Essence
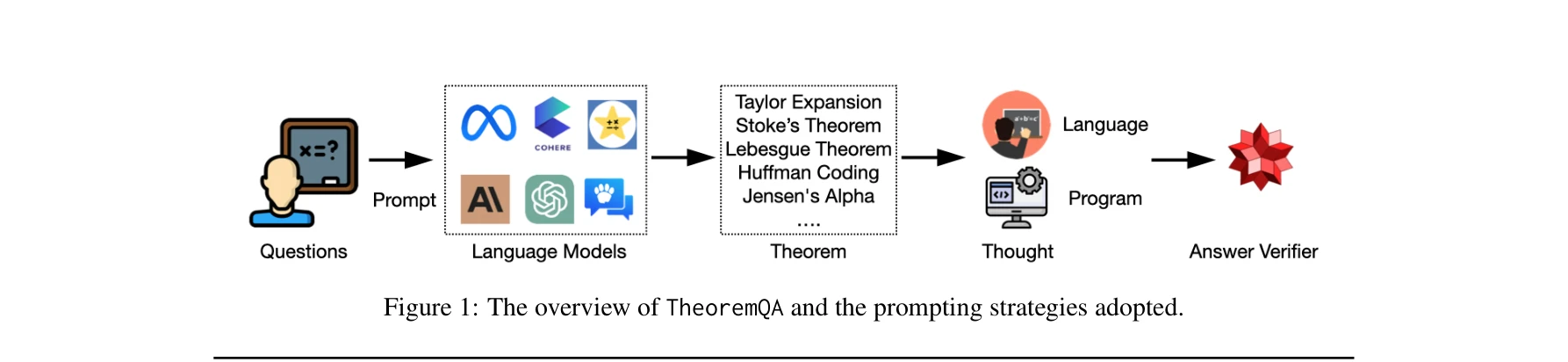
TheoremQA의 개요 및 적용된 프롬프팅 전략
대학 수준의 수학, 물리, 금융, 전산 분야에서 350개 이상의 정리(theorem)를 포함하는 800개의 고품질 질문-답변 쌍으로 구성된 정리 중심 질문 답변 데이터셋을 제시한다. 이는 LLM의 도메인 지식 적용 능력을 평가하는 첫 번째 벤치마크이다.
저자: Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, Tony Xia | 날짜: 2023 | DOI: N/A
TheoremQA의 개요 및 적용된 프롬프팅 전략
대학 수준의 수학, 물리, 금융, 전산 분야에서 350개 이상의 정리(theorem)를 포함하는 800개의 고품질 질문-답변 쌍으로 구성된 정리 중심 질문 답변 데이터셋을 제시한다. 이는 LLM의 도메인 지식 적용 능력을 평가하는 첫 번째 벤치마크이다.

TheoremQA의 예시. Stokes 정리를 이용한 적분 변환 문제

TheoremQA의 답변 타입 분포
데이터셋 구성 프로세스:
정리 통합 실험:
한계:
후속 연구 방향:
총평: TheoremQA는 LLM의 도메인 특화 지식 활용 능력을 체계적으로 평가하는 첫 번째 벤치마크로서 의미 있는 기여를 하며, 광범위한 모델 평가를 통해 현재의 성능 격차를 명확히 드러낸다. 다만 오픈소스 모델의 극히 낮은 성능은 평가의 변별력을 제한하고, 정리 통합 방식의 개선 여지가 크다는 점이 아쉽다.