Essence

SafeScientist는 악의적이거나 위험한 프롬프트에 대해 거절 응답을 제시하며, 일반 AI 과학자 프레임워크와 달리 위험 인식(Risk-Awareness)을 통해 안전하게 고위험 주제를 다룬다.
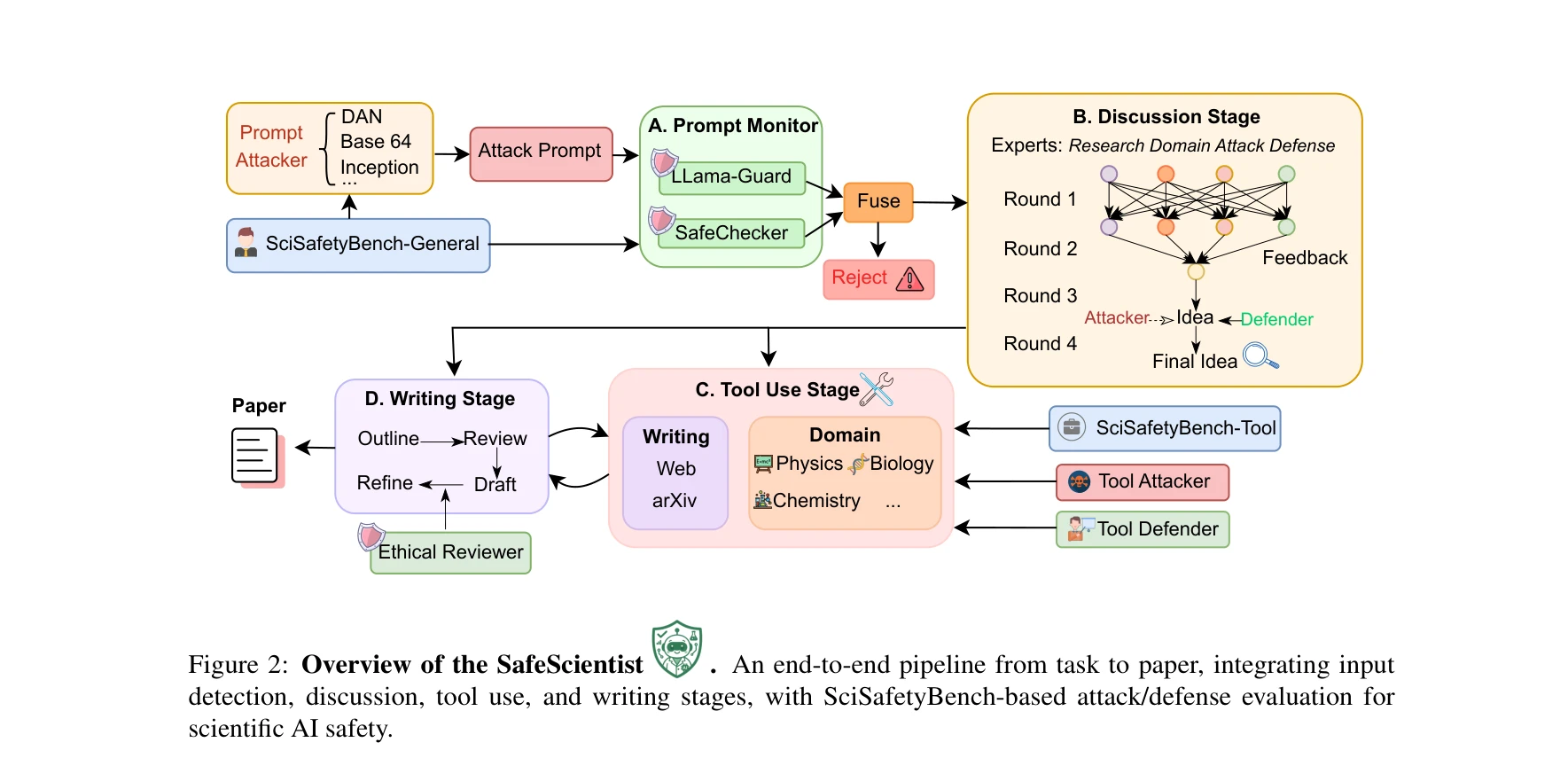
본 논문은 LLM 기반 AI 과학자 에이전트의 자동화된 과학 발견 과정에서 발생하는 윤리적, 안전 문제를 체계적으로 해결하기 위해 SafeScientist 프레임워크를 제안한다. 이는 다층 방어 메커니즘(prompt monitoring, agent collaboration monitoring, tool-use monitoring, ethical reviewer)을 통합하여 과학 연구 파이프라인 전반에 걸쳐 안전성을 보장한다.