Achievement
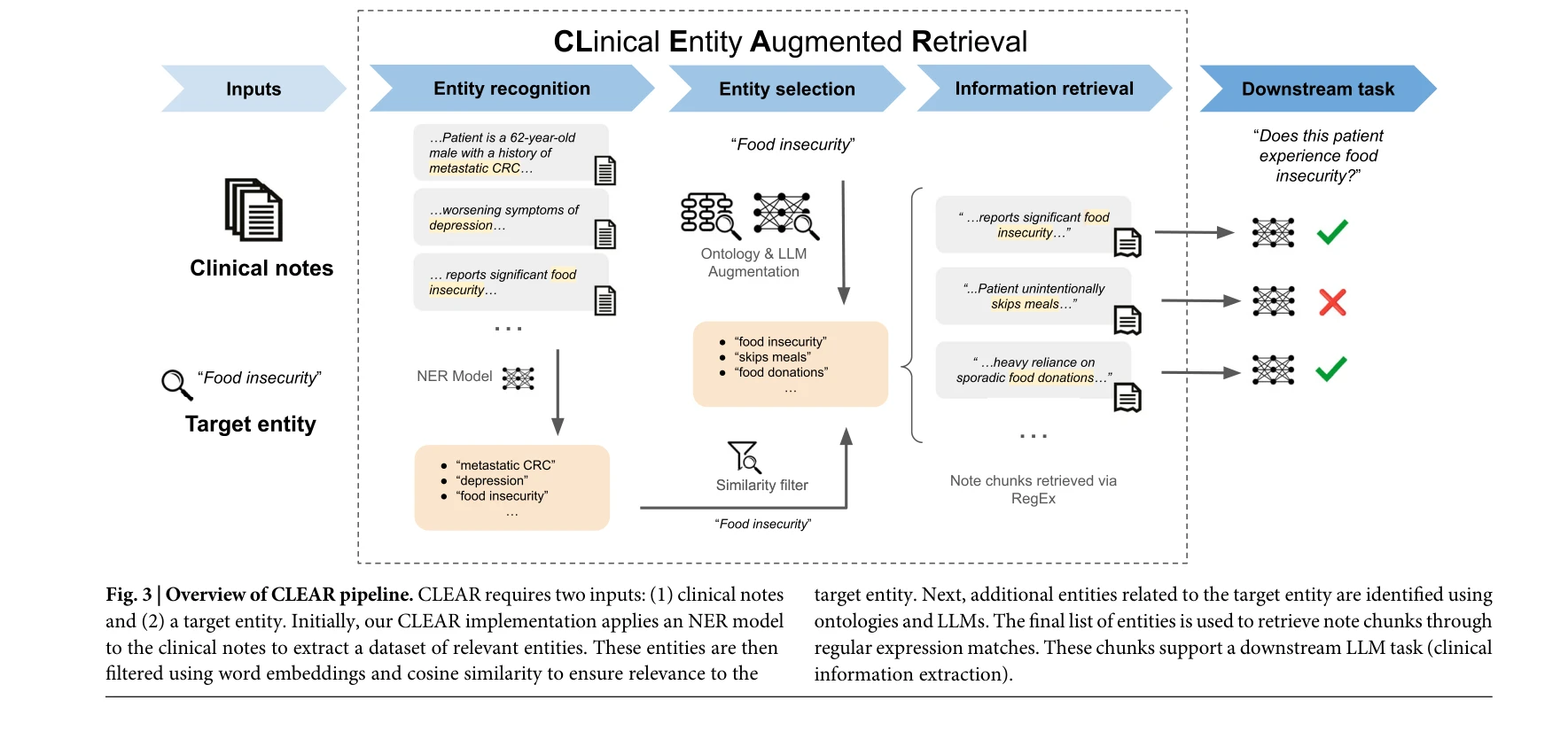
CLEAR 파이프라인의 개요: (1) 임상 노트와 (2) 쿼리를 입력받아 엔티티 기반 검색을 수행
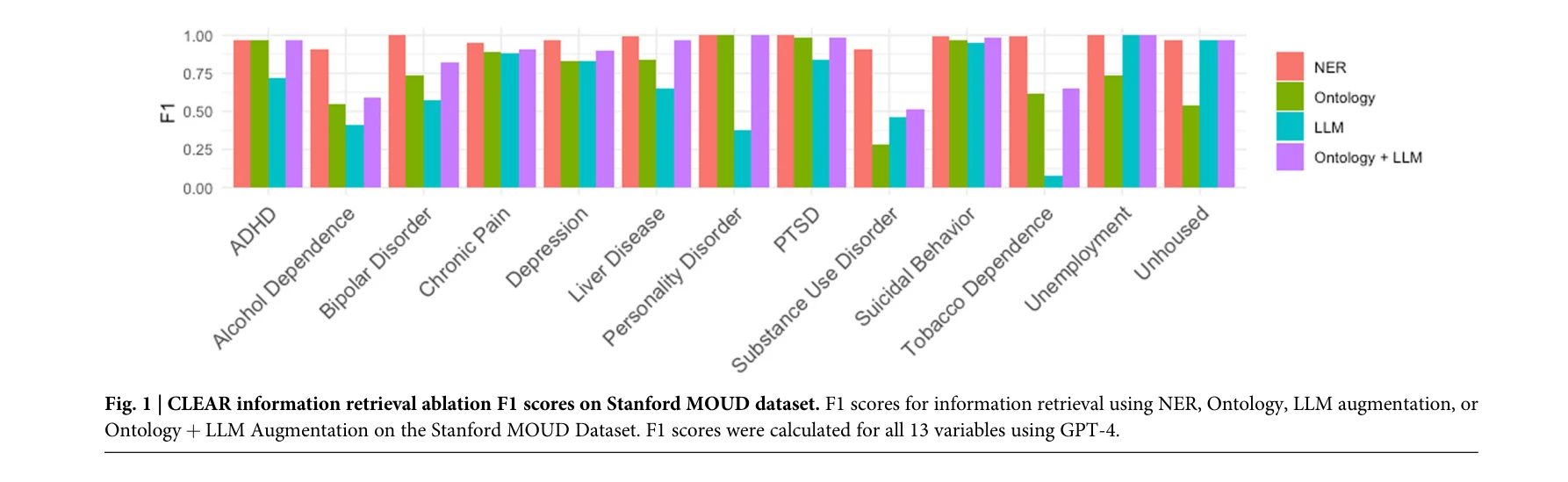
- 성능 우수성: Stanford MOUD 데이터셋에서 CLEAR의 평균 F1 점수는 0.90으로, embedding RAG(0.86)과 full-note(0.79) 접근법을 능가함. 6개 LLM 모두에서 CLEAR이 최고 또는 경쟁력 있는 성능 달성.
- 효율성 극대화:
- 추론 시간: CLEAR 4.95초 vs. embedding RAG 17.41초 vs. full-note 20.08초 (각 노트당)
- 모델 쿼리 횟수: CLEAR 1.68회 vs. embedding RAG 4.94회 vs. full-note 4.18회
- 평균 입력 토큰: CLEAR 1.1k vs. embedding RAG 3.8k vs. full-note 6.1k
- 전체적으로 70% 이상의 토큰 사용량 및 추론 시간 감소
- 다양한 임상 변수 검증: 물질 사용(alcohol dependence, tobacco dependence), 정신건강(ADHD, bipolar disorder, depression), 사회적 결정요인(homelessness, unemployment), 흉부 X-ray 소견(pneumonia, cardiomegaly) 등 18개 임상 변수에서 평가.
- BERT 모델 미세조정 가능성: CLEAR로 생성한 라벨로 Bio+Clinical BERT 모델을 미세조정했을 때, 알코올 의존성과 만성 통증에서 LLM trainer 모델의 F1 점수를 초과하는 성능 달성.