Achievement
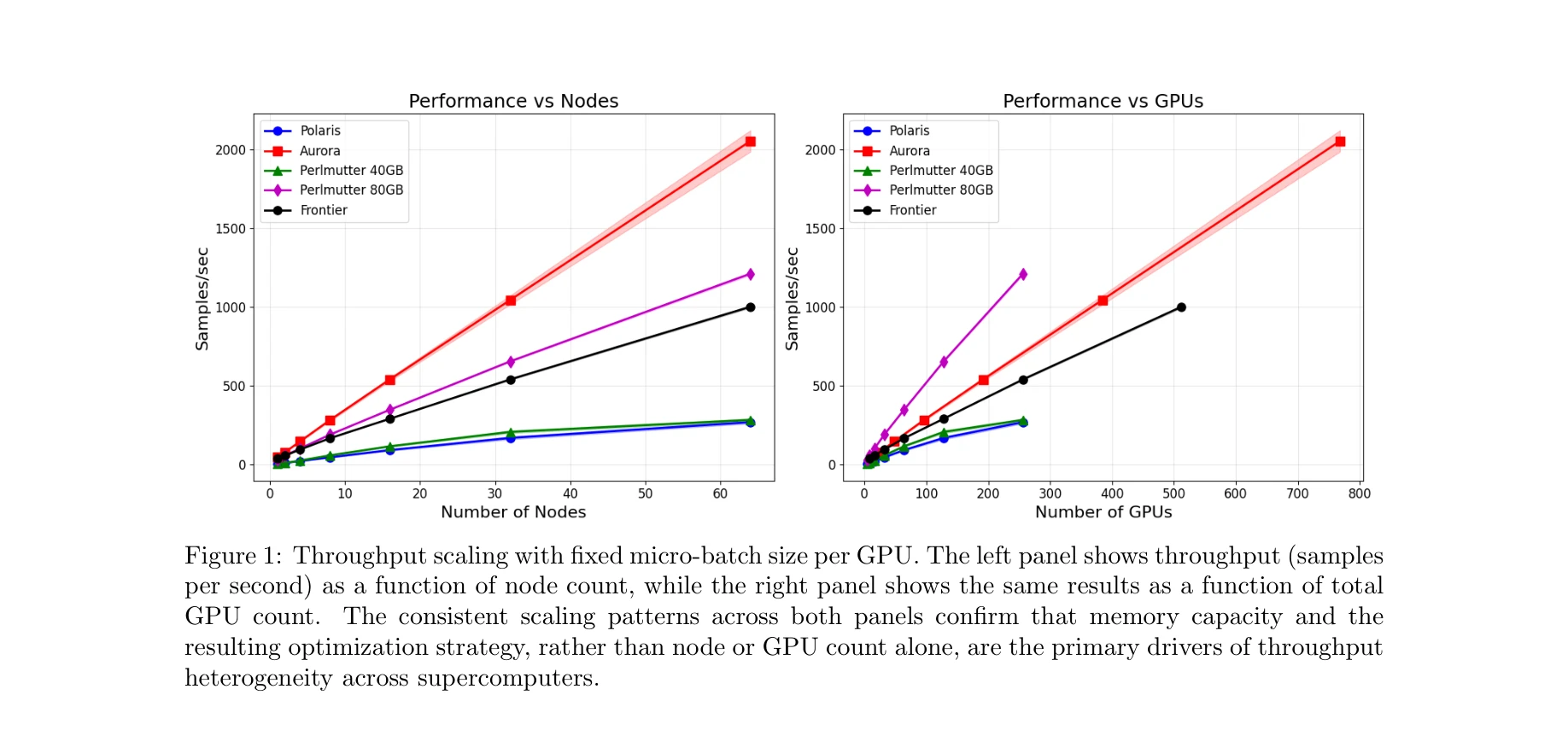
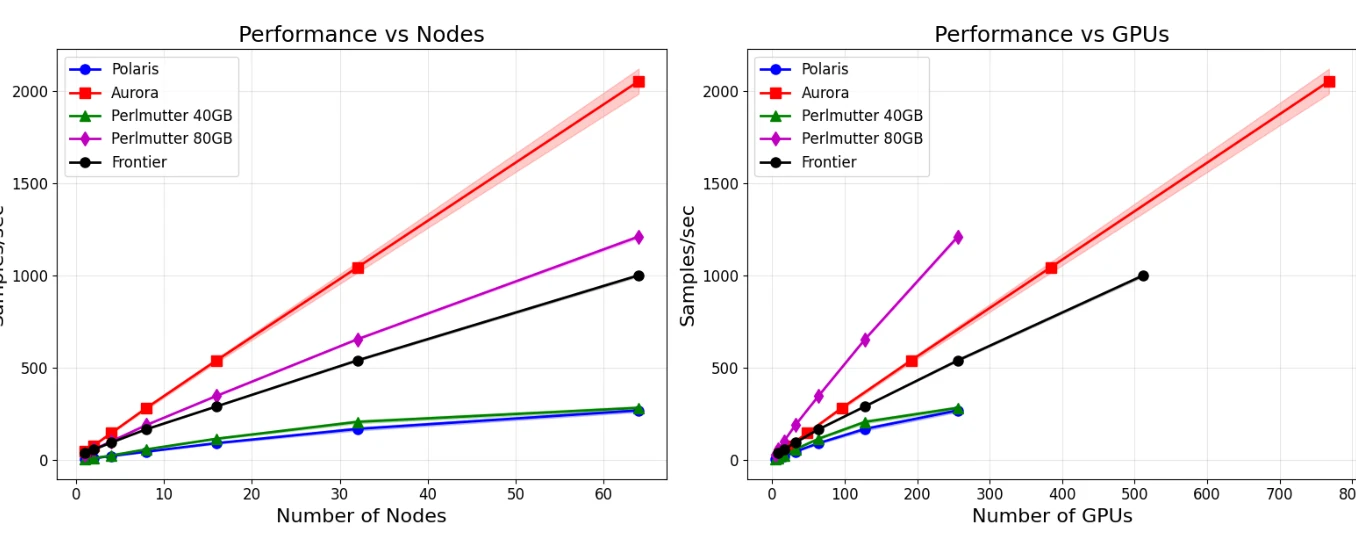
Figure 1: 고정 마이크로배치 크기당 처리량 스케일링. 왼쪽 패널은 처리량(초당 샘플)을 보여주며, Aurora는 64개 노드에서 2,100 샘플/초을, Perlmutter 80GB와 Frontier는 각각 1,200과 1,000 샘플/초을 달성한다.
- 크로스-HPC 시설 FL 프레임워크 설계 및 구현: 이질적 HPC 시설 간 훈련을 조율하고, 다양한 모델, 데이터셋, 과학 작업을 지원하며, 통신, 스케줄링, 계산 측면의 HPC 특유 도전을 해결하는 일반화 가능한 프레임워크 제시.
- 성능 특성화: GPU 메모리 용량에 의해 주도되는 극단적 처리량 이질성을 발견—Perlmutter 40GB는 ZeRO-3을 사용하여 250 샘플/초이지만, Perlmutter 80GB는 ZeRO-1을 사용하여 1,200 샘플/초를 달성(4배 차이). 통신 비용과 큐잉 역학 특성화를 통해 기존 FL 알고리즘의 부적절함을 드러냄.
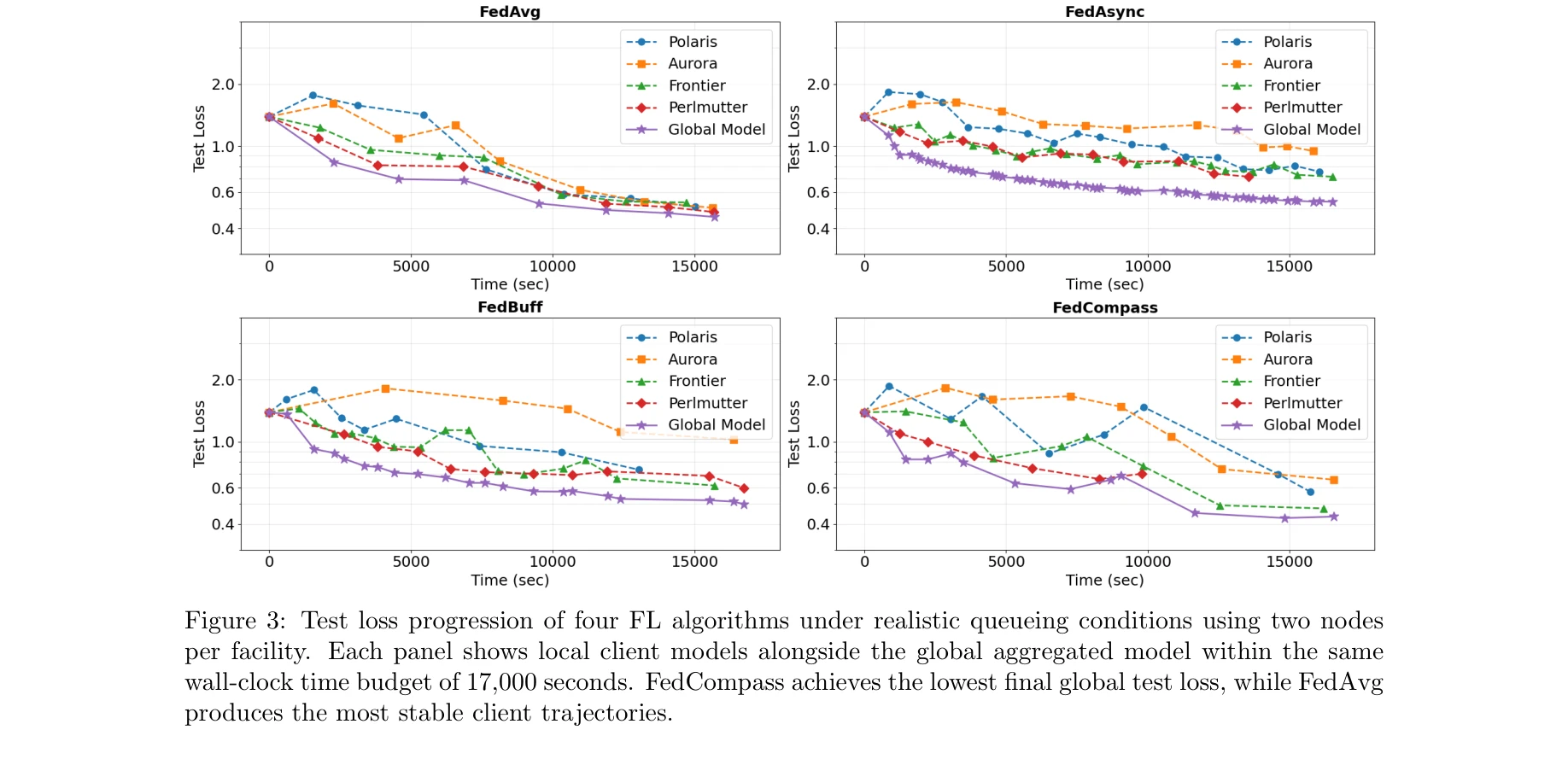
- 알고리즘 평가: 예약(co-scheduled) 환경에서는 FedAvg, 현실적 큐잉 조건에서는 FedAvg, FedAsync, FedBuff, FedCompass를 평가하여, 이질적 스케줄러와 메모리 제약이 알고리즘 성능에 미치는 영향 분석.
- 과학적 검증: SMolInstruct 화학 명령 튜닝 데이터셋(3.3M 샘플)에서 Llama2-7B를 연합 미세조정하여 크로스-HPC 시설 FL이 대규모 과학 모델 개발을 지원함을 입증.