Achievement
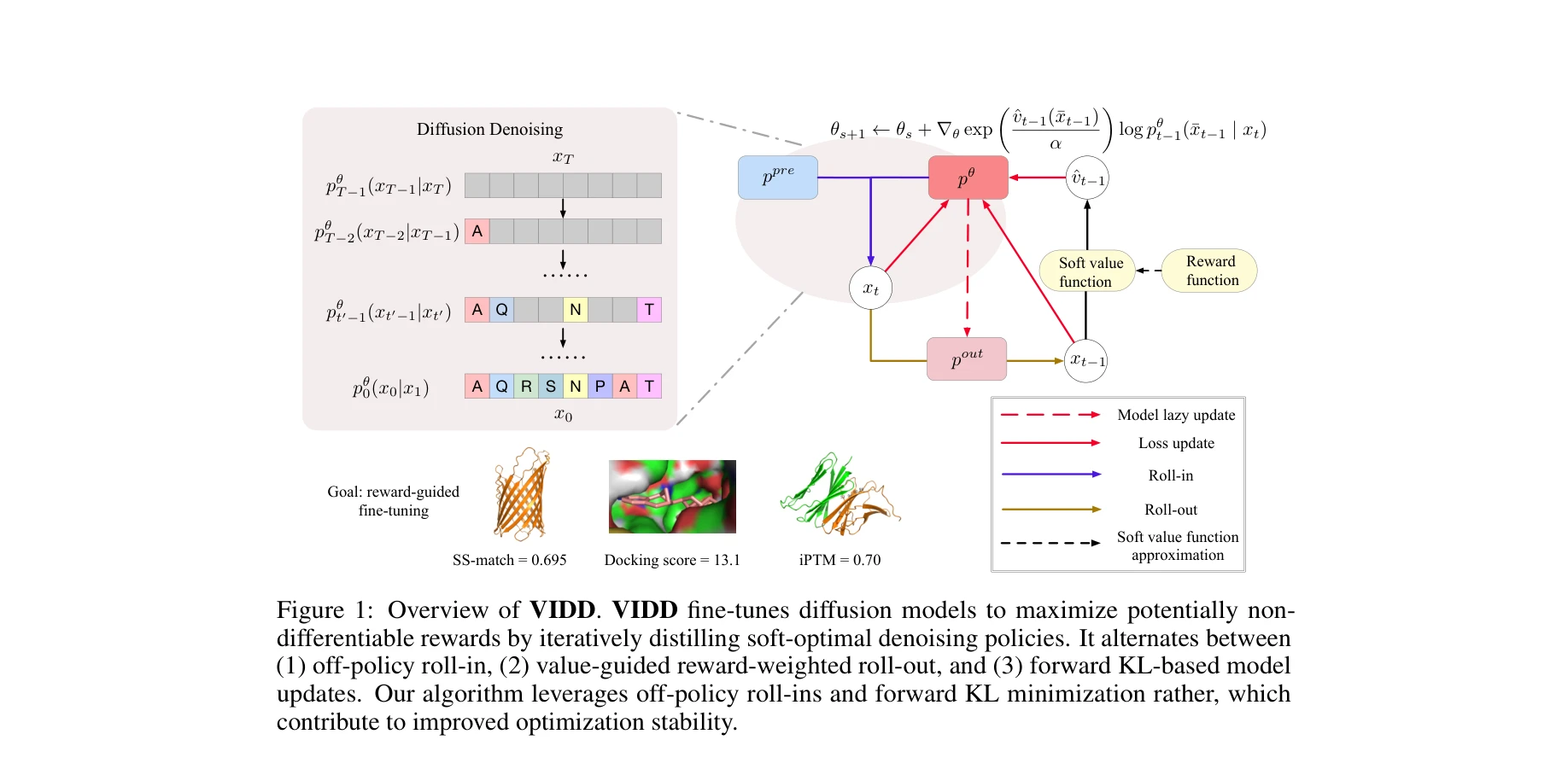
그림 1: VIDD의 개요. 오프정책 롤인, 값함수 기반 보상가중 롤아웃, 정방향 KL 기반 모델 업데이트를 반복적으로 수행
- 안정성 향상: 오프정책 데이터 수집과 정방향 KL 목적함수를 통해 온정책 방법 대비 훈련 안정성이 향상되고 모드 붕괴 위험 감소
- 샘플 효율 개선: 기존 RL 방법들(PPO, DDPO)보다 우수한 샘플 효율로 더 적은 보상 평가로 수렴
- 광범위한 작업 지원: 단백질 설계(이차 구조 매칭, PD-L1/IFNAR2 결합 설계), 작은 분자 설계, 조절 DNA 설계 등 다양한 생물분자 설계 과제에서 우수한 성능 입증
- 비미분가능 보상 최적화: 물리 시뮬레이션이나 과학 지식 기반 보상 등 임의의 비미분가능 보상함수에 대응 가능