저자: Wanghan Xu, Xiangyu Zhao, Yuhao Zhou, Xiaoyu Yue, Ben Fei, Fenghua Ling, Wenlong Zhang, Lei Bai | 날짜: 2025 | DOI: arXiv:2505.17139v3
Essence
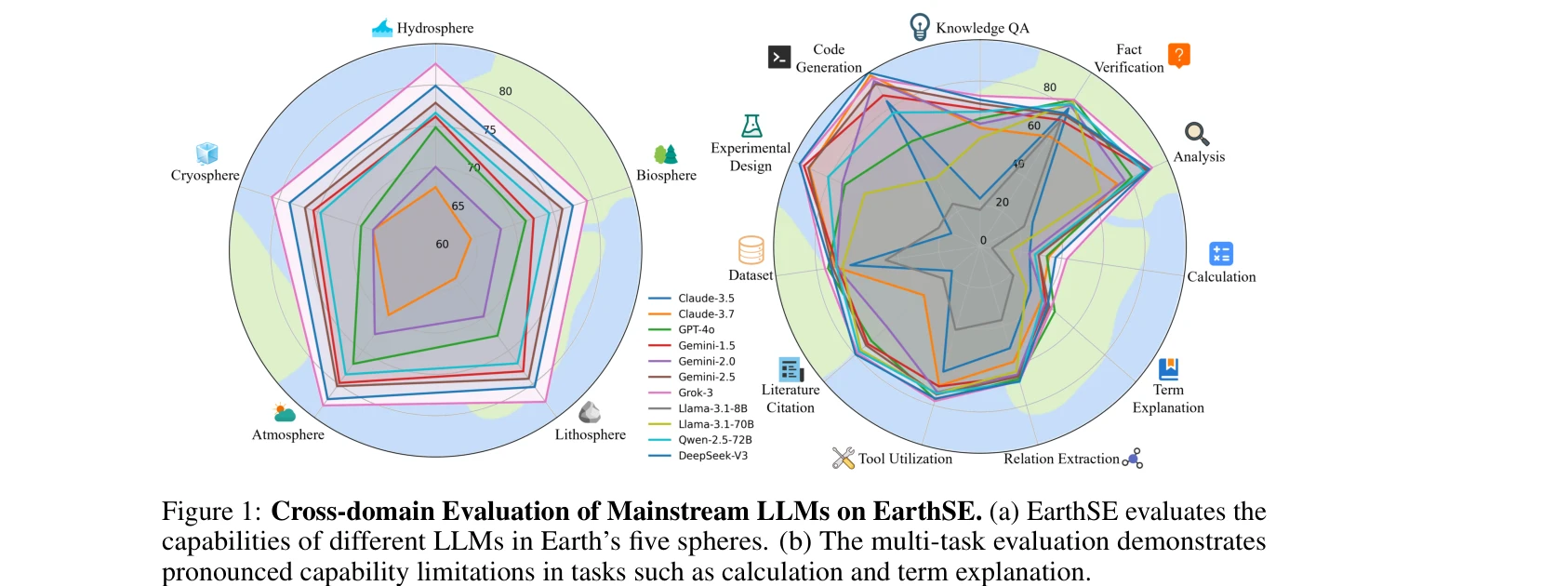
Figure 1: 주류 LLM들의 EarthSE에서의 교차 도메인 평가. (a) EarthSE는 지구의 5개 권역에서 다양한 LLM의 능력을 평가 (b) 다중 과제 평가는 계산 및 용어 설명 등에서 뚜렷한 한계 노출
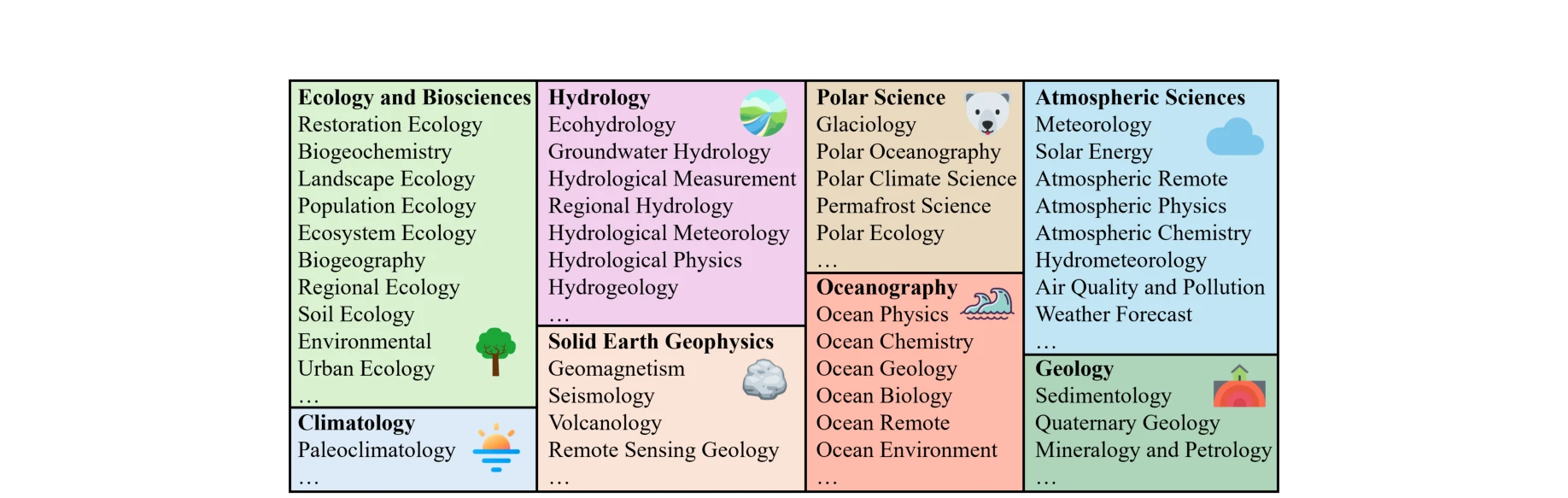
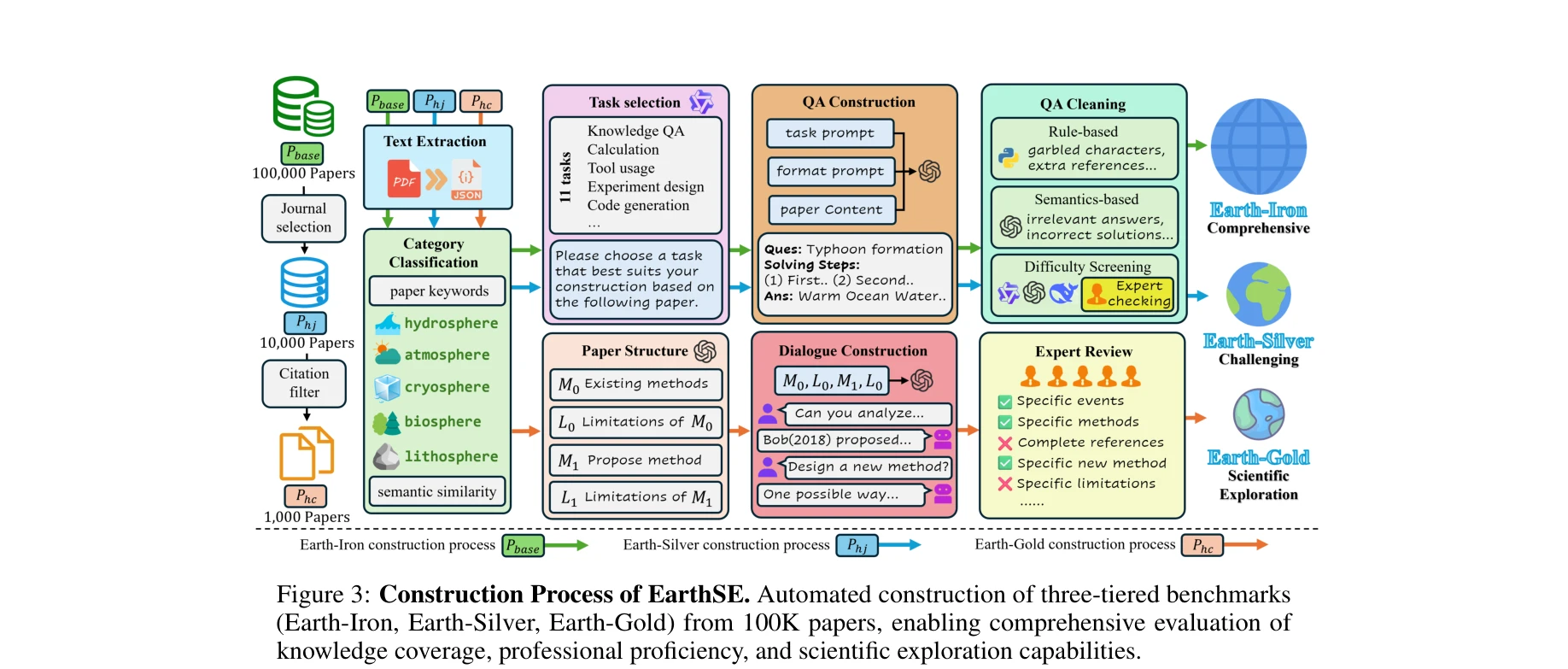
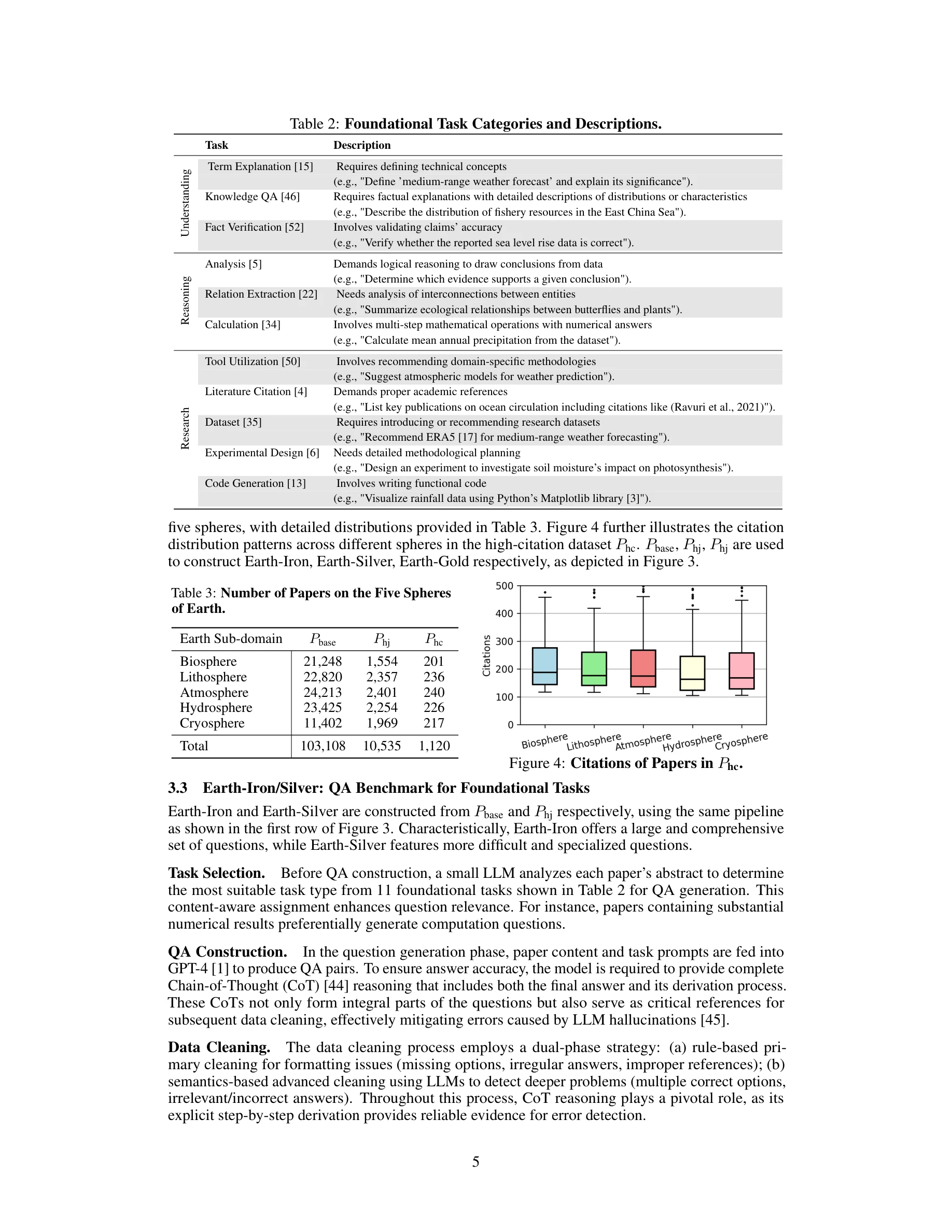
본 논문은 지구과학 분야에 특화된 최초의 포괄적 벤치마크 EarthSE를 제시하며, 10만 건의 학술논문 코퍼스를 기반으로 기초 지식부터 고급 과학탐사 능력까지 평가할 수 있는 다층 평가 프레임워크를 구축했다. 특히 개방형 다중 턴 대화를 통해 LLM의 과학탐사 능력(방법론 귀납, 한계 분석, 개념 제안)을 평가하는 새로운 평가 메트릭을 도입했다.
Evaluation
총평: EarthSE는 지구과학 분야에서 기초 지식부터 개방형 과학탐사 능력까지 다층적으로 평가하는 최초의 포괄적 벤치마크로서 상당한 학술적·실무적 가치를 제공한다. 특히 SES 메트릭을 통한 과학적 사고의 정량화는 향후 LLM 과학 응용 평가의 새로운 방향을 제시할 수 있다. 다만 자동화 파이프라인의 기술적 세부사항, 평가 메트릭의 객관성 검증, 모델 성능 저조의 근본 원인 분석 등이 보강되면 더욱 강력한 벤치마크가 될 수 있을 것으로 예상된다.