Essence
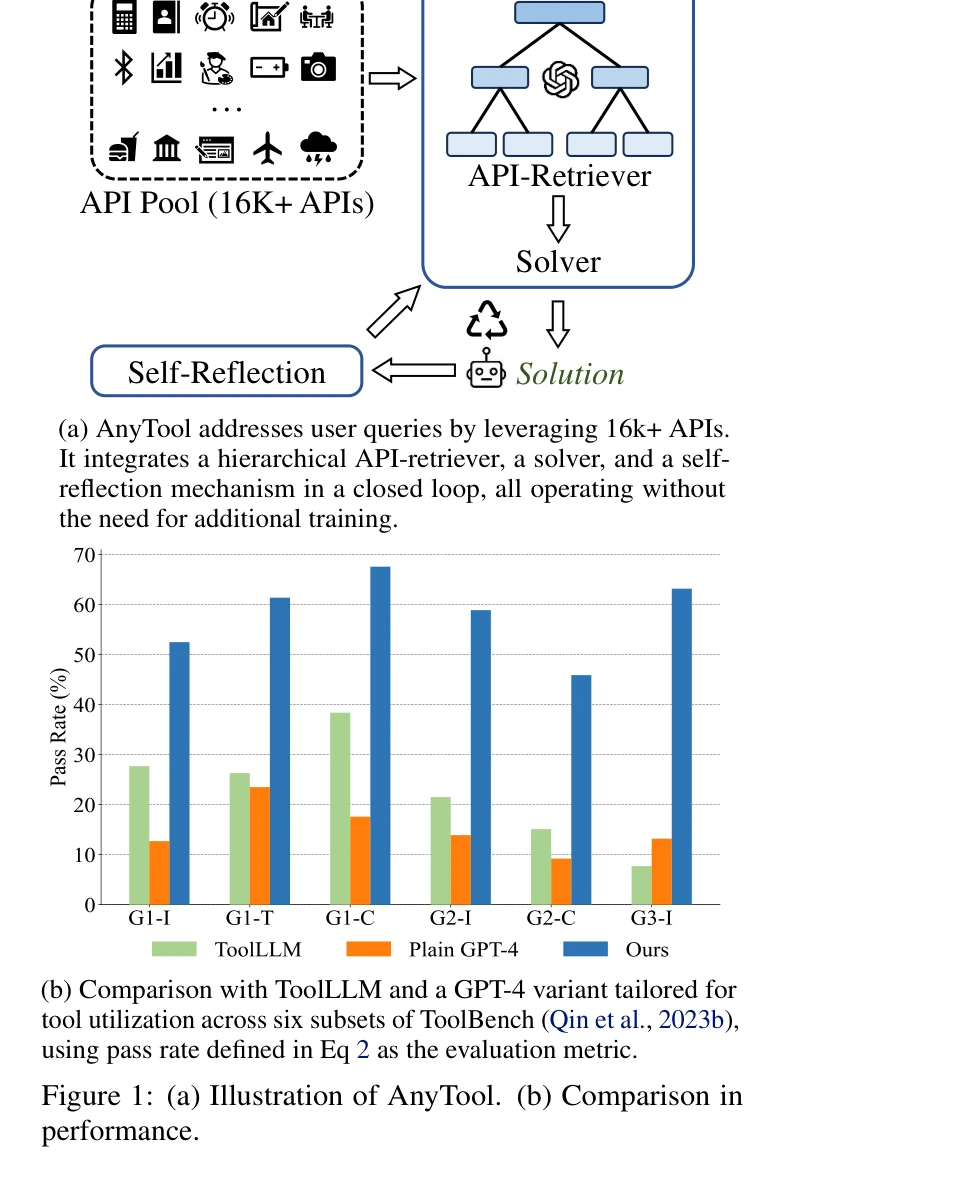
AnyTool의 구조 및 ToolLLM과의 성능 비교
16,000개 이상의 API를 활용하여 사용자 쿼리를 해결하는 GPT-4 기반 에이전트로, 계층적 API 검색기, 문제 해결기, 자기 반성 메커니즘을 통합하여 기존 방식 대비 35.4% 향상된 성능을 달성했다.
저자: Yu Du, Fangyun Wei, Hongyang Zhang | 날짜: 2024-02-06 | DOI: 10.48550/arXiv.2402.04253
AnyTool의 구조 및 ToolLLM과의 성능 비교
16,000개 이상의 API를 활용하여 사용자 쿼리를 해결하는 GPT-4 기반 에이전트로, 계층적 API 검색기, 문제 해결기, 자기 반성 메커니즘을 통합하여 기존 방식 대비 35.4% 향상된 성능을 달성했다.
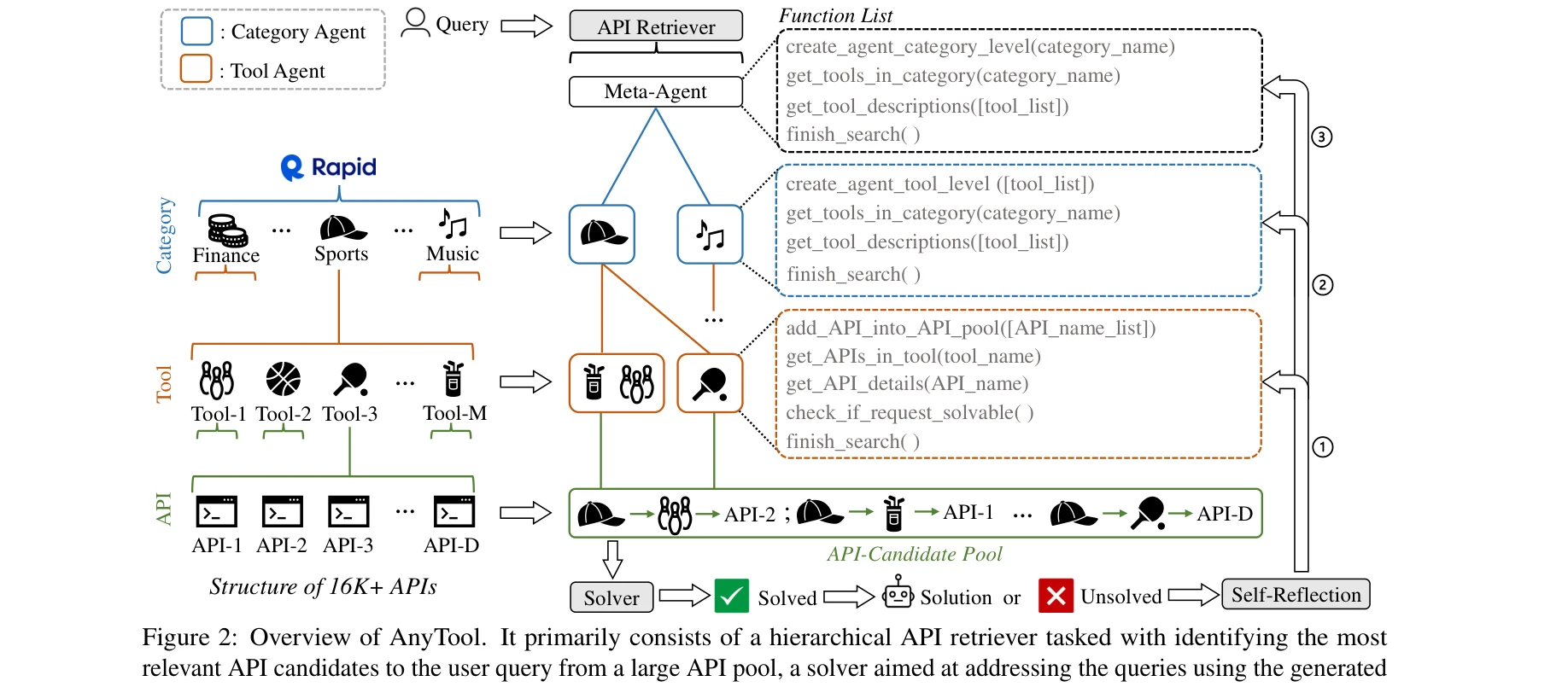
AnyTool의 전체 구조: 계층적 API 검색기, 솔버, 자기 반성 메커니즘
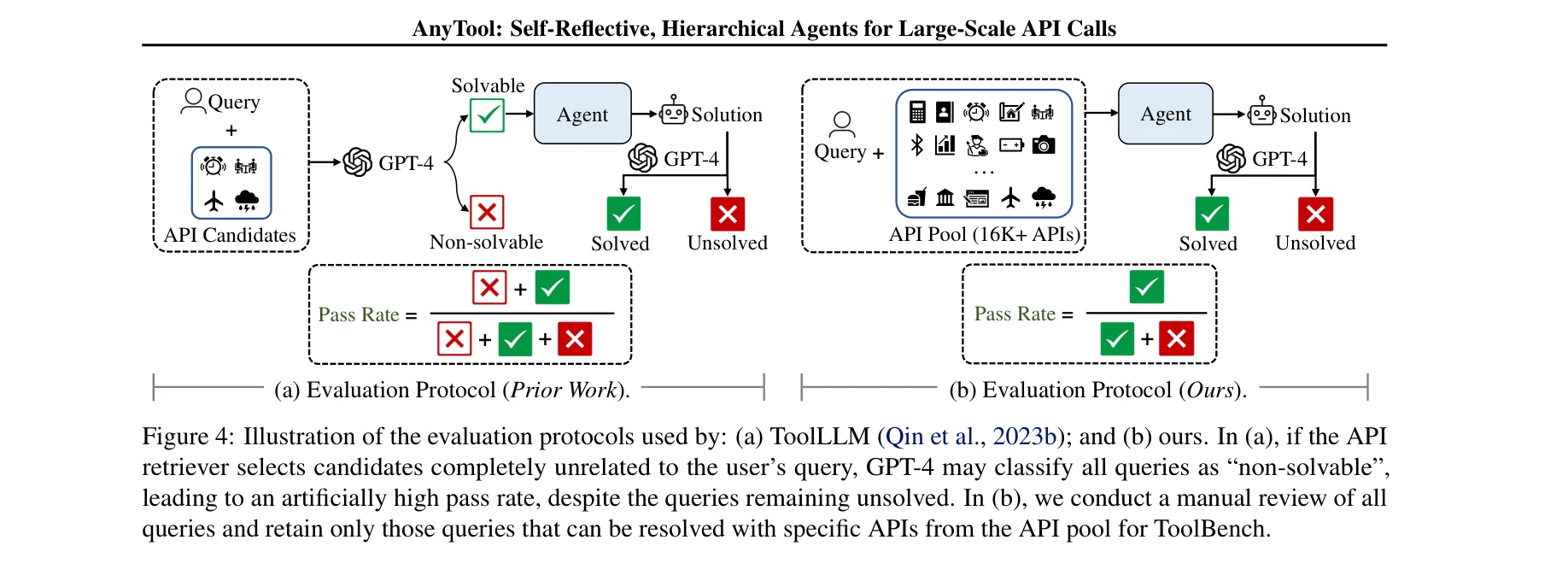
기존 평가 프로토콜의 결함과 개선된 평가 방식 비교
총평: AnyTool은 대규모 API 활용 문제에 대해 학습 불필요한 실용적 솔루션을 제공하며, 특히 자기 반성 메커니즘과 평가 프로토콜 개선으로 실제 응용 가치가 높은 논문이다. 다만 GPT-4 특화 설계와 더 광범위한 일반화 검증이 한계로 남는다.