Essence

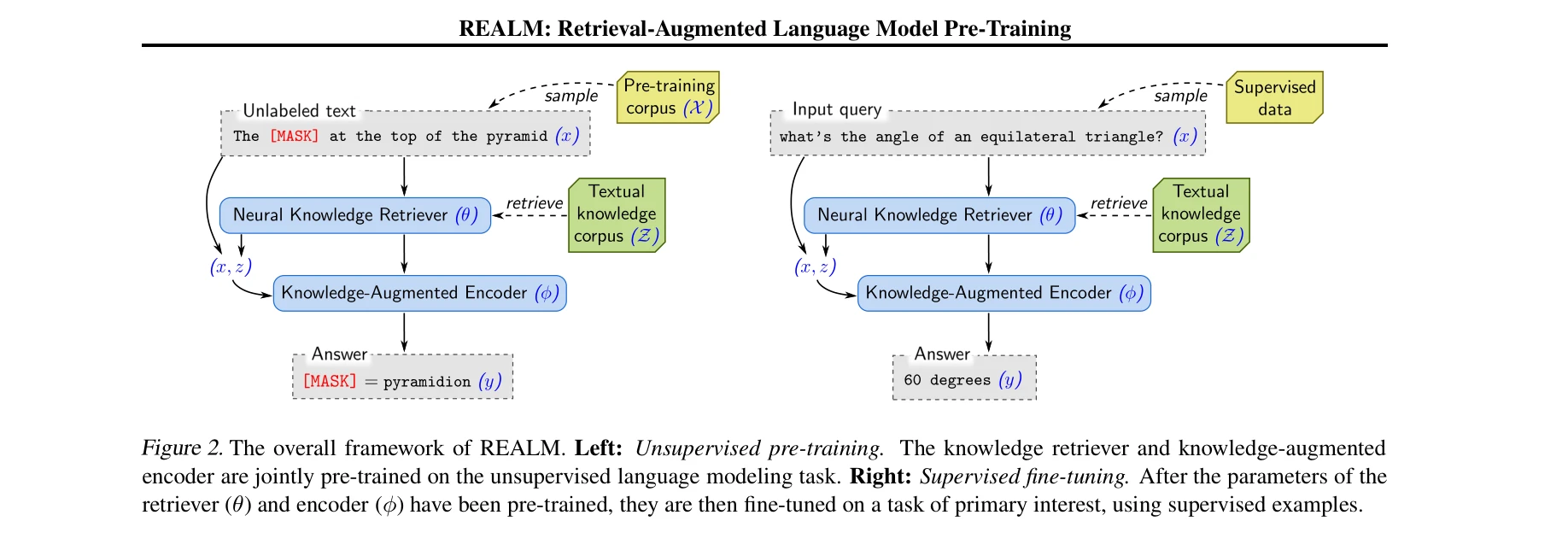
REALM은 언어 모델 사전학습에 신경망 기반 지식 검색기(neural knowledge retriever)를 통합하여, 백엔드에서 수백만 개의 문서를 고려하는 검색 단계를 통해 학습 신호를 역전파한다.
REALM은 지식을 신경망 파라미터에 암묵적으로 저장하는 대신, 학습 가능한 텍스트 검색 모듈을 통해 명시적으로 외부 코퍼스(예: Wikipedia)에서 관련 문서를 동적으로 검색하고 활용하는 검색증강 언어 모델 사전학습 프레임워크다. 비지도 마스크된 언어 모델(MLM) 목표 신호를 통해 검색기를 end-to-end로 학습할 수 있다.
Evaluation
Novelty: 5/5 Technical Soundness: 4/5 Significance: 5/5 Clarity: 4/5 Overall: 4.5/5
총평: REALM은 검색 메커니즘을 신경망 사전학습 단계에 최초로 통합하여 규모 있는 비지도 학습을 달성한 획기적 연구다. 명시적 지식 접근을 통해 해석 가능성과 모듈화를 확보하면서도 Open-QA에서 기존 모든 방법을 능가하는 성능을 보여줬다. 다만 대규모 검색의 계산 비용 및 문서 표현 업데이트의 지연성은 실무 적용 시 고려할 점이며, 향후 더 정교한 retrieval 전략과의 결합으로 한계를 극복할 여지가 있다.