Essence

arXiv 초록에서 ChatGPT가 선호하거나 비선호하는 단어들의 빈도 변화 추이
본 논문은 arXiv 논문 초록의 통계적 분석을 통해 인간과 대형언어모델(LLM)의 공진화(coevolution) 현상을 보여준다. 특히 2024년 초 ChatGPT의 과용 단어들이 지적된 직후부터 해당 단어들의 사용 빈도가 급감하는 현상을 발견했으며, 이는 연구자들이 LLM 출력을 의도적으로 수정하고 있음을 시사한다.
저자: Mingmeng Geng, Roberto Trotta | 날짜: 2025 | DOI: N/A
arXiv 초록에서 ChatGPT가 선호하거나 비선호하는 단어들의 빈도 변화 추이
본 논문은 arXiv 논문 초록의 통계적 분석을 통해 인간과 대형언어모델(LLM)의 공진화(coevolution) 현상을 보여준다. 특히 2024년 초 ChatGPT의 과용 단어들이 지적된 직후부터 해당 단어들의 사용 빈도가 급감하는 현상을 발견했으며, 이는 연구자들이 LLM 출력을 의도적으로 수정하고 있음을 시사한다.
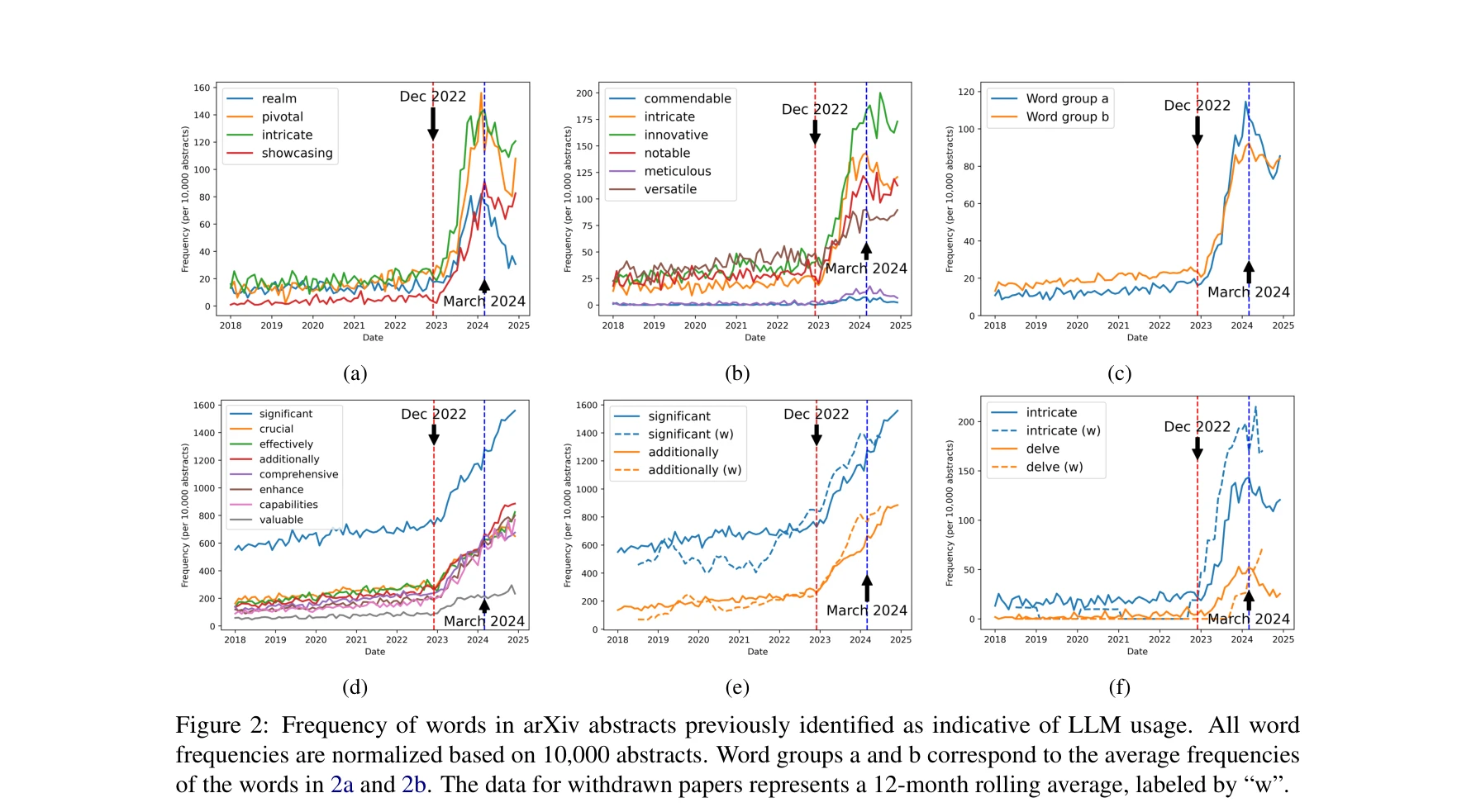
2018-2024년 arXiv 초록에서 LLM 사용을 나타내는 단어들의 빈도 변화. (a)Liang et al. 2024b가 지적한 4개 단어, (b)Liang et al. 2024a가 지적한 6개 단어의 평균 빈도 추이
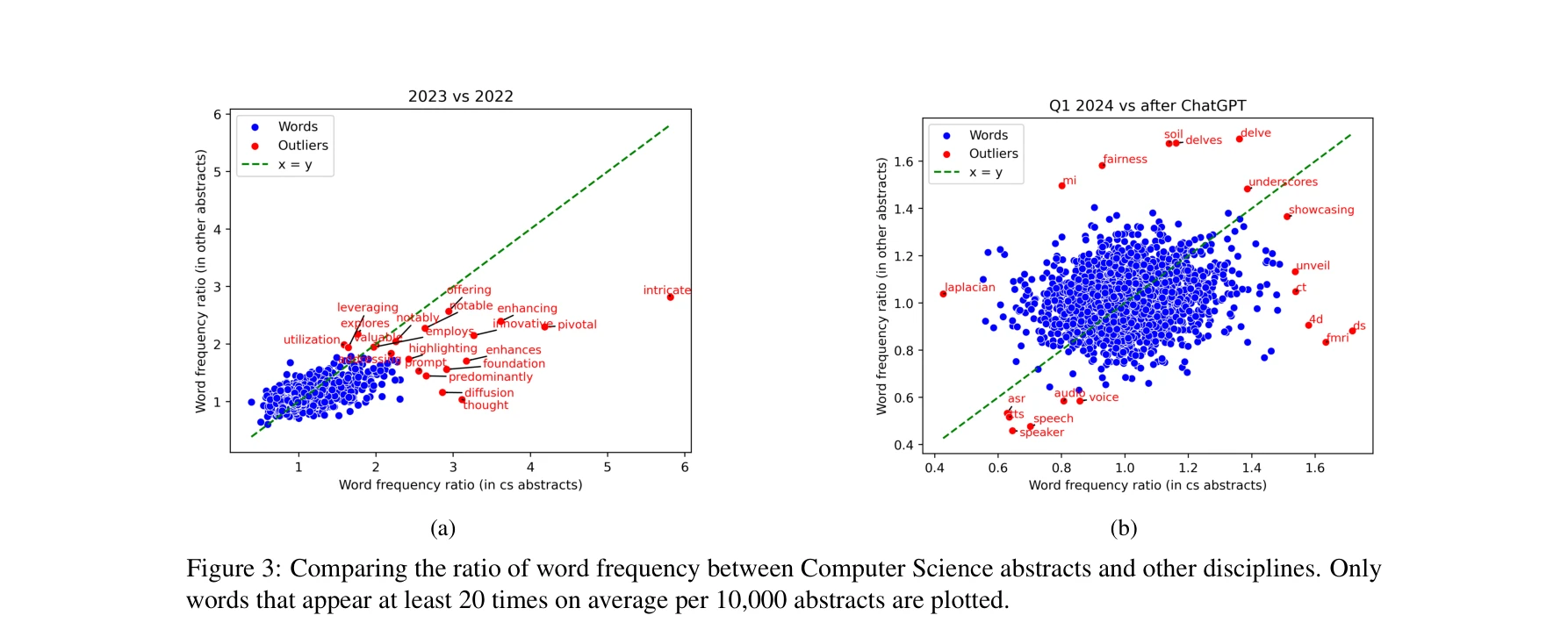
컴퓨터과학(CS) 초록과 다른 분야 초록의 단어 빈도 비율 비교. (a)2023년 vs. 2022년 비율, (b)2024년 Q1 vs. 2023-2024년 전체 빈도 비율
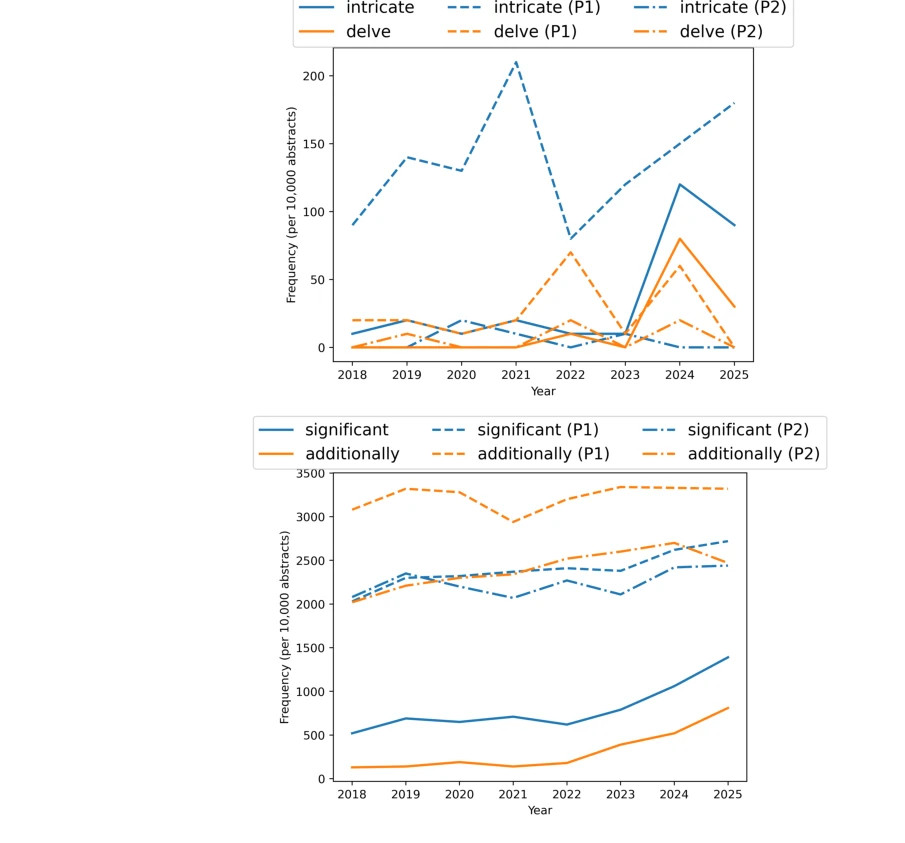
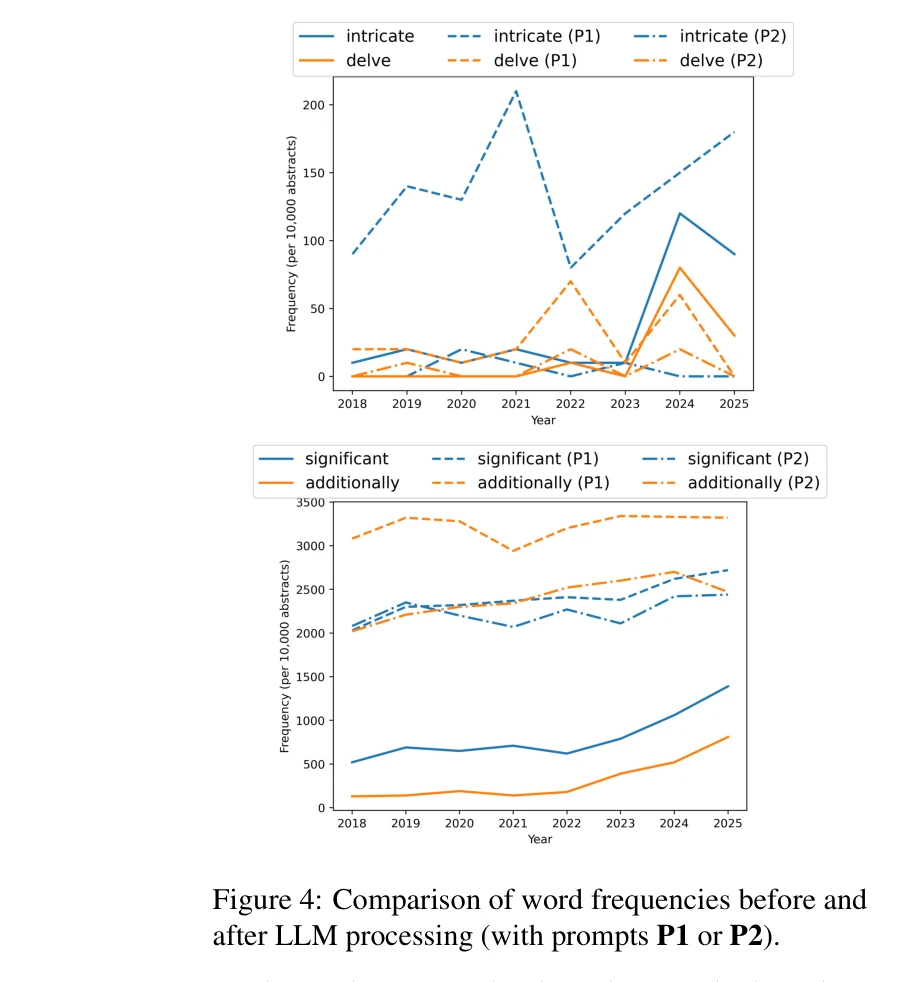
원본 arXiv 초록과 GPT-4o-mini로 처리한 버전의 단어 빈도 비교. P1: 일반 수정 프롬프트, P2: 특정 단어 금지 프롬프트
Binoculars를 이용한 MGT 탐지 결과. 낮은 점수는 기계생성 가능성 높음을 나타냄. (a)실제 논문 초록의 시간별 변화, (b)원본과 LLM 처리 초록 간 비교
총평: 인간과 LLM의 상호적응이라는 흥미로운 현상을 arXiv 대규모 텍스트 데이터로 명확히 증명하며, 현존 탐지 기술의 실질적 한계를 폭로함으로써 MGT 탐지 분야의 재성찰을 촉구하는 가치 있는 연구이다. 다만 인과성과 저자 의도에 대한 직접 증거 부족이 학술적 강도를 다소 제한한다.