Essence
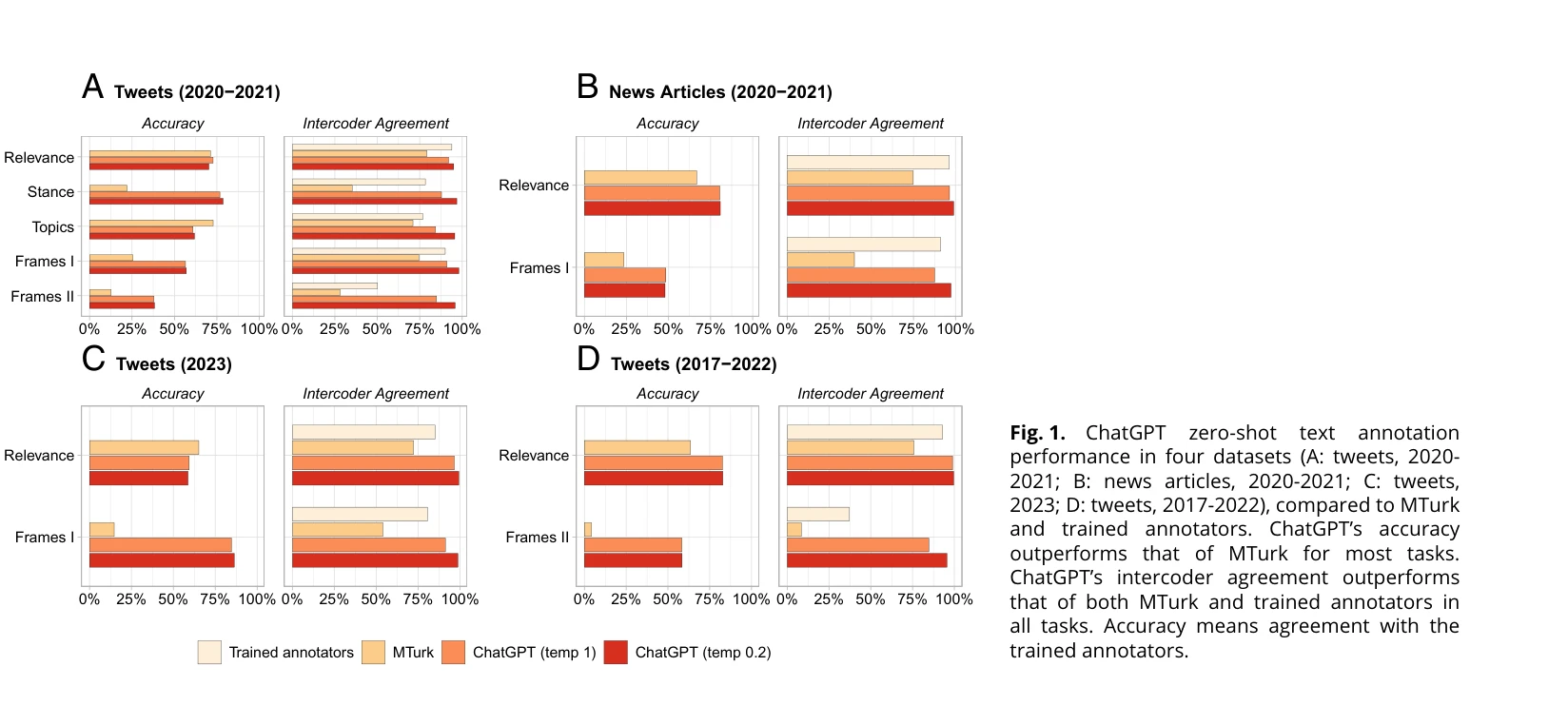
그림 1: 네 가지 데이터셋에서 ChatGPT의 영점 샷(zero-shot) 텍스트 주석 성능 비교. ChatGPT의 정확도(accuracy)는 대부분의 작업에서 MTurk를 능가하며, 모든 작업에서 코더 간 합의도(intercoder agreement)가 MTurk와 훈련된 주석자를 초과함.
ChatGPT는 텍스트 주석 작업에서 크라우드 워커(crowd workers)를 평균 25 percentage point 초과하는 정확도로 능가하며, 훈련된 주석자 수준의 코더 간 합의도를 달성하면서도 MTurk 대비 약 30배 저렴한 비용으로 수행 가능함을 입증하는 연구이다.