Essence
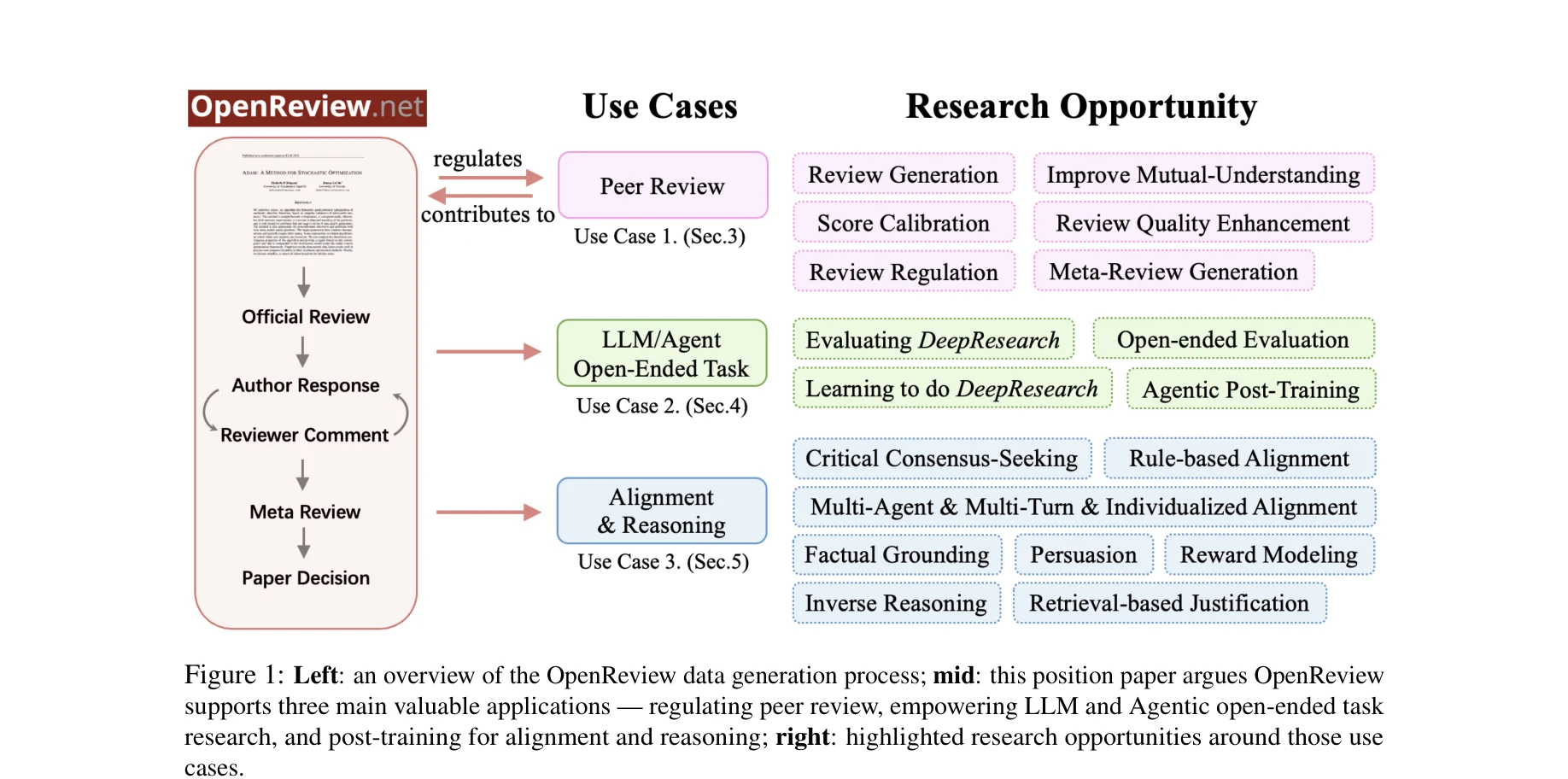
OpenReview 데이터 생성 과정(좌), 피어리뷰 규제, LLM 오픈-엔디드 작업 연구, 정렬 및 추론 후훈련을 지원하는 세 가지 주요 응용 분야(중), 연구 기회(우)
대규모 언어모델(LLM) 시대에 OpenReview 플랫폼—논문, 리뷰, 저자 반박, 메타리뷰, 최종 결정을 포함한 구조화된 전문가 피드백 저장소—을 학술 공동체의 핵심 자산으로 보호하고 활용해야 함을 주장하는 입장 논문이다.
저자: Hao Sun, Yunyi Shen, Mihaela van der Schaar | 날짜: 2025 | DOI: 10.48550/arXiv.2505.21537
OpenReview 데이터 생성 과정(좌), 피어리뷰 규제, LLM 오픈-엔디드 작업 연구, 정렬 및 추론 후훈련을 지원하는 세 가지 주요 응용 분야(중), 연구 기회(우)
대규모 언어모델(LLM) 시대에 OpenReview 플랫폼—논문, 리뷰, 저자 반박, 메타리뷰, 최종 결정을 포함한 구조화된 전문가 피드백 저장소—을 학술 공동체의 핵심 자산으로 보호하고 활용해야 함을 주장하는 입장 논문이다.
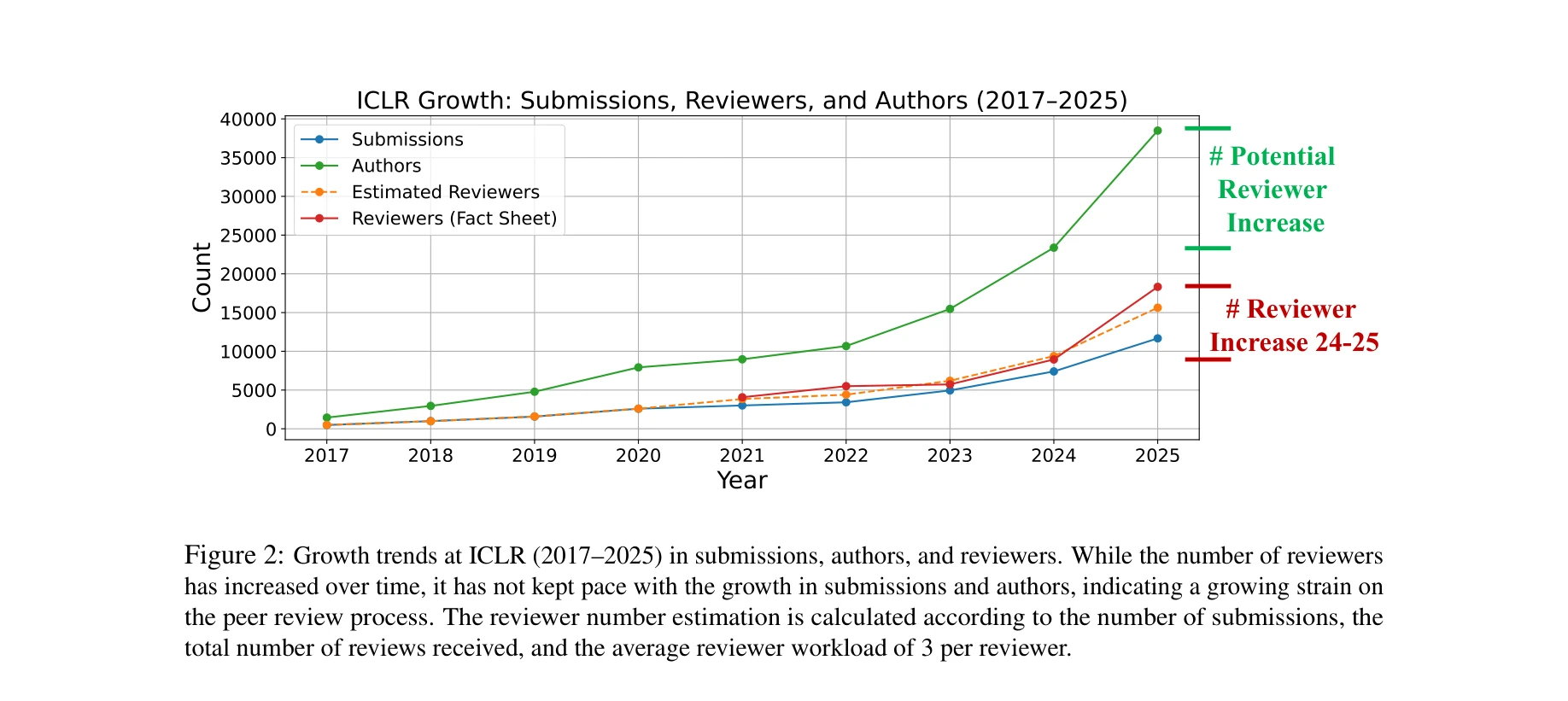
ICLR (2017–2025) 성장 추세: 투고 수는 500→11,600, 저자는 1,500→38,500, 리뷰어는 1,000→18,300으로 증가했으나 리뷰어 증가가 투고 증가를 따라가지 못함
총평: 학술 공동체의 피어리뷰 데이터를 LLM 시대의 핵심 자산으로 재조명한 중요한 입장 논문이나, 윤리적 고려사항과 구현 세부사항이 보강되어야 완전한 실행 가능성을 확보할 수 있다. 특히 OpenReview 보호와 공동체적 관리 방식에 대한 구체적 제안이 후속 작업에서 필요하다.