Achievement
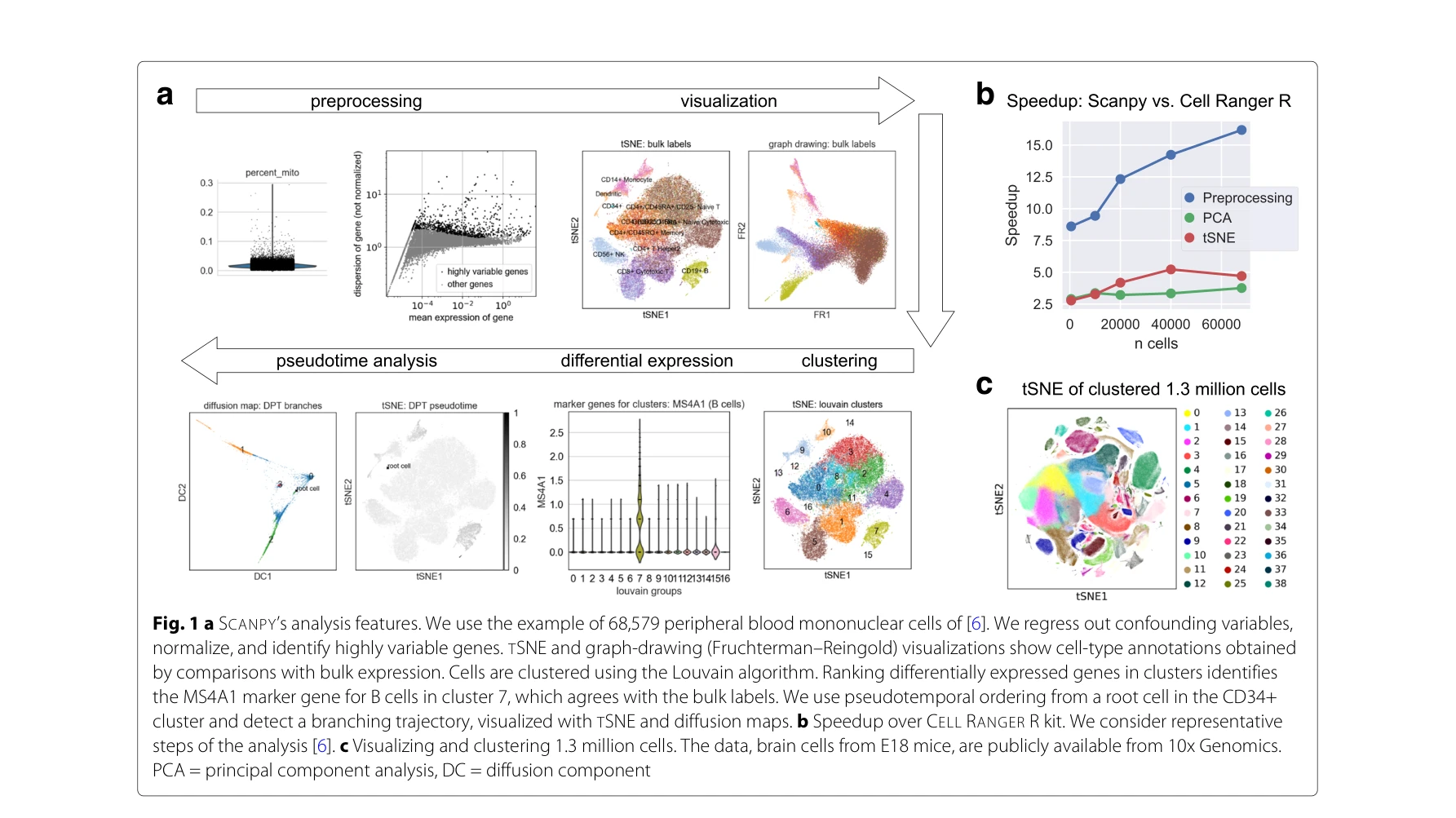
Figure 1a: 68,579개의 말초혈액 단핵세포(PBMC)를 이용한 SCANPY의 분석 파이프라인: 전처리, 정규화, 고변이성 유전자 식별, t-SNE 및 그래프 드로잉 시각화, Louvain 알고리즘을 통한 클러스터링, 차등 발현 유전자 검증, 의사시간 순서화를 통한 분기 궤적 재구성
- 성능 우수성: Cell Ranger R 킷 대비 5-16배의 속도 향상(68,579 PBMC 데이터셋); Seurat 튜토리얼 각 단계별로 5-90배 속도 향상
- 대규모 데이터 처리: 8개 코어의 소규모 서버에서 130만 개 세포를 몇 시간 내에 서브샘플링 없이 분석 가능; 약 100,000 개 세포 규모에서 초 단위의 인터랙티브 분석 시간 달성
- 종합 분석 기능: 전처리, 시각화(t-SNE, 확산맵), 클러스터링(Louvain), 마커 유전자 식별, 의사시간 순서화(diffusion pseudotime), 분기 궤적 재구성, 유전자 조절 네트워크 시뮬레이션, 딥러닝 결과 분석 등 포괄적 기능 제공