Achievement
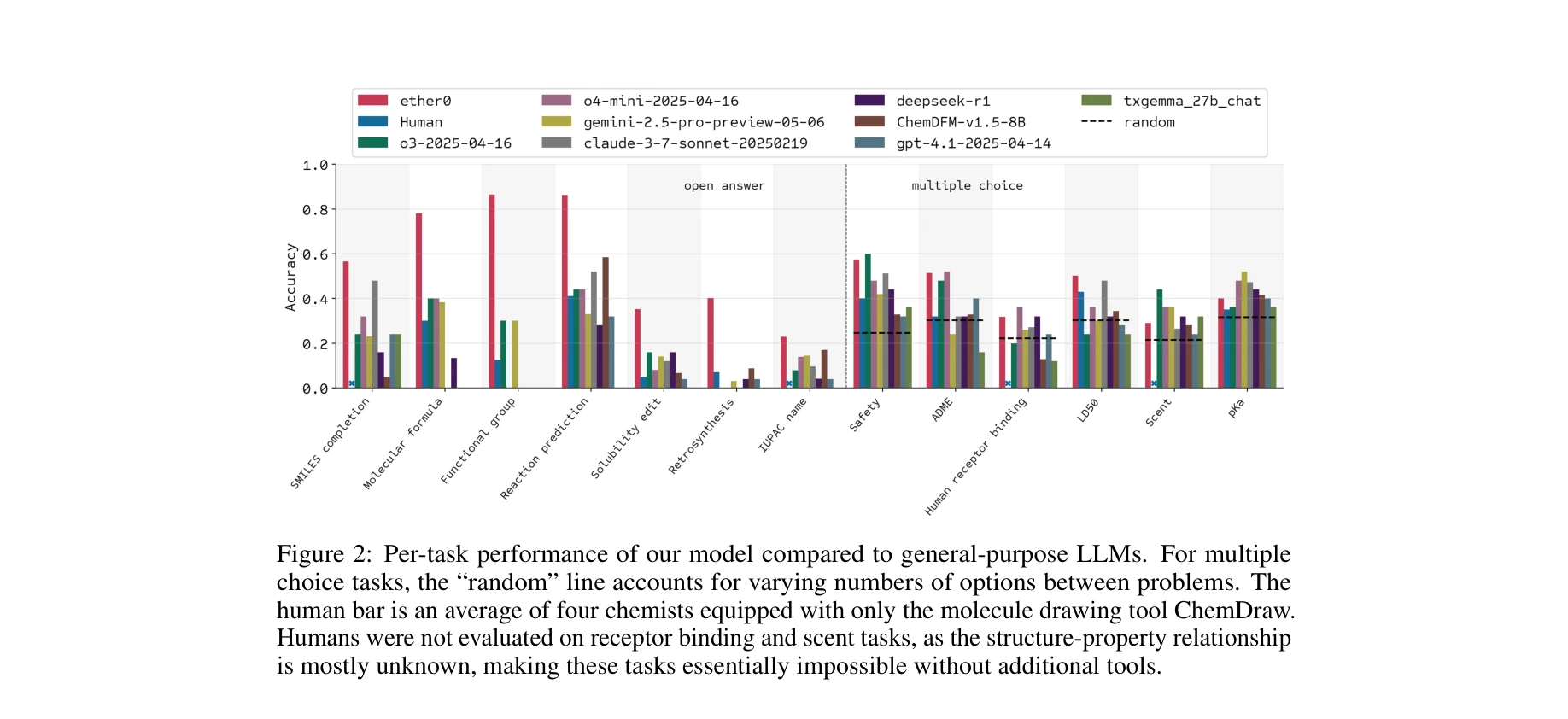
- 성능 우위: ether0는 GPT-4o, Llama 같은 최첨단 LLM, 일반 화학 모델, 인간 전문가를 분자 설계 작업에서 초과. 특히 retrosynthesis, solubility editing 등 복합 추론 작업에서 두드러짐.
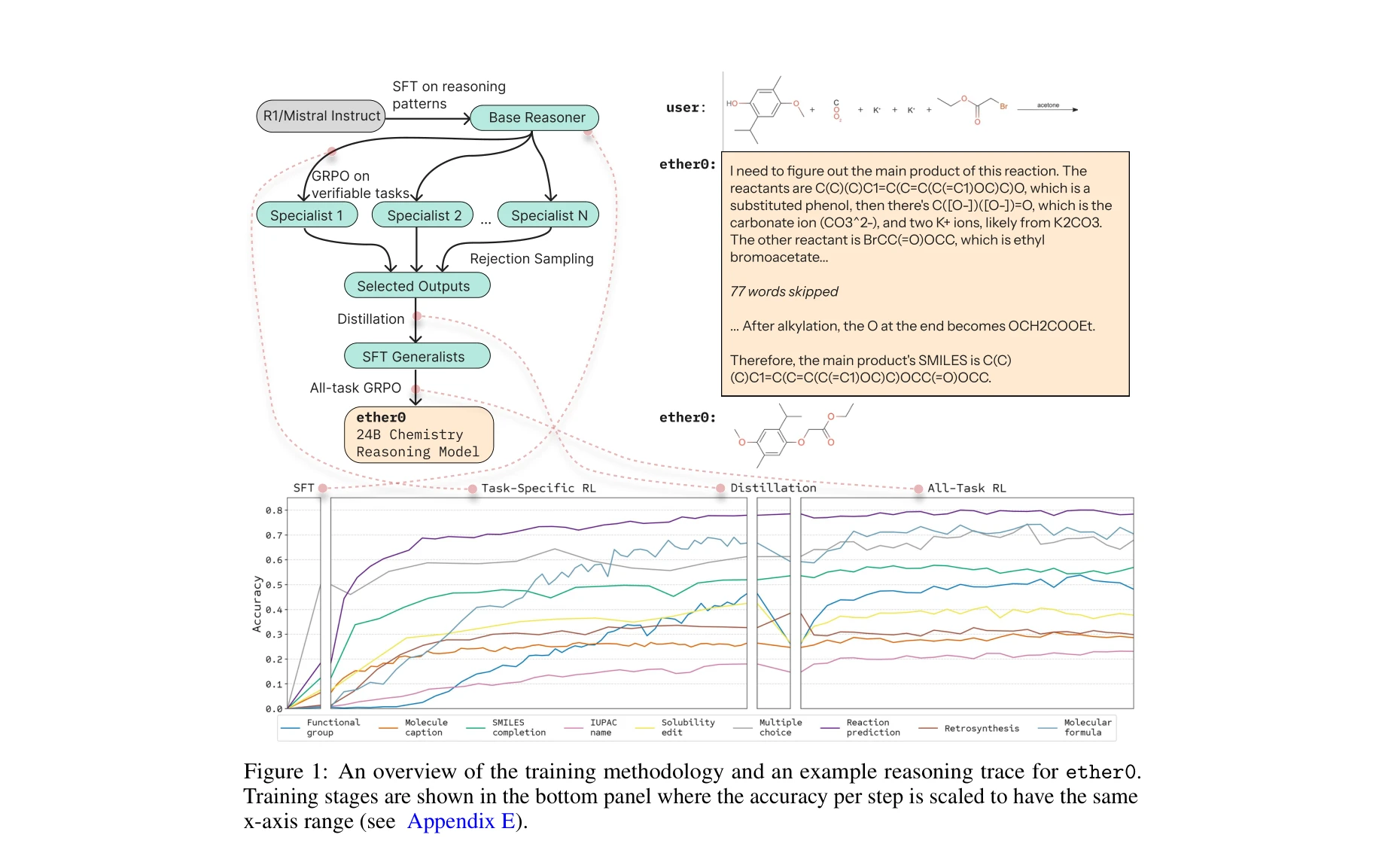
- 데이터 효율성: 전문화된 도메인 특화 모델(Molecular Transformer 등)과 비교해 월등히 적은 데이터로 더 나은 성능 달성. 이는 추론 모델의 일반성과 강화학습의 효율성을 입증.
- 약물 발견 파이프라인 통합: Hit discovery(후보 생성) → Hit-to-lead(효능/선택성 개선) → Lead optimization(효과 강화, 독성 감소, ADMET 개선)의 핵심 단계를 합성 가능성 제약 하에서 지원.
- 375개 작업의 다양성: 단순 구조 변환(IUPAC name, SMILES completion)부터 복합 특성 예측(혈뇌장벽 투과성, 수용체 결합, 냄새 특성)까지 포괄.