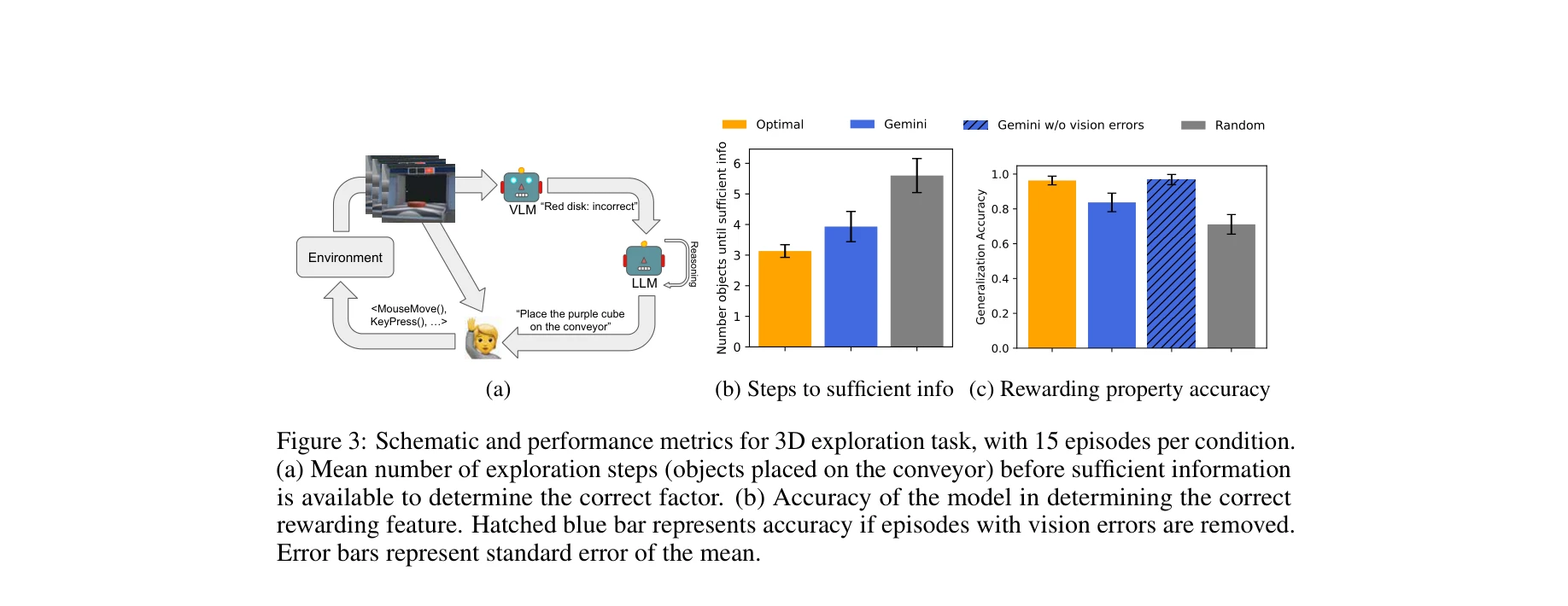
Achievement
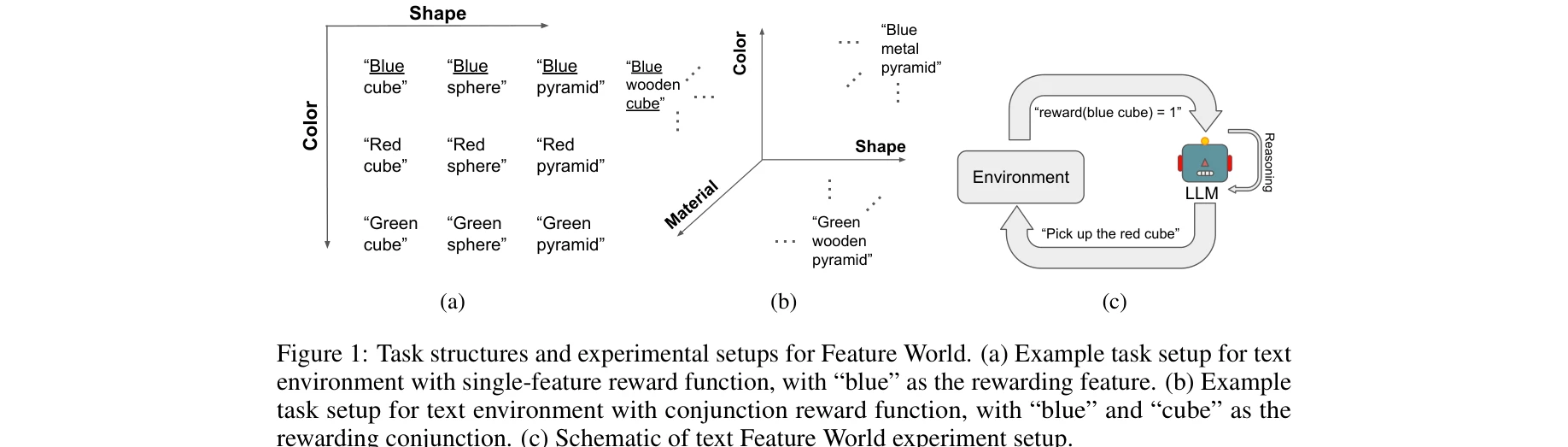
텍스트 기반 Feature World의 단순한 상태 비의존 보상 함수 학습 환경
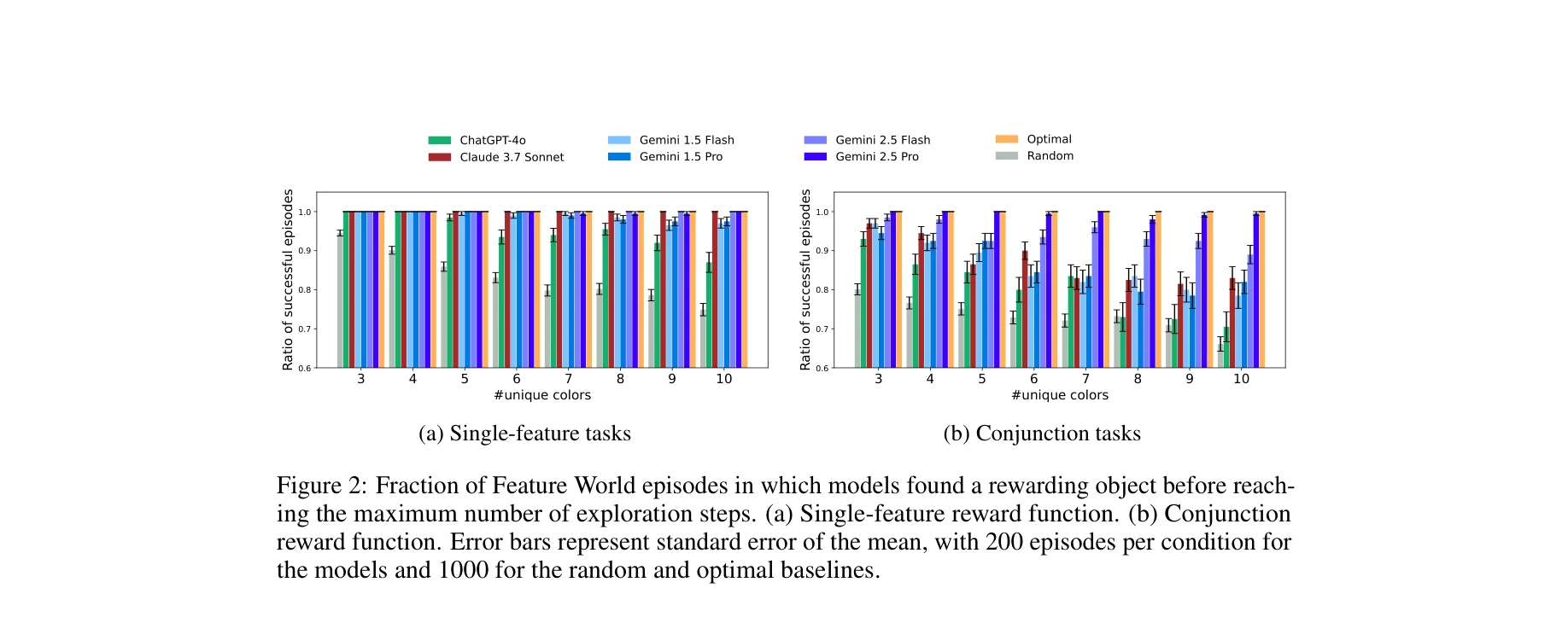
모델별 정보 수집 효율성: 최적 정책과의 근접성
- 정보 수집 능력 (Information Gathering): 모든 평가 대상 LLM이 간단한 보상 함수를 가진 Feature World 작업에서 최적(near-optimal) 성능에 근접. 특히 고정 스텝 예산 내에서 보상 대상을 찾는 성공률이 높음
- 메타러닝의 조건부 성공: 기본 Alchemy 환경에서는 메타러닝 실패(시행 간 성능 개선 없음)를 보였으나, 요약 프롬팅(summarization prompting) 을 도입하면 시행을 거듭하면서 성능이 유의미하게 향상됨
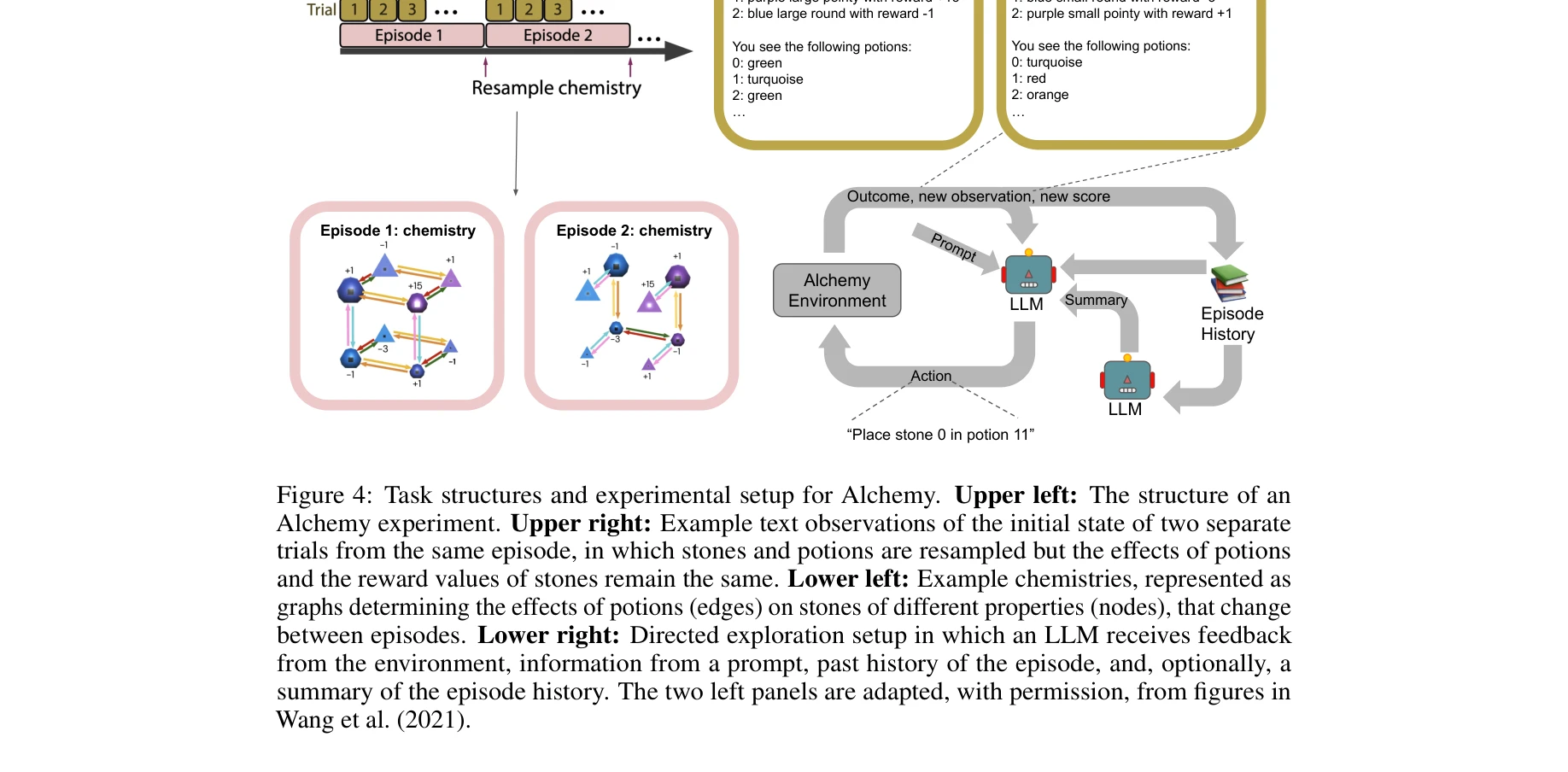
다중 상태 의존 시행을 요구하는 메타러닝 벤치마크
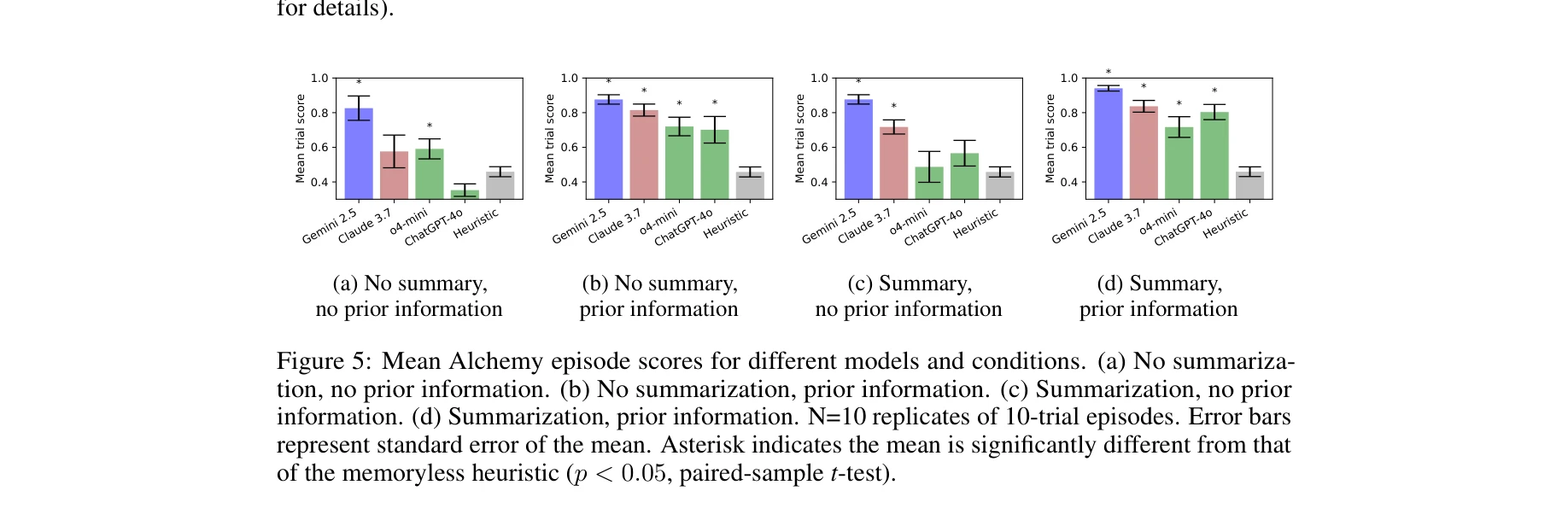
요약 여부에 따른 성능 차이: Gemini 2.5 우수, ChatGPT 낮음
- 모델 간 강한 이질성: Alchemy 환경에서 명확한 성능 격차 - Gemini 2.5 > Claude 3.7 >> ChatGPT-4o/o4-mini. 이는 Alchemy이 파운데이션 모델의 탐색 능력 벤치마크로서의 가치를 입증
- 전략 적응과 재학습: 일부 모델(특히 Gemini 2.5)에서 환경 규칙이 예기치 않게 변경될 때 요약을 통해 새로운 세계 모델(world model)의 적응적 재학습 가능