Essence
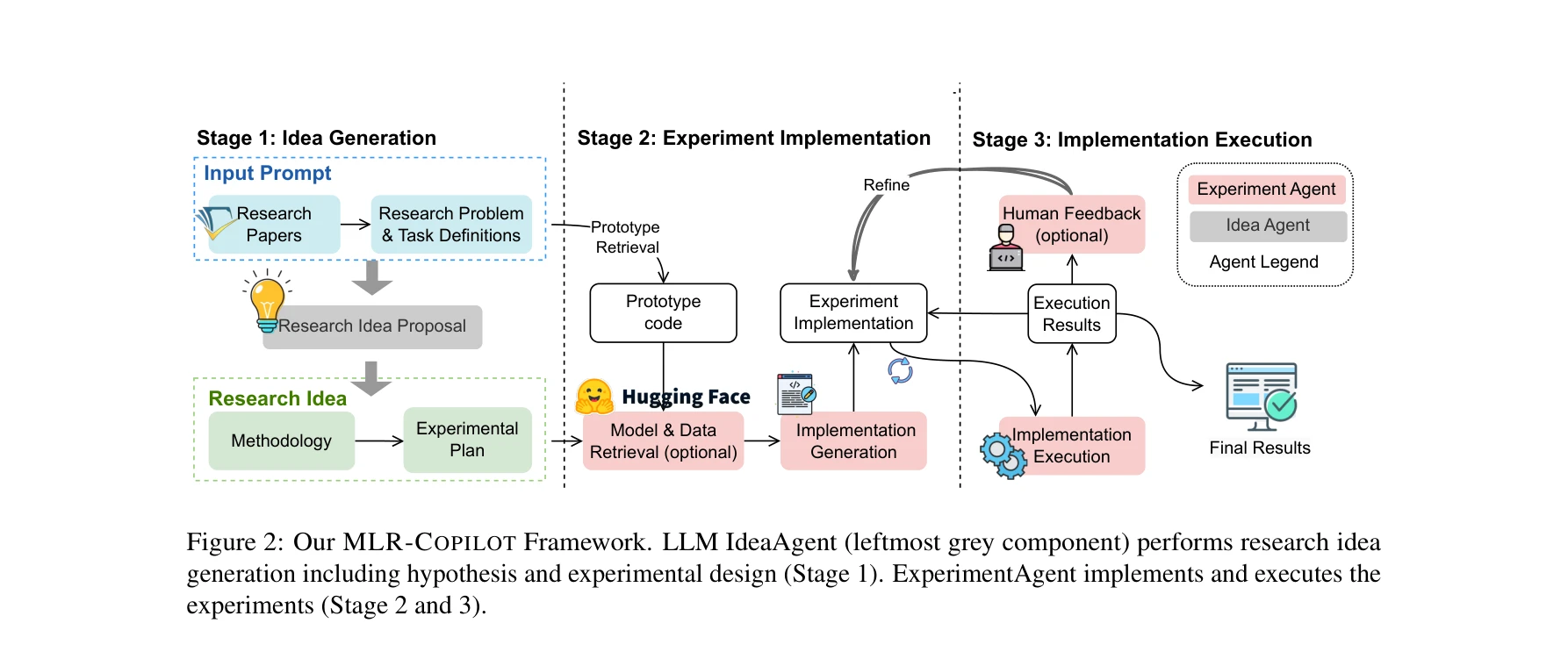
그림 2: 아이디어 생성(Stage 1), 실험 구현(Stage 2), 실행(Stage 3)의 세 단계로 구성된 MLR-COPILOT 프레임워크
본 논문은 대규모 언어모델(LLM) 에이전트 기반의 자동화된 머신러닝 연구 프레임워크인 MLR-COPILOT을 제시한다. 이 시스템은 연구 논문을 입력받아 자동으로 연구 아이디어를 생성하고, 이를 실제 코드로 구현·실행하여 검증된 연구 결과를 도출한다.
저자: Ruochen Li, Teerth Patel, Qingyun Wang, Xinya Du | 날짜: 2024 | DOI: 미제공
그림 2: 아이디어 생성(Stage 1), 실험 구현(Stage 2), 실행(Stage 3)의 세 단계로 구성된 MLR-COPILOT 프레임워크
본 논문은 대규모 언어모델(LLM) 에이전트 기반의 자동화된 머신러닝 연구 프레임워크인 MLR-COPILOT을 제시한다. 이 시스템은 연구 논문을 입력받아 자동으로 연구 아이디어를 생성하고, 이를 실제 코드로 구현·실행하여 검증된 연구 결과를 도출한다.

그림 1: 연구 논문을 입력으로 받아 검증된 연구 아이디어와 실행 결과를 출력하는 자동화된 머신러닝 연구 과정
그림 2: 세 단계 프레임워크의 상세 구조와 각 에이전트의 역할
Stage 1: 연구 아이디어 생성 (IdeaAgent)
Stage 2: 실험 구현 (ExperimentAgent)
Stage 3: 구현 실행 및 피드백
핵심 기술
한계점:
후속 연구 방향:
총평: MLR-COPILOT은 머신러닝 연구의 전체 자동화 파이프라인을 구현한 선도적 작업으로, RL 기반 IdeaAgent와 반복적 피드백 메커니즘을 통해 기존 연구의 한계를 실질적으로 극복하였다. 다만 평가 규모의 제한성과 실제 연구 임팩트에 대한 심화된 검증이 필요하다.