Achievement
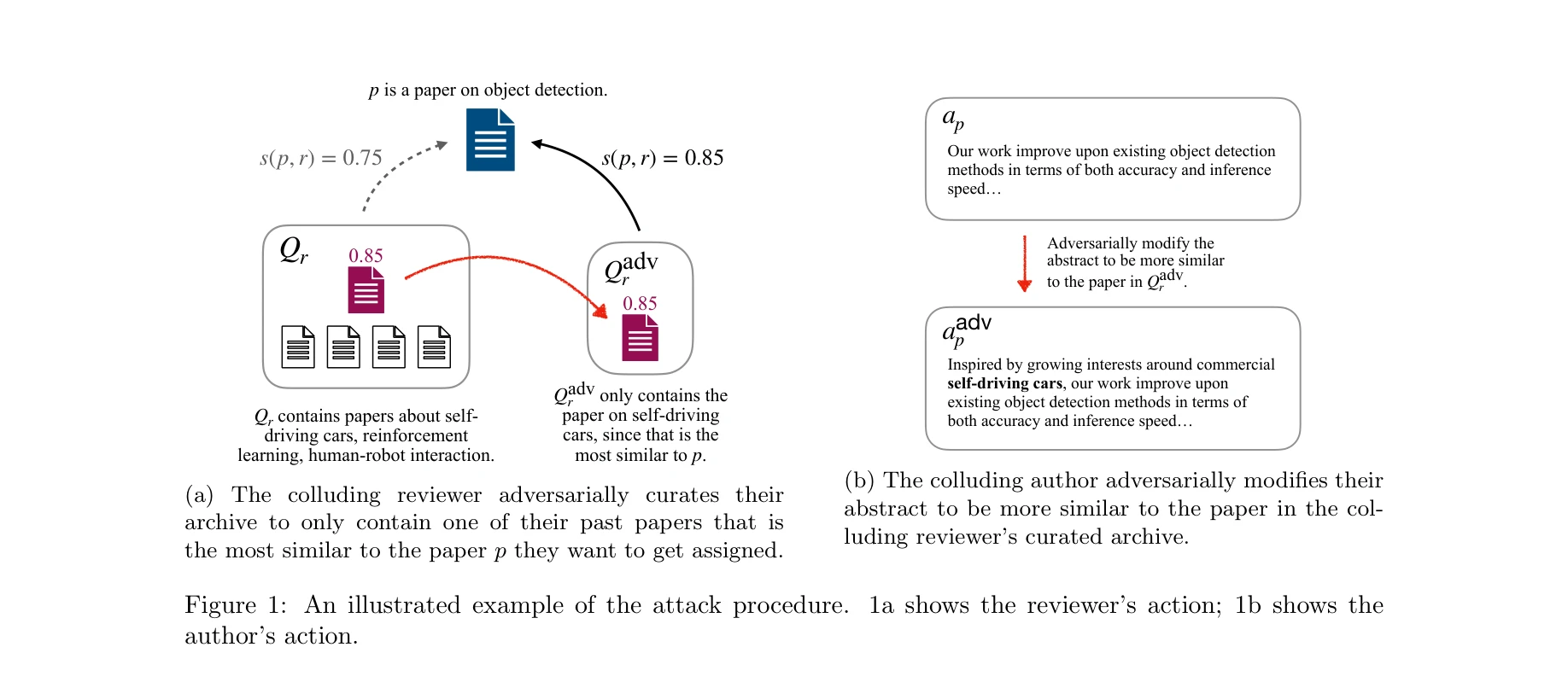
담합하는 저자와 심사위원의 협력 공격 메커니즘 illustration
- SPECTER 알고리즘의 취약성 입증: NeurIPS 2023 데이터에서 제안 공격이 92% 성공률로 심사위원 순위를 101위→상위5위로 상향. 최대값 풀링(max pooling) 사용 시 더욱 취약(49% vs. 평균값 32%).
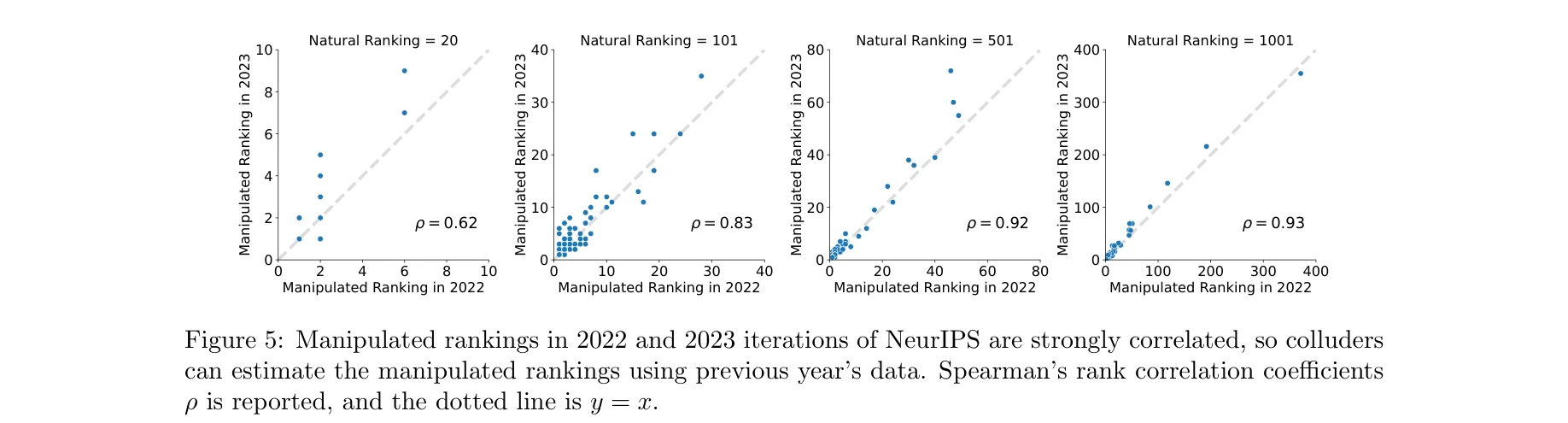
- 크로스 연도 예측 가능성: NeurIPS 2022(공개 데이터)와 2023(미공개 데이터) 간 유사도 순위의 강한 상관관계(r=0.62~0.93) 발견. 공격자가 과거 데이터로 성공 가능성 사전 평가 가능.
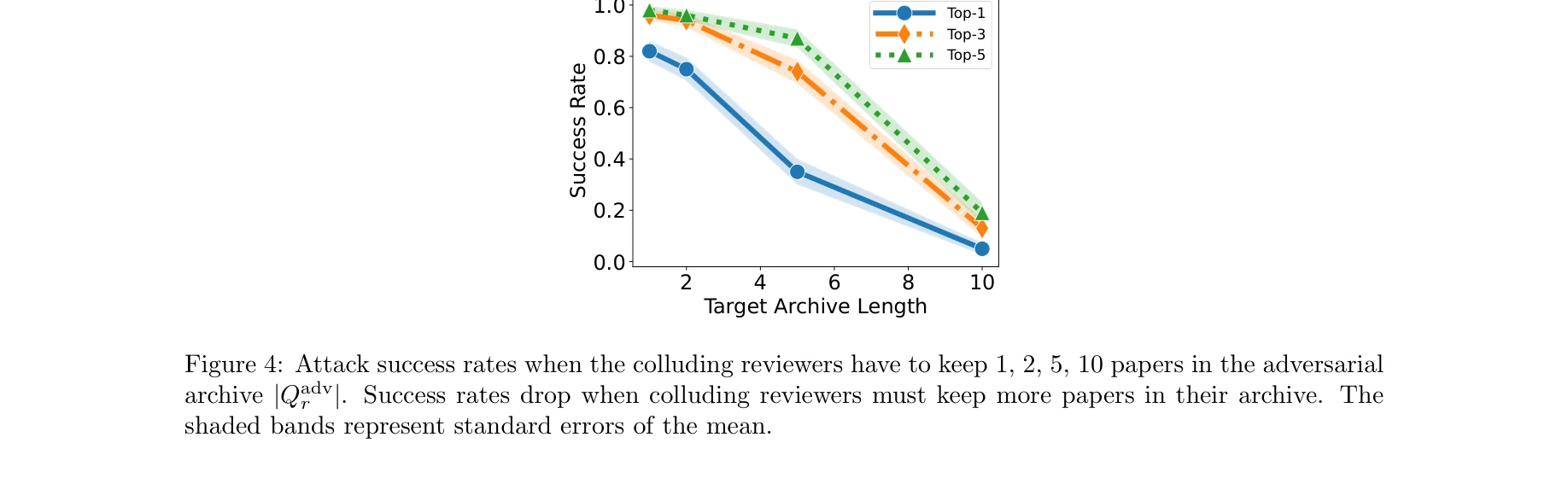
- 프로필 선별 기반 공격: 심사위원이 자신의 과거 논문을 선택 가능한 경우, 단 1개의 가장 유사한 논문만 선택하면 추상 수정 없이도 41% 성공률 달성.
- 탐지 가능성의 이중성: 인간 피험자가 공격된 추상을 더 자주 지적(coherence/consistency 문제)하나, 정상 추상도 상당 비율 지적받음(plausible deniability 제공).