Essence
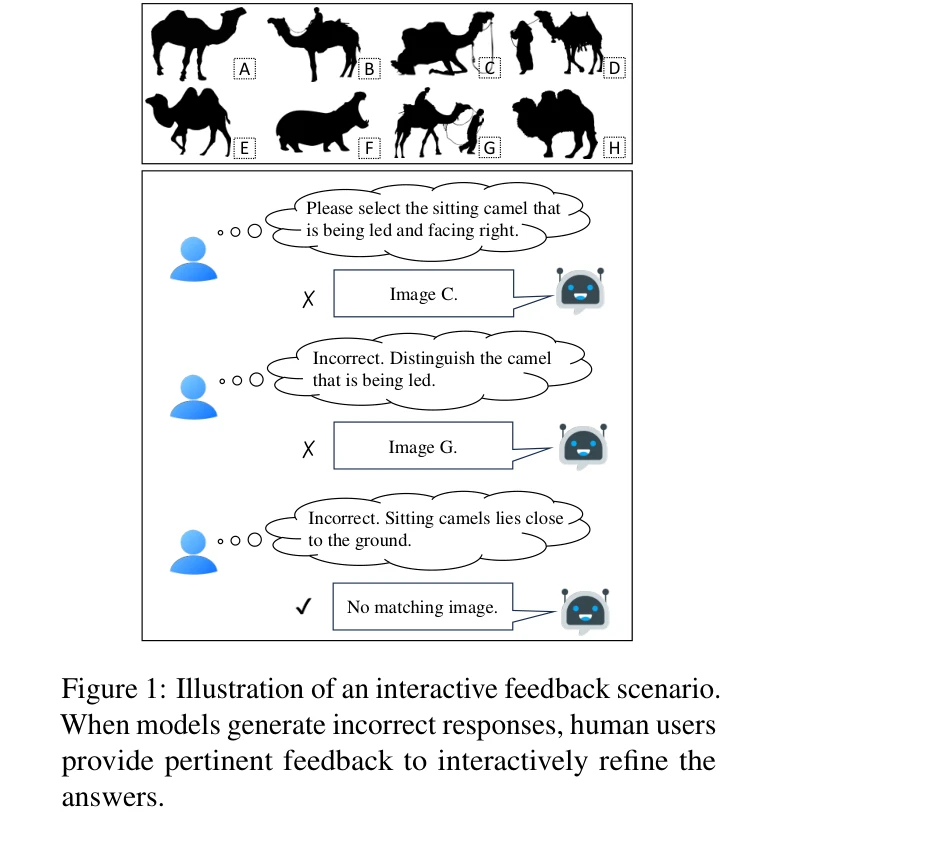
그림 1: 대화형 피드백 시나리오 예시. 모델이 잘못된 응답을 생성할 때 인간 사용자가 관련 피드백을 제공하여 답변을 상호작용적으로 개선함
대형 다중모달 모델(LMM)이 인간의 피드백을 통해 자신의 응답을 개선할 수 있는 상호작용 능력을 평가하는 최초의 벤치마크를 제시한다. 기존 벤치마크들이 정적 평가에 집중한 반면, 본 연구는 대화형 인간-AI 상호작용 시나리오에서의 모델 성능을 측정한다.
저자: Henry Hengyuan Zhao, Wenqi Pei, Yifei Tao, Haiyang Mei, Mike Zheng Shou | 날짜: 2025 | DOI: N/A
그림 1: 대화형 피드백 시나리오 예시. 모델이 잘못된 응답을 생성할 때 인간 사용자가 관련 피드백을 제공하여 답변을 상호작용적으로 개선함
대형 다중모달 모델(LMM)이 인간의 피드백을 통해 자신의 응답을 개선할 수 있는 상호작용 능력을 평가하는 최초의 벤치마크를 제시한다. 기존 벤치마크들이 정적 평가에 집중한 반면, 본 연구는 대화형 인간-AI 상호작용 시나리오에서의 모델 성능을 측정한다.
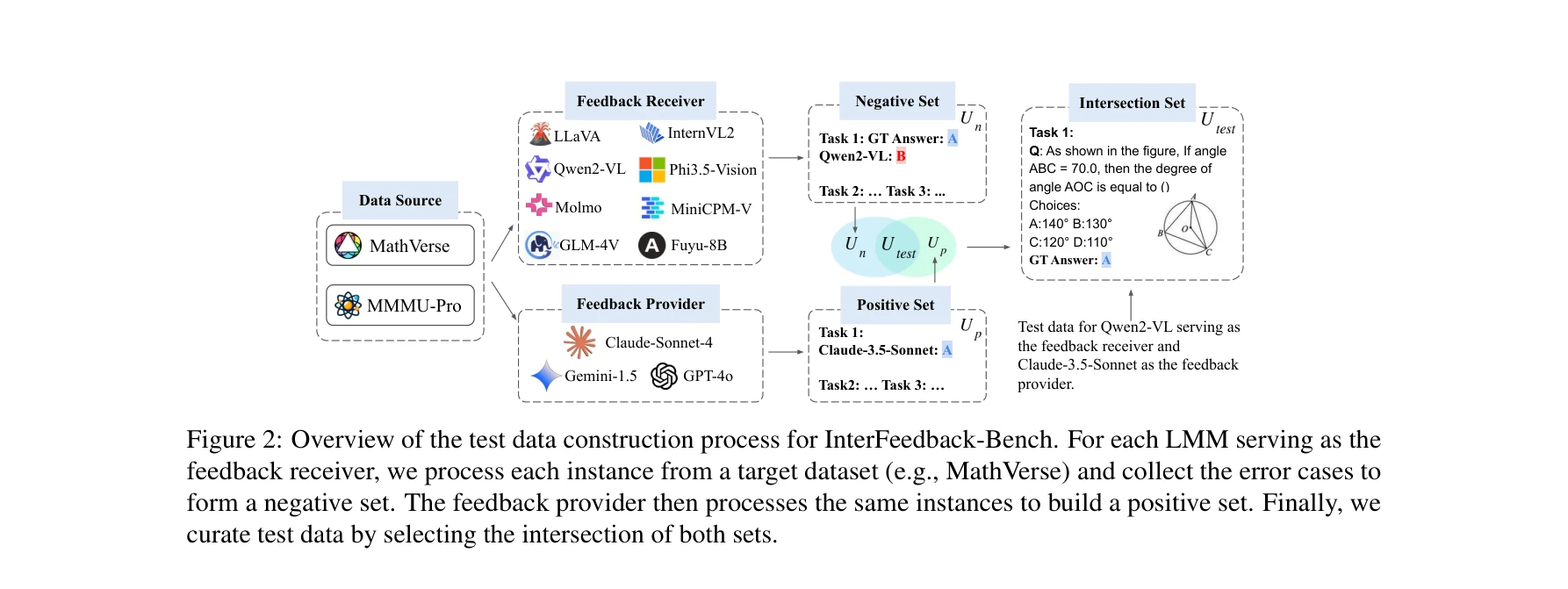
그림 2: InterFeedback-Bench의 테스트 데이터 구성 프로세스. 각 LMM별로 피드백 수신자가 실패한 사례(음성 집합)와 피드백 제공자가 성공한 사례(양성 집합)의 교집합을 선별
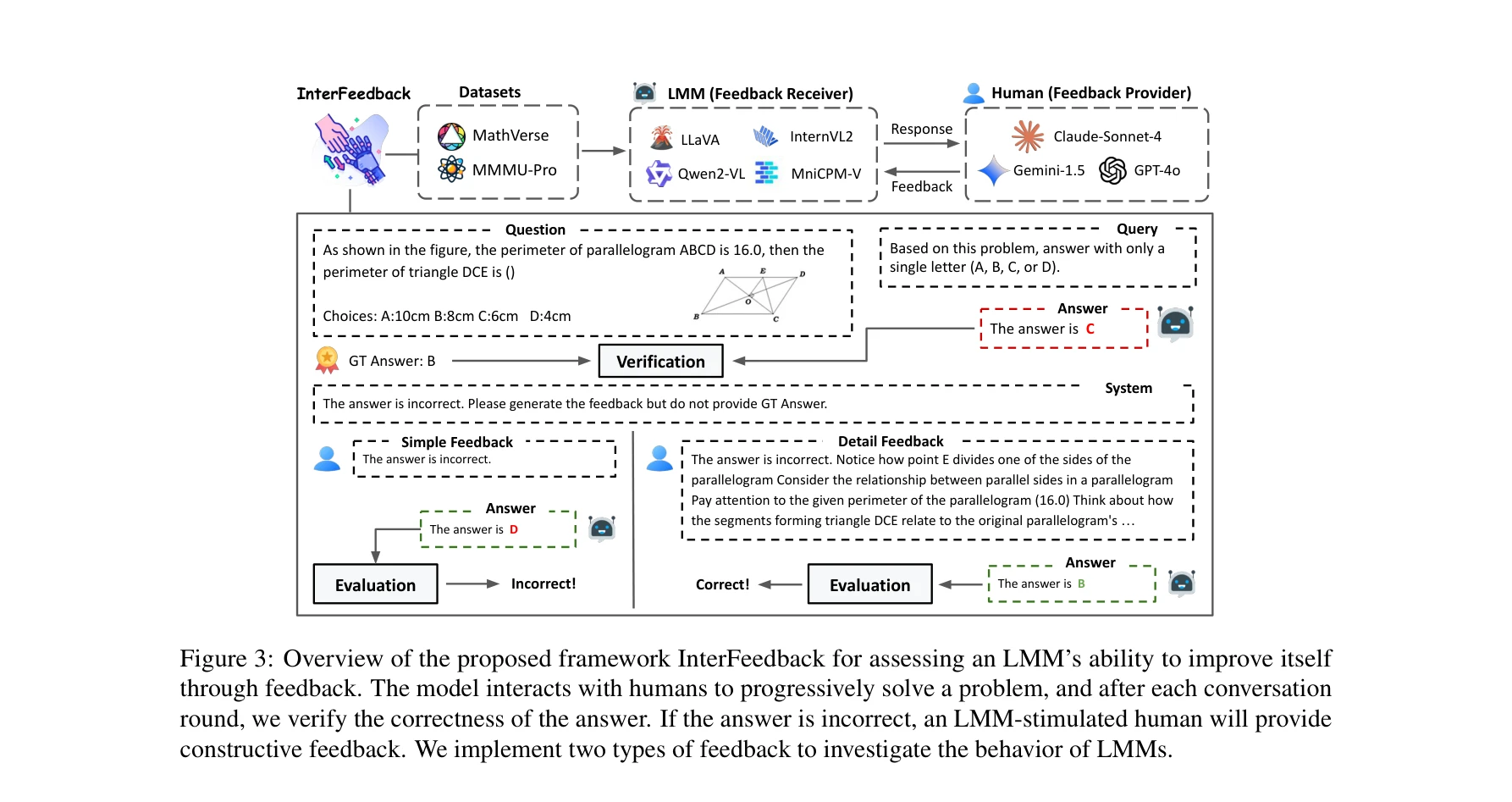
그림 3: 모델의 자기개선 능력을 평가하기 위한 제안된 InterFeedback 프레임워크 개요
총평: 본 논문은 LMM의 상호작용 지능을 평가하는 중요하면서도 미개척된 영역에 최초로 접근하며, 자동화된 벤치마크와 인간 평가를 결합한 포괄적 평가 방법론을 제시한다. 다만, 현재 모든 모델의 낮은 성능과 피드백 제공자의 완벽성 미달 문제는 벤치마크의 실용성을 다소 제한하며, 후속 연구에서 모델 개선 방법론이 함께 제시되어야 할 것으로 판단된다.