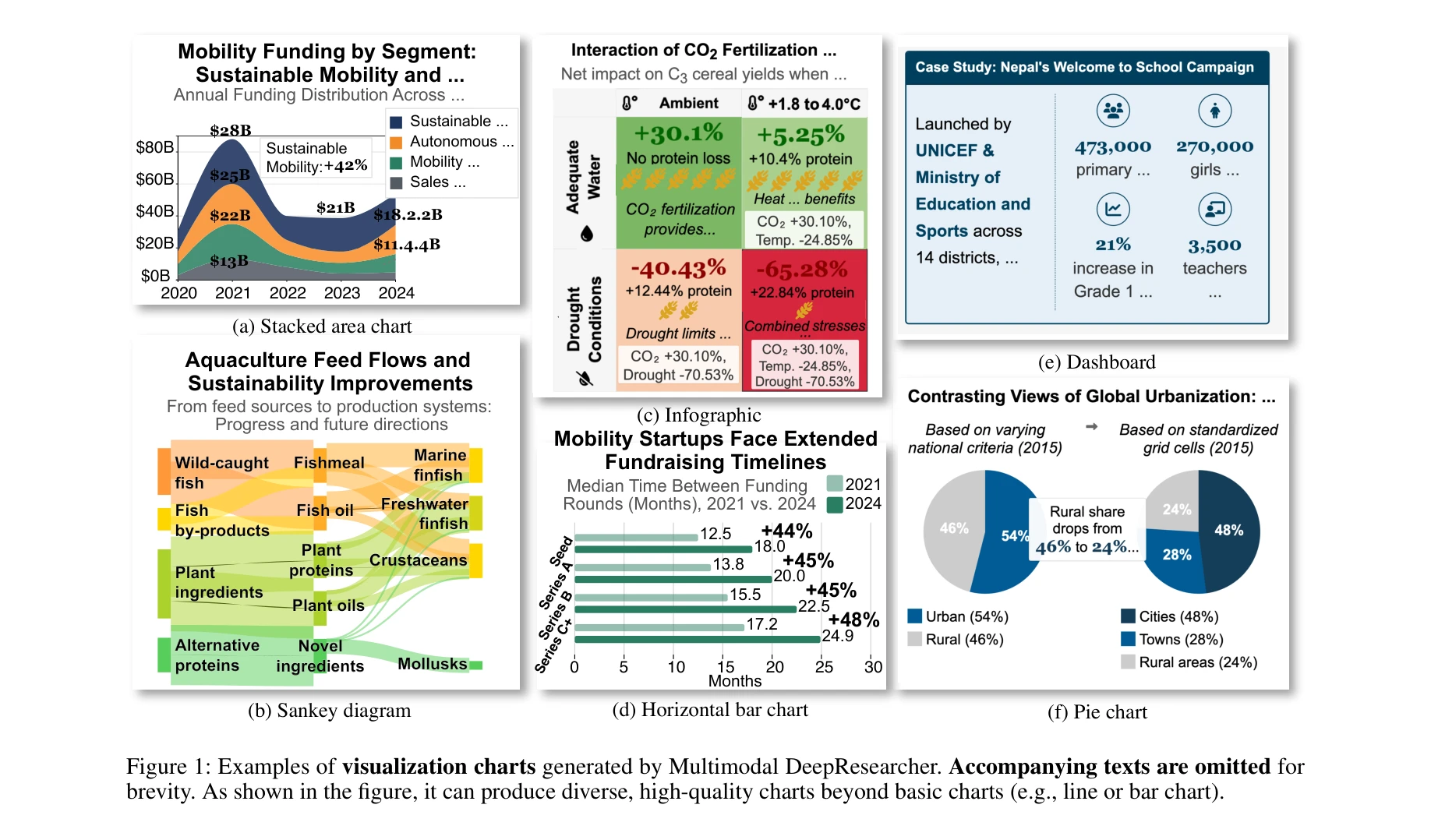
Essence
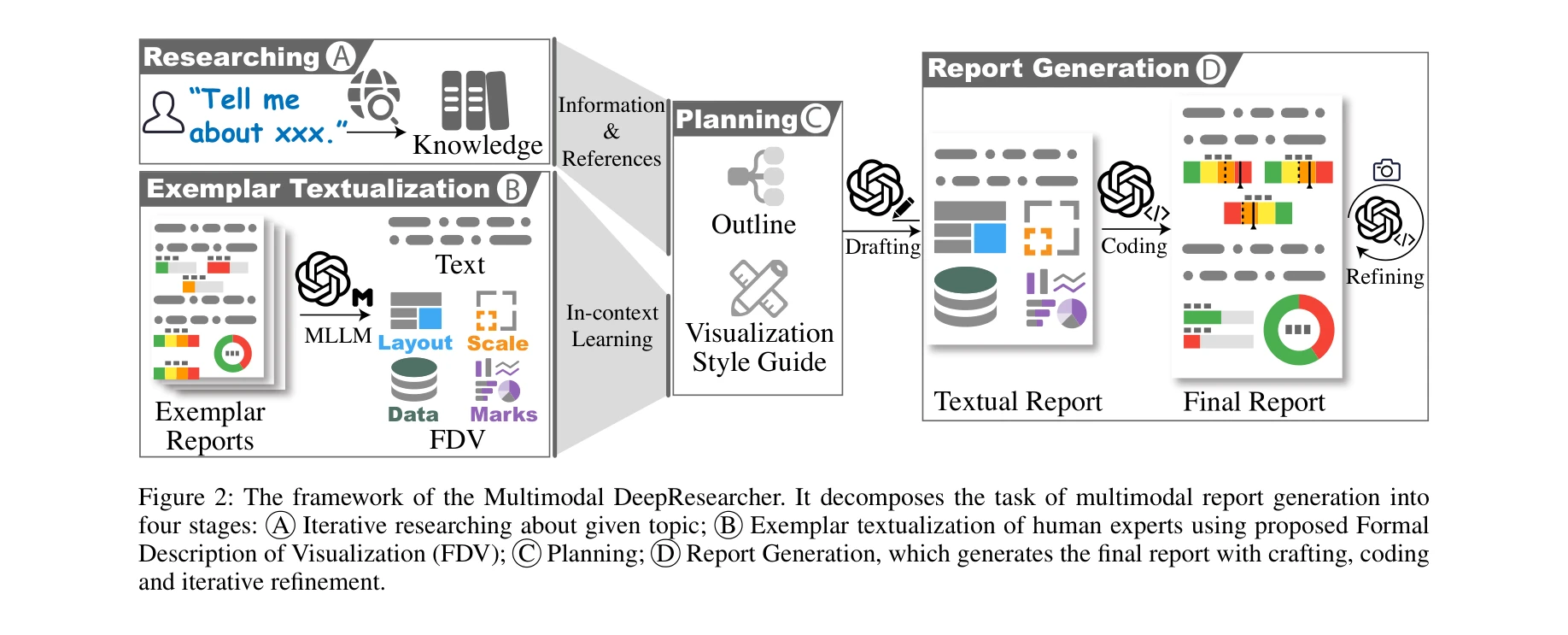
Figure 2: Multimodal DeepResearcher의 프레임워크 - 4단계(조사, 예시 보고서 텍스트화, 계획, 멀티모달 보고서 생성)로 분해
본 논문은 대규모 언어 모델(LLM)을 활용하여 텍스트와 차트가 유기적으로 통합된 멀티모달 보고서를 자동으로 생성하는 시스템을 제안한다. 핵심 혁신은 시각화를 구조화된 텍스트 표현(FDV: Formal Description of Visualization)으로 변환하여 LLM의 맥락 학습(in-context learning)을 가능하게 한 점이다.