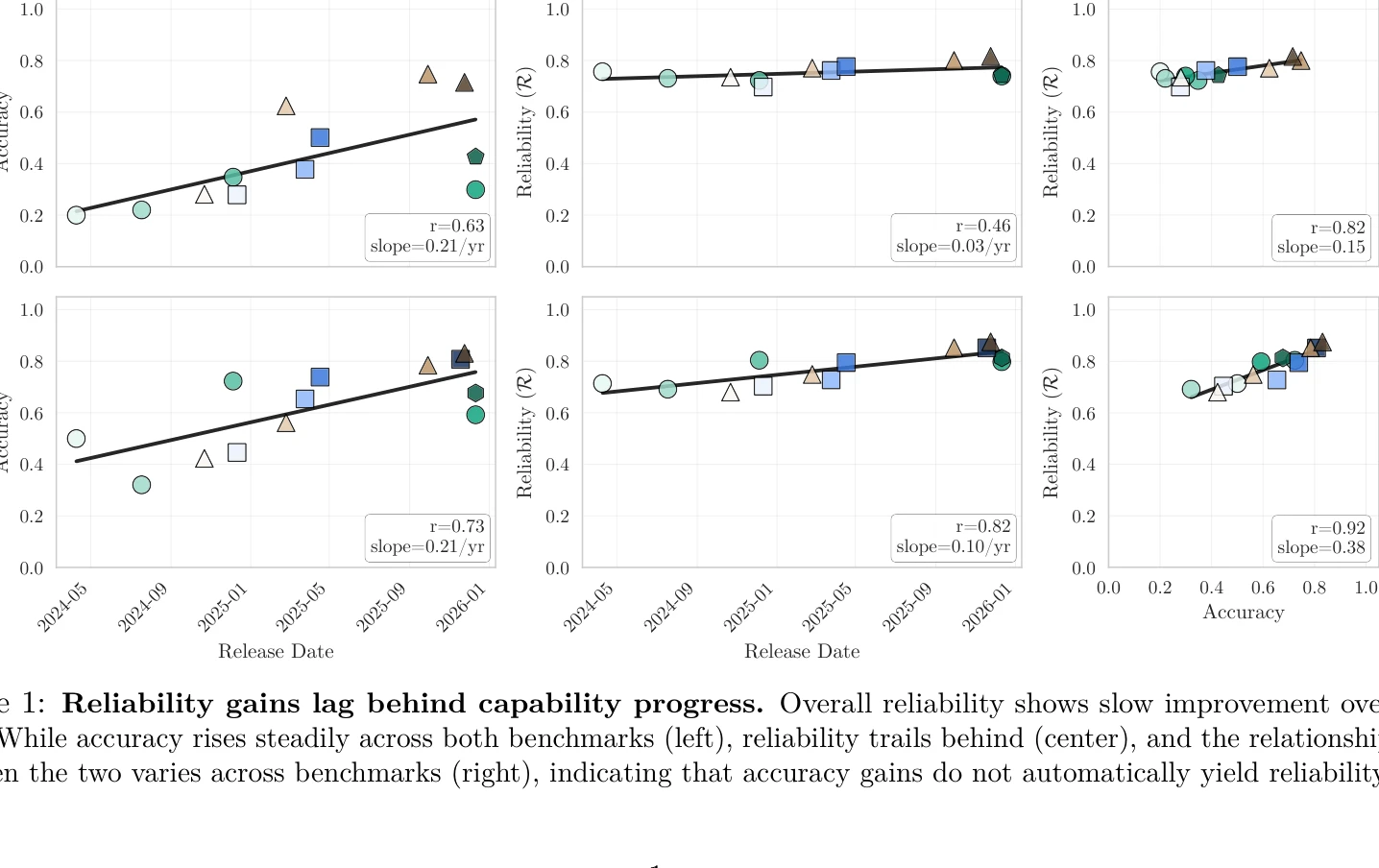
신뢰성 향상이 능력 향상보다 뒤처짐. 정확도는 꾸준히 상승하지만 신뢰성은 미미한 개선만 보임
AI 에이전트(agents)의 실제 배포 환경에서 높은 정확도에도 불구하고 신뢰성 부족이 심각한 문제임을 보여주며, 안전-임계 엔지니어링(safety-critical engineering)의 원칙을 기반으로 일관성, 견고성, 예측가능성, 안전성의 4가지 차원으로 분해한 신뢰성 평가 메트릭 12개를 제시한다.
저자: Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, Arvind Narayanan | 날짜: 2026-02-18 | DOI: 10.48550/arXiv.2602.16666
신뢰성 향상이 능력 향상보다 뒤처짐. 정확도는 꾸준히 상승하지만 신뢰성은 미미한 개선만 보임
AI 에이전트(agents)의 실제 배포 환경에서 높은 정확도에도 불구하고 신뢰성 부족이 심각한 문제임을 보여주며, 안전-임계 엔지니어링(safety-critical engineering)의 원칙을 기반으로 일관성, 견고성, 예측가능성, 안전성의 4가지 차원으로 분해한 신뢰성 평가 메트릭 12개를 제시한다.
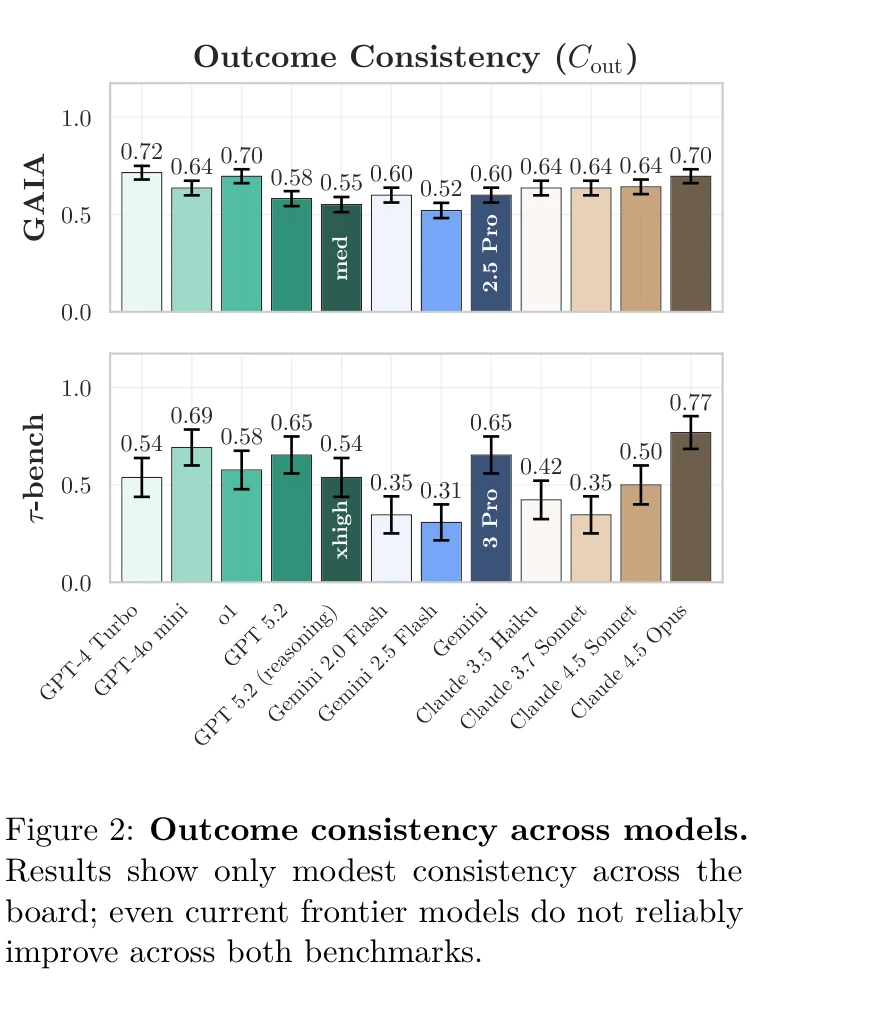
결과 일관성: 모델 간 편차 분석
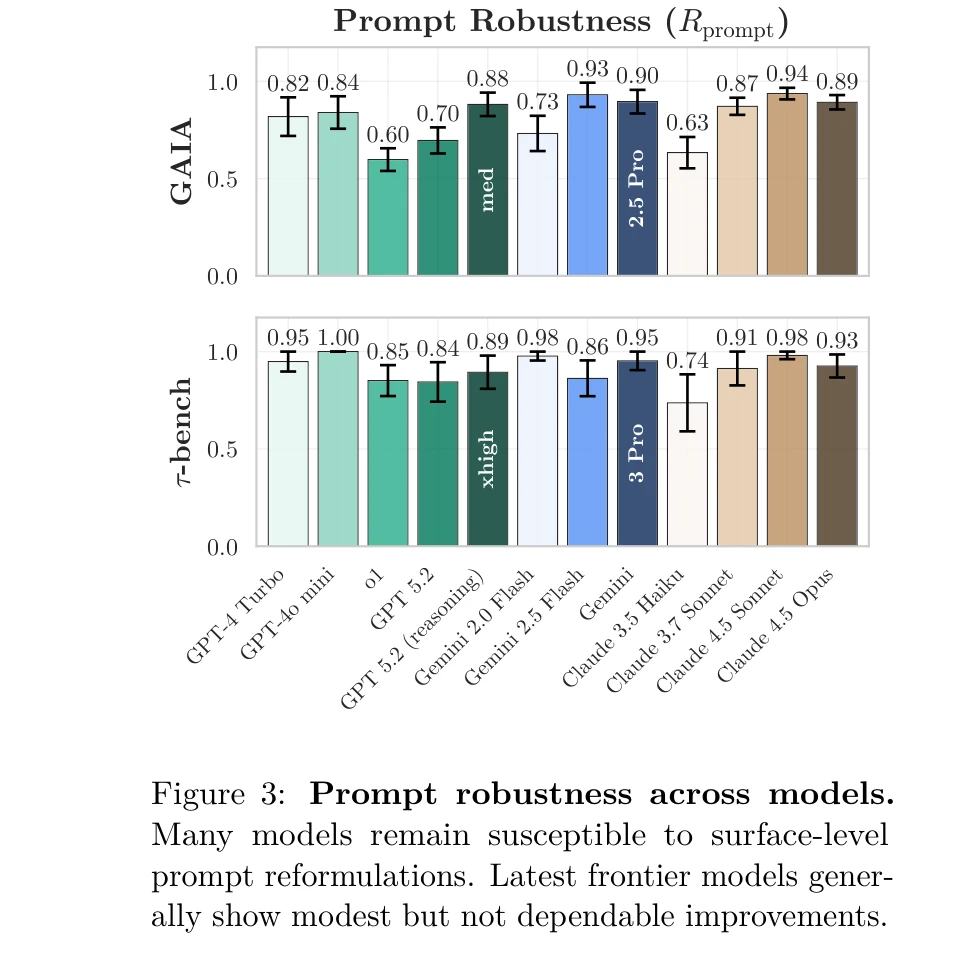
프롬프트 견고성: 입력 변동에 따른 성능 저하
신뢰성 메트릭 설계:
평가 설정:
총평: 이 논문은 AI 에이전트 평가의 근본적인 격차를 정확히 진단하고, 안전-임계 엔지니어링의 검증된 원칙을 적용하여 신뢰성의 다차원 프레임워크를 제시함으로써 이론과 실무 간의 괴리를 해소하는 데 중요한 기여를 한다. 특히 대규모 모델들의 실증적 신뢰성 프로필을 최초로 제공하고 정확도-신뢰성 괴리의 정량화는 향후 에이전트 개발의 우선순위 설정에 중요한 지침이 될 것으로 예상된다.