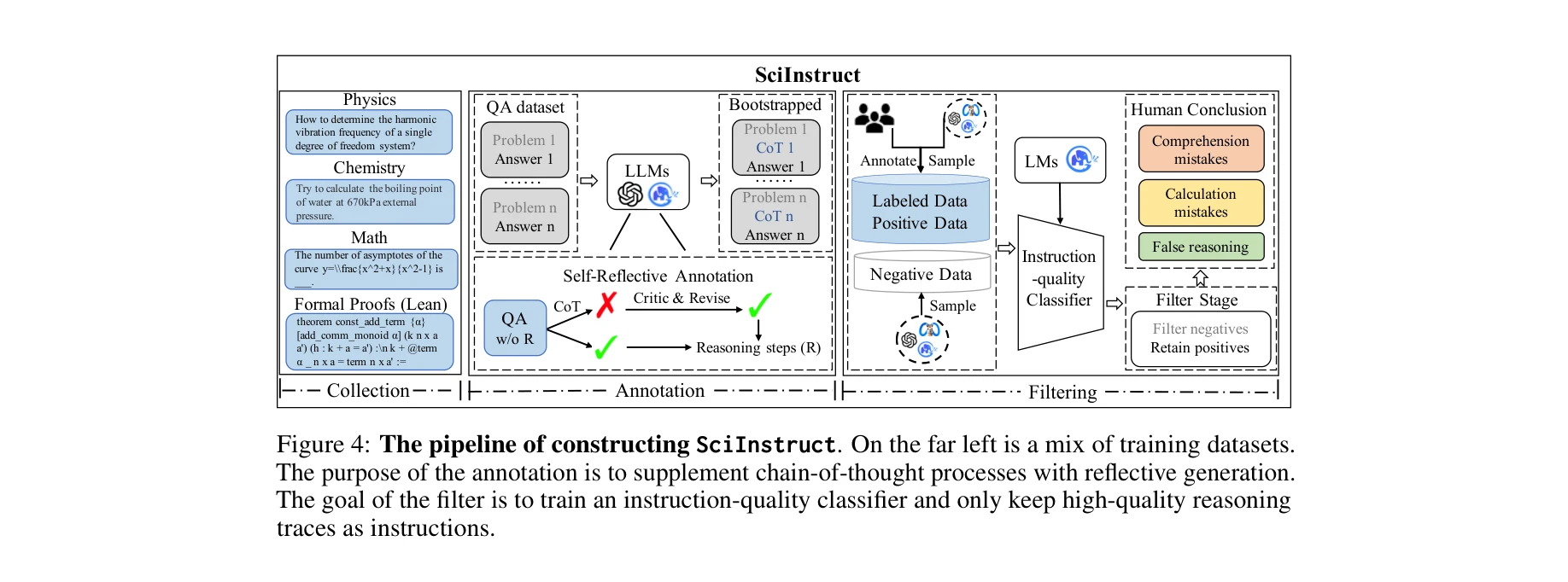
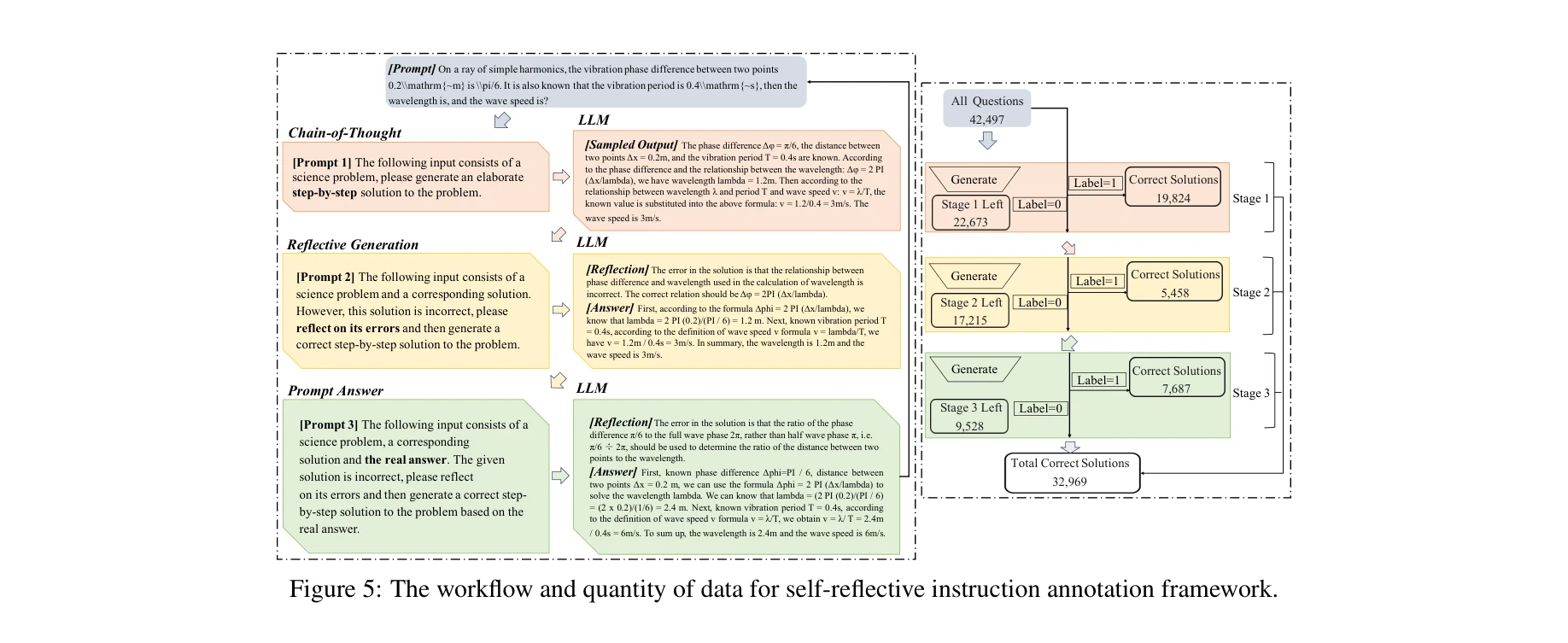
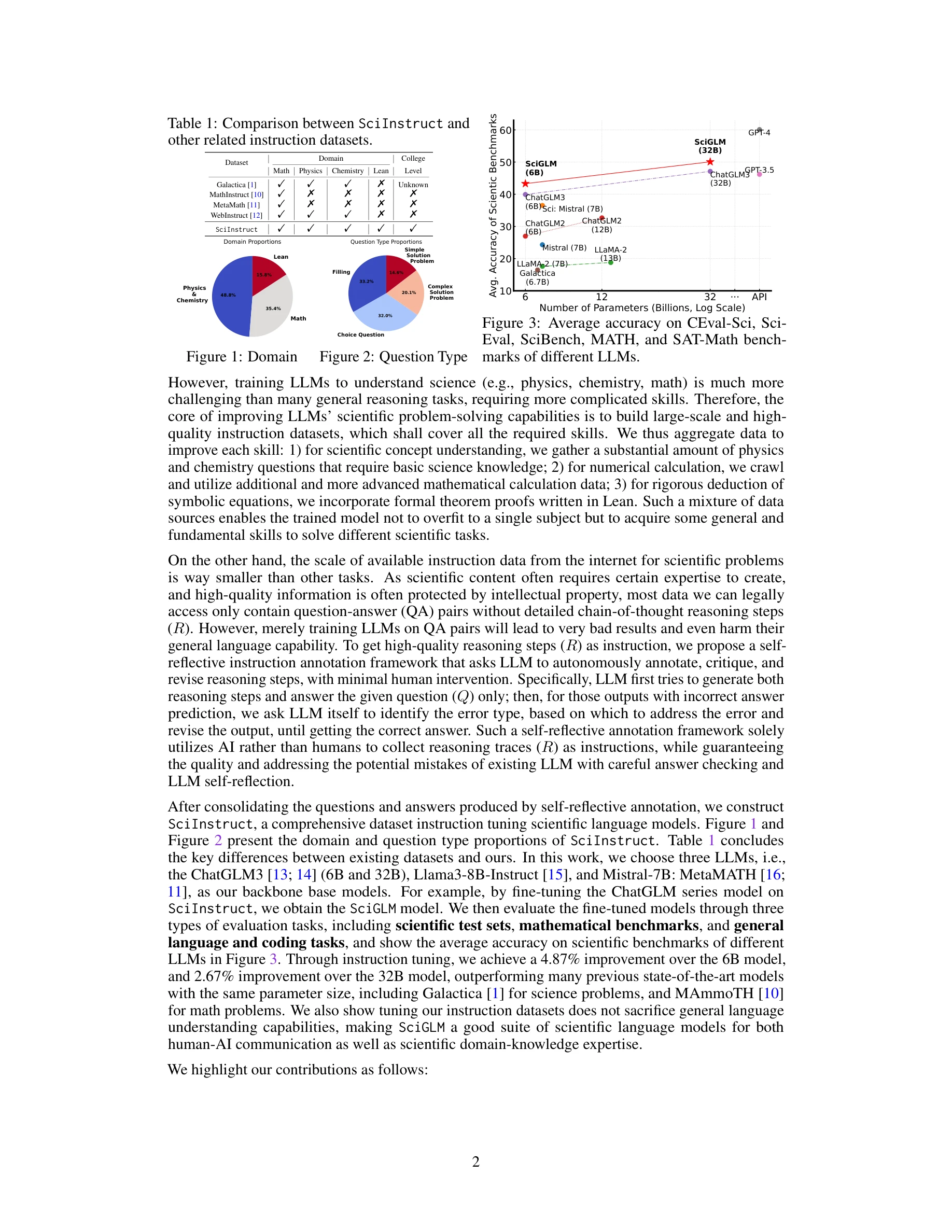
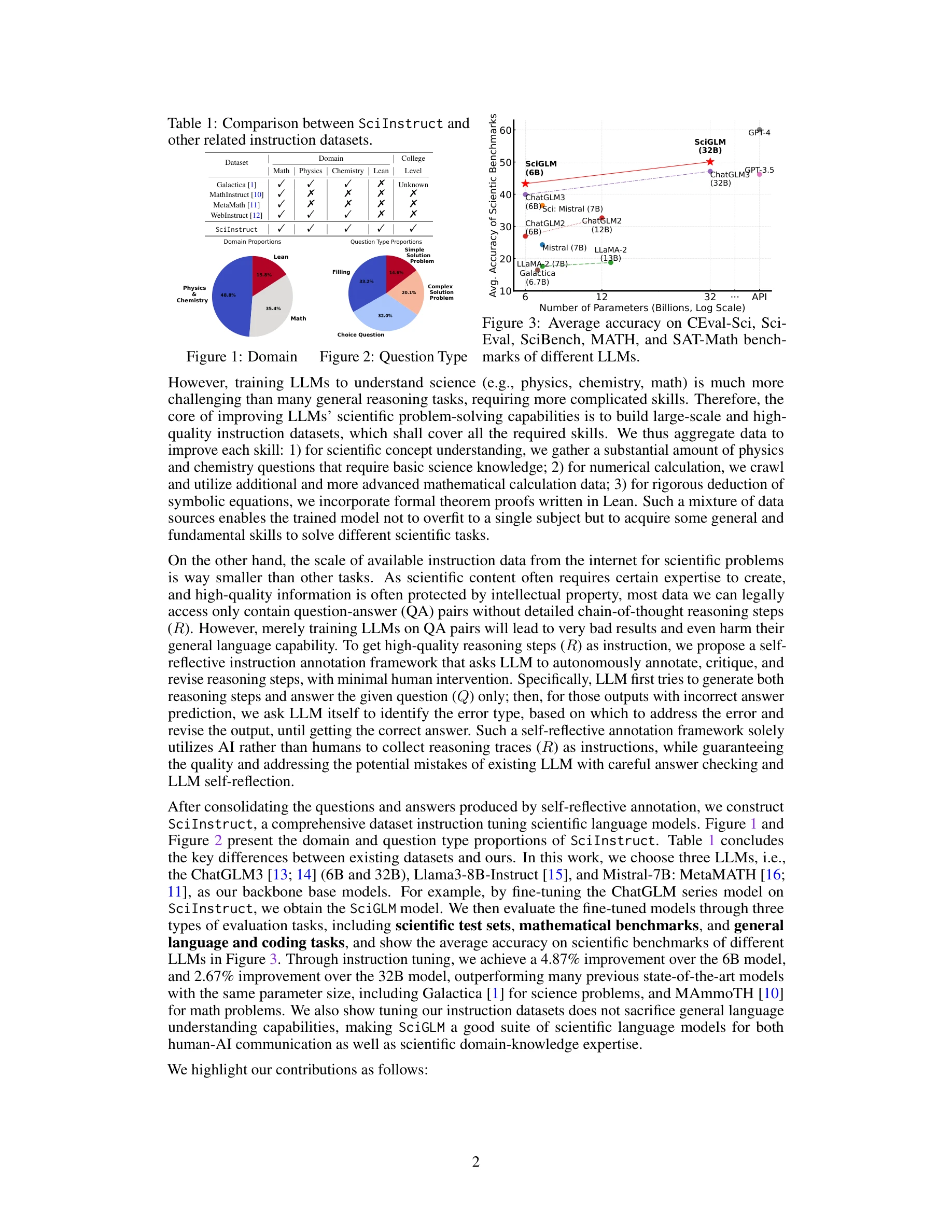
Essence
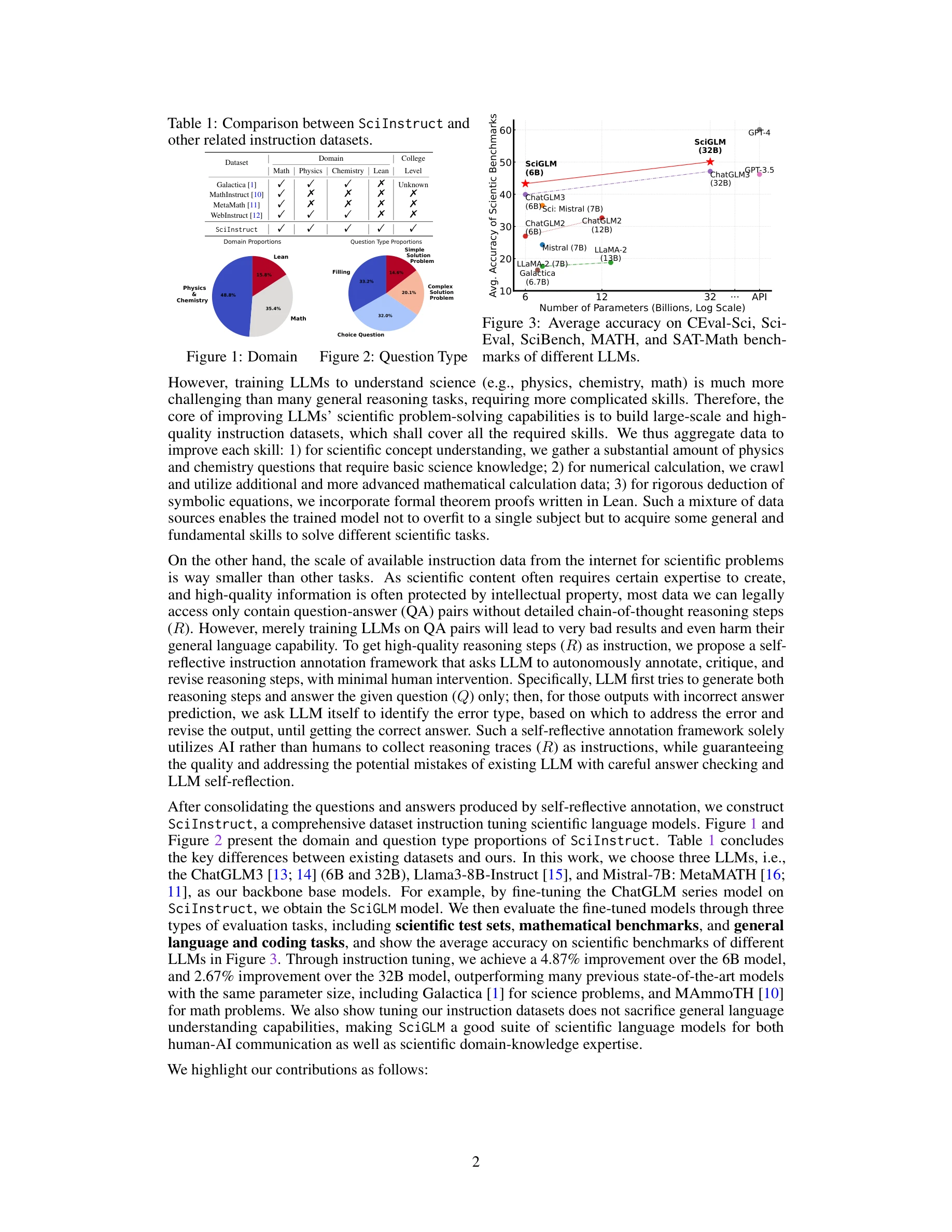
다양한 파라미터 크기의 LLM들에 대한 SciGLM의 성능 개선 효과
SciGLM은 자기 성찰적(self-reflective) 주석 생성 프레임워크를 통해 고품질의 과학 지시 데이터를 자동으로 큐레이션하고, 이를 이용해 여러 언어 모델을 파인튜닝함으로써 대학 수준의 과학 추론 능력을 갖춘 과학 언어 모델을 구축한다. GPT-3.5와 GPT-4 같은 고급 LLM도 기본적인 과학 문제에서 28.52%의 낮은 정확도를 보이는 문제를 해결하기 위해, 물리, 화학, 수학, 형식적 증명(Lean)을 포함하는 254,051개의 고품질 과학 지시문을 포함한 SciInstruct 데이터셋을 구축했다.