Essence

arXiv 초록 페이지에서 추출한 메타데이터 요소
본 논문은 arXiv 플랫폼에서 철회된 14,000개 이상의 논문을 수집한 첫 대규모 철회 연구 데이터셋(WithdrawArXiv)을 제시하며, 철회 이유를 10가지 범주로 분류하는 자동 분류 체계를 개발했다.
저자: Delip Rao, Jonathan Young, Thomas G. Dietterich, Chris Callison-Burch | 날짜: 2024 | DOI: [미공개]
arXiv 초록 페이지에서 추출한 메타데이터 요소
본 논문은 arXiv 플랫폼에서 철회된 14,000개 이상의 논문을 수집한 첫 대규모 철회 연구 데이터셋(WithdrawArXiv)을 제시하며, 철회 이유를 10가지 범주로 분류하는 자동 분류 체계를 개발했다.
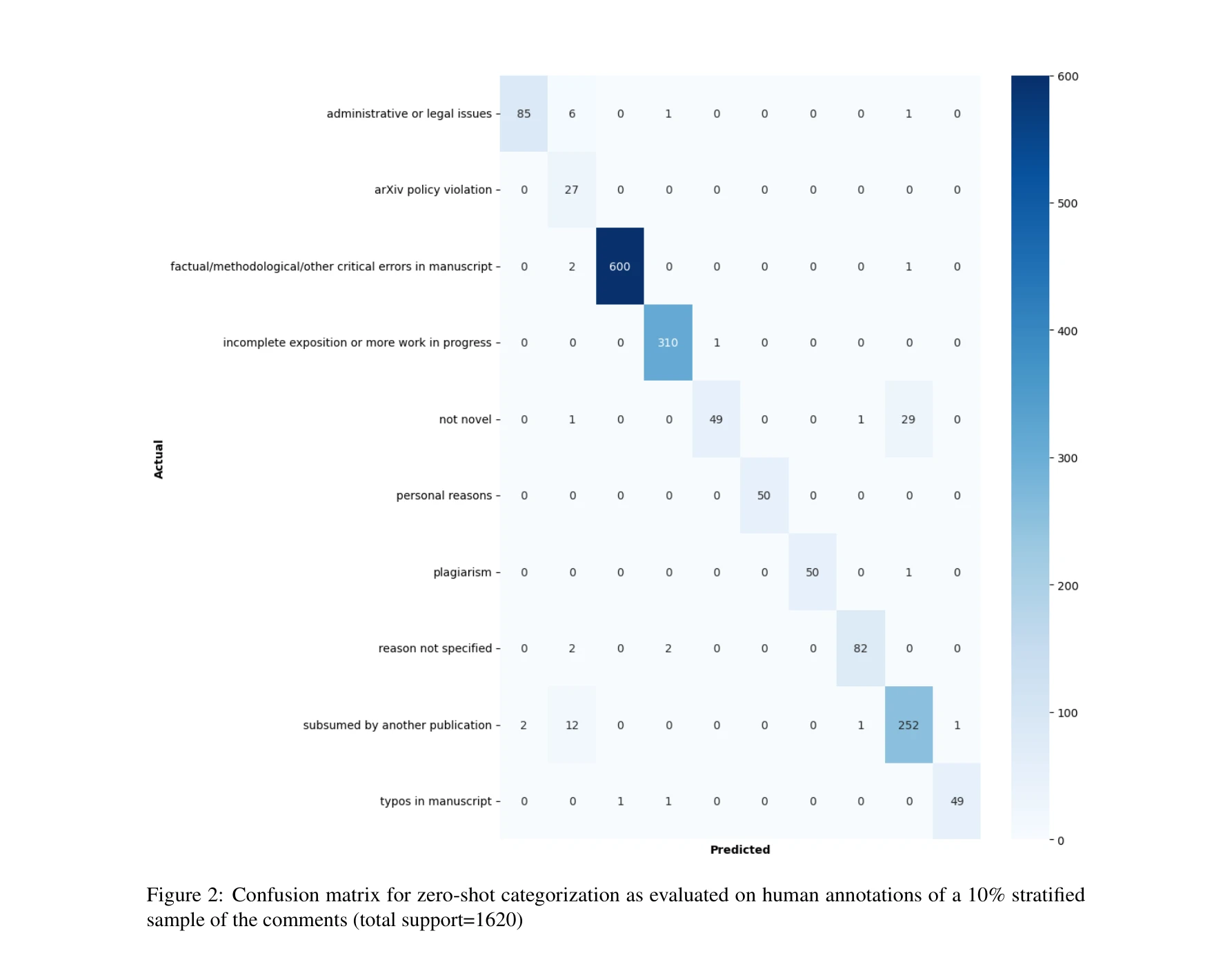
수동 주석 10% 계층화 샘플(총 1,620개)에서 평가한 제로샷 분류 혼동 행렬
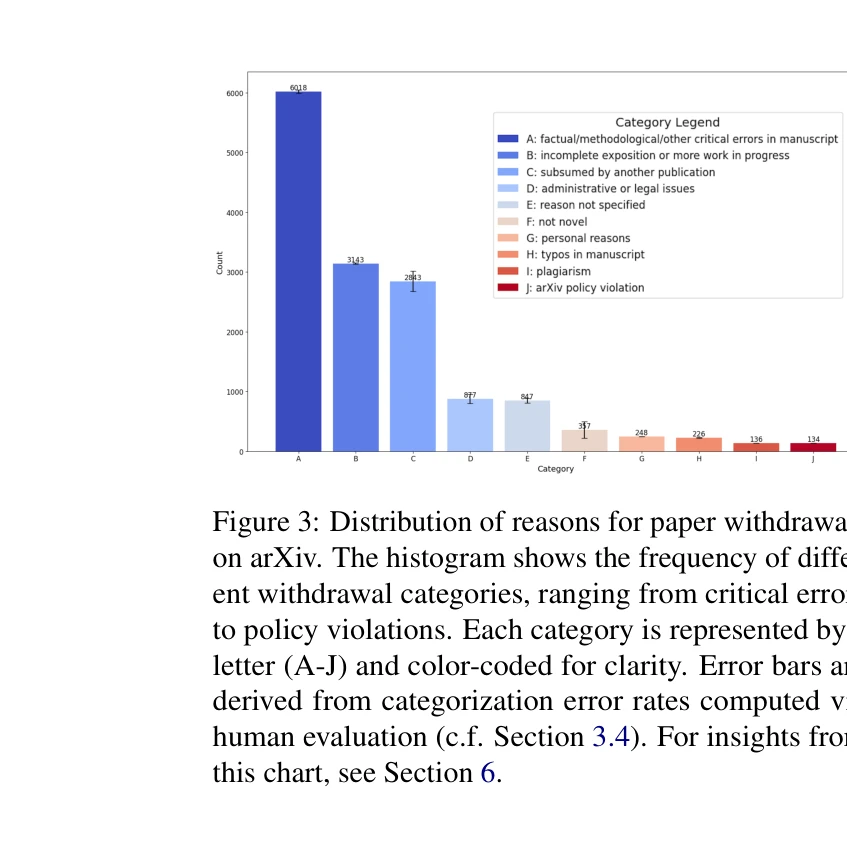
논문 철회 사유의 분포
총평: 이 논문은 STEM 분야에서 처음으로 대규모 논문 철회 데이터셋을 제시하고 실용적 자동화 방법론을 제공하여 과학 무결성 연구에 중요한 기여를 하고 있으나, 단일 플랫폼 한정과 분류 세분화 미흡이라는 제한사항이 있다.