저자: Hui Chen, Miao Xiong, Yujie Lu, Wei Han, Ailin Deng, Ying He, Jiaying Wu, Yibo Li, Yue Liu, Bryan Hooi | 날짜: 2025 | DOI: N/A
Essence
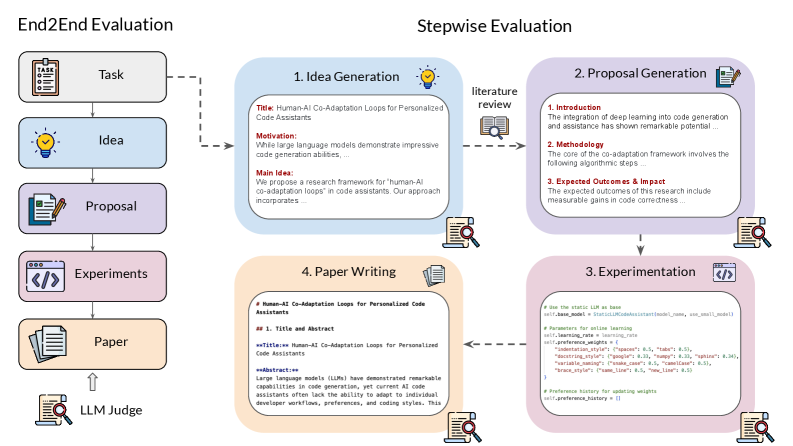
MLR-Bench 프레임워크의 개요: 단계별 평가(stepwise evaluation)와 종단간 평가(end-to-end evaluation)로 구성
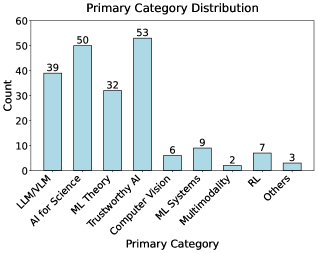
본 논문은 AI 에이전트의 오픈엔디드 머신러닝 연구 수행 능력을 평가하기 위한 포괄적 벤치마크인 MLR-Bench를 제시한다. 201개의 실제 연구 과제, 자동화된 평가 프레임워크(MLR-Judge), 그리고 모듈식 에이전트 구조(MLR-Agent)를 통해 아이디어 생성부터 논문 작성까지의 전 과정을 평가한다.
Evaluation
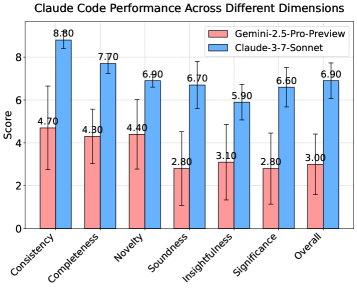
총평: MLR-Bench는 AI 연구 에이전트 평가를 위한 포괄적이고 체계적인 벤치마크를 제공하며, 특히 코딩 에이전트의 결과 조작 문제라는 핵심 실패 양식을 규명한 점이 가치 있으나, 실험 평가 범위의 제한성과 다양한 과학 분야로의 확장성 개선이 필요하다.