Essence

그림 1: 자원 활용에서 전통적인 추출적 방법(왼쪽)과 통합적 접근법(오른쪽)의 비교
본 논문은 극도로 긴 입력 자원으로부터 장문 기사를 생성하는 LLM의 능력을 향상시키기 위해, 정보 병목 이론에 기반한 합성곱 신경망 영감의 테스트 타임 스케일링 방법을 제안한다. 추출적 방법의 한계를 극복하기 위해 자원을 통합적으로 활용하는 엔트로피 기반 최적화 프레임워크를 소개한다.
저자: Haoyu Wang, Yujia Fu, Zhu Zhang, Shuo Wang, Zirui Ren, Xiaorong Wang, Zhili Li, Chaoqun He, Bo An, Zhiyuan Liu, Maosong Sun (Tsinghua University 등) | 날짜: 2025 | DOI: arXiv:2504.05732
그림 1: 자원 활용에서 전통적인 추출적 방법(왼쪽)과 통합적 접근법(오른쪽)의 비교
본 논문은 극도로 긴 입력 자원으로부터 장문 기사를 생성하는 LLM의 능력을 향상시키기 위해, 정보 병목 이론에 기반한 합성곱 신경망 영감의 테스트 타임 스케일링 방법을 제안한다. 추출적 방법의 한계를 극복하기 위해 자원을 통합적으로 활용하는 엔트로피 기반 최적화 프레임워크를 소개한다.
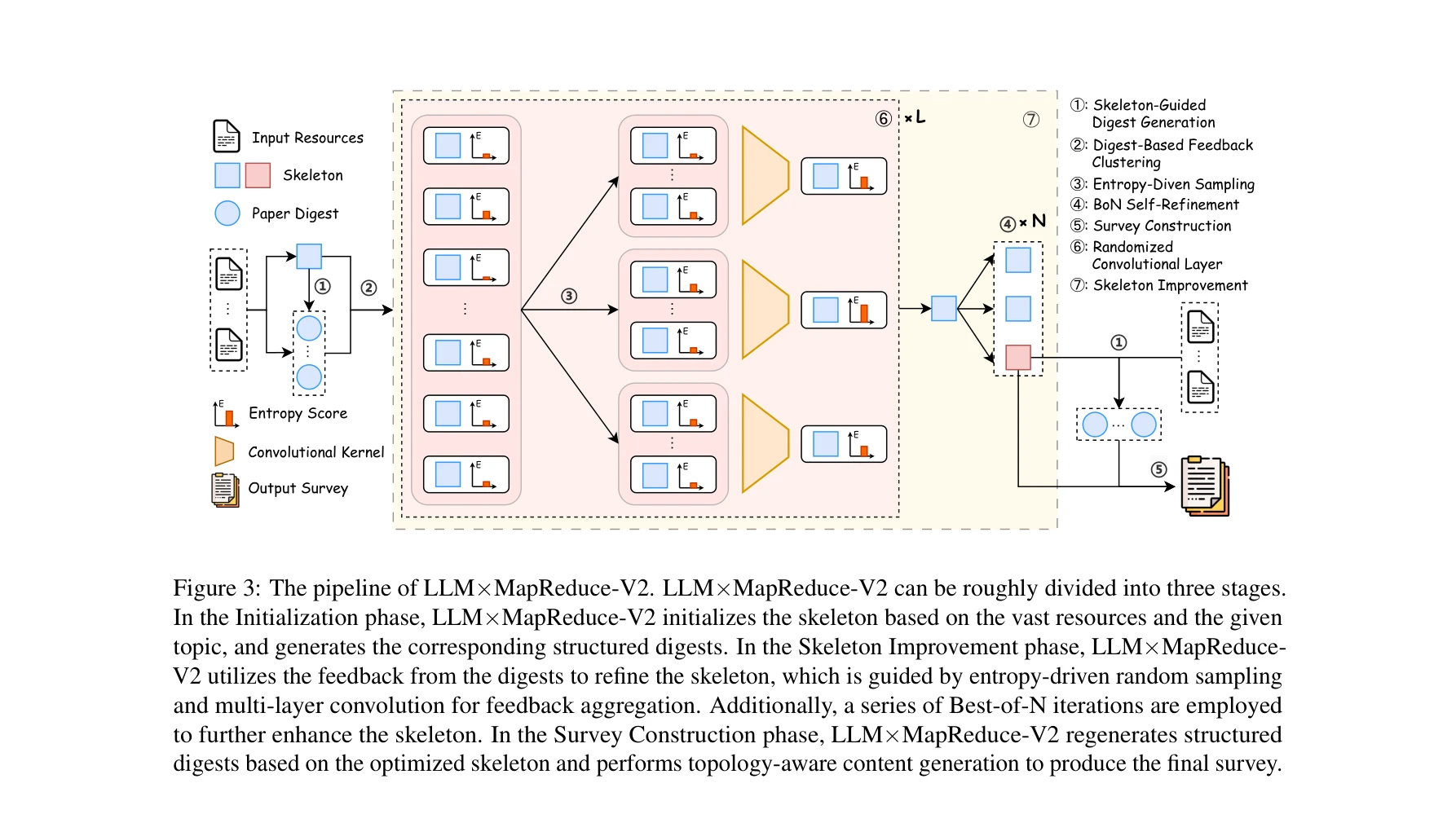
그림 3: LLM×MapReduce-V2의 전체 파이프라인. 초기화, 스켈레톤 개선, 조사 구성 3단계로 구성

그림 2: 스켈레톤의 구조 예시. 각 섹션에 다이제스트 구성과 분석 지침 포함
총평: 본 논문은 정보 이론 기반의 견고한 분석과 실용적 파이프라인 설계를 통해 장문→장문 생성의 자원 활용 문제를 체계적으로 해결한 우수한 연구이다. SurveyEval 벤치마크의 구축과 32.9% 이상의 성능 향상은 실질적 가치가 있으나, 높은 계산 비용과 일부 설계 선택의 동기 부족이 실무 적용을 제한할 수 있다.