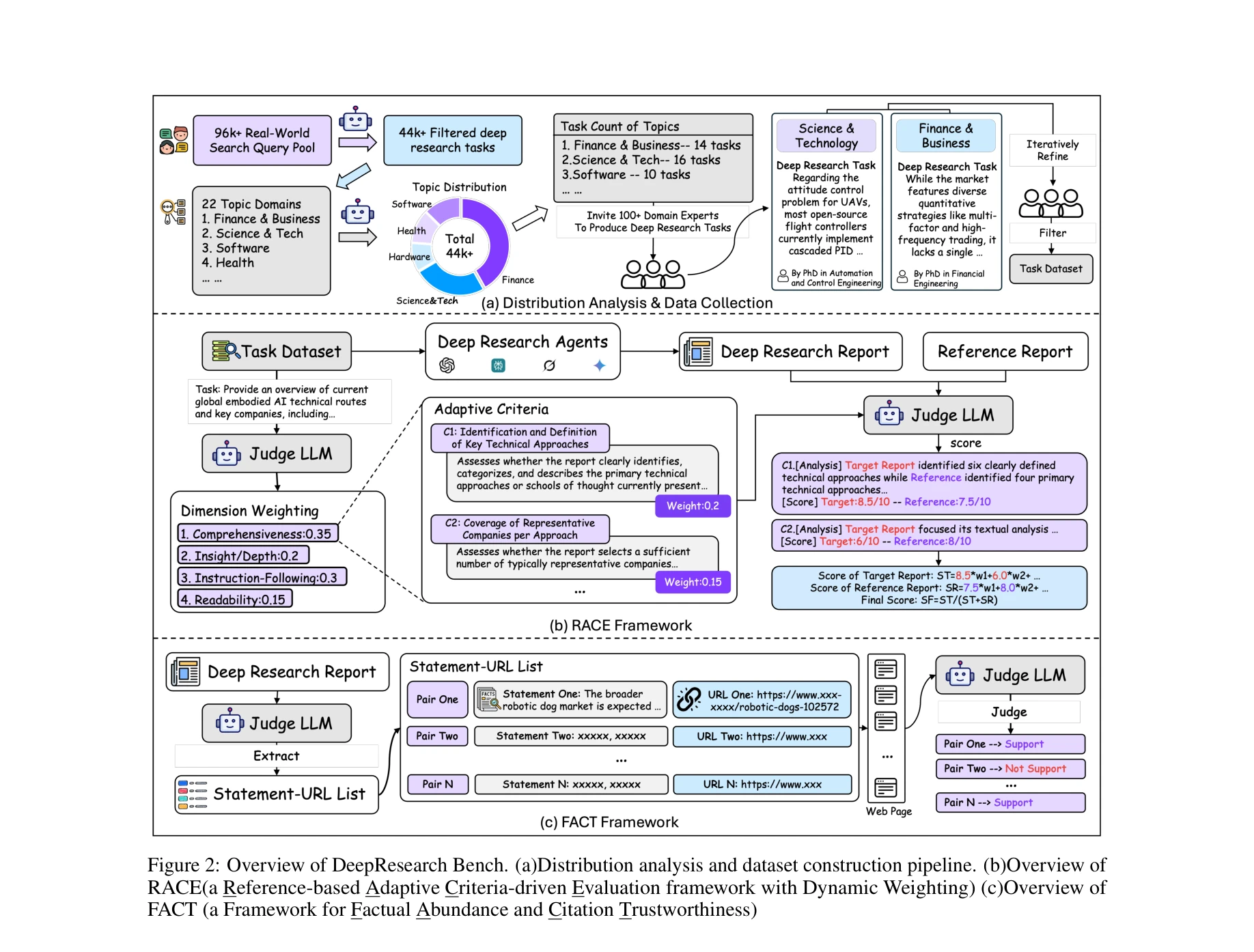
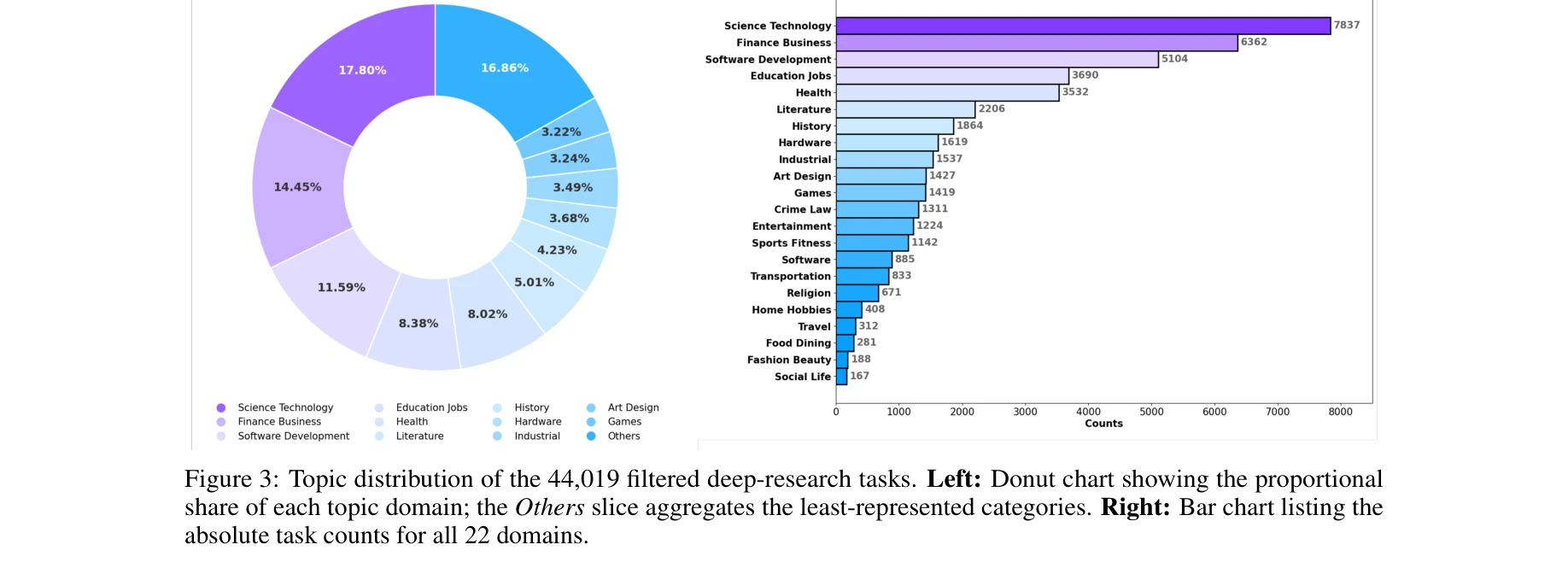
Essence
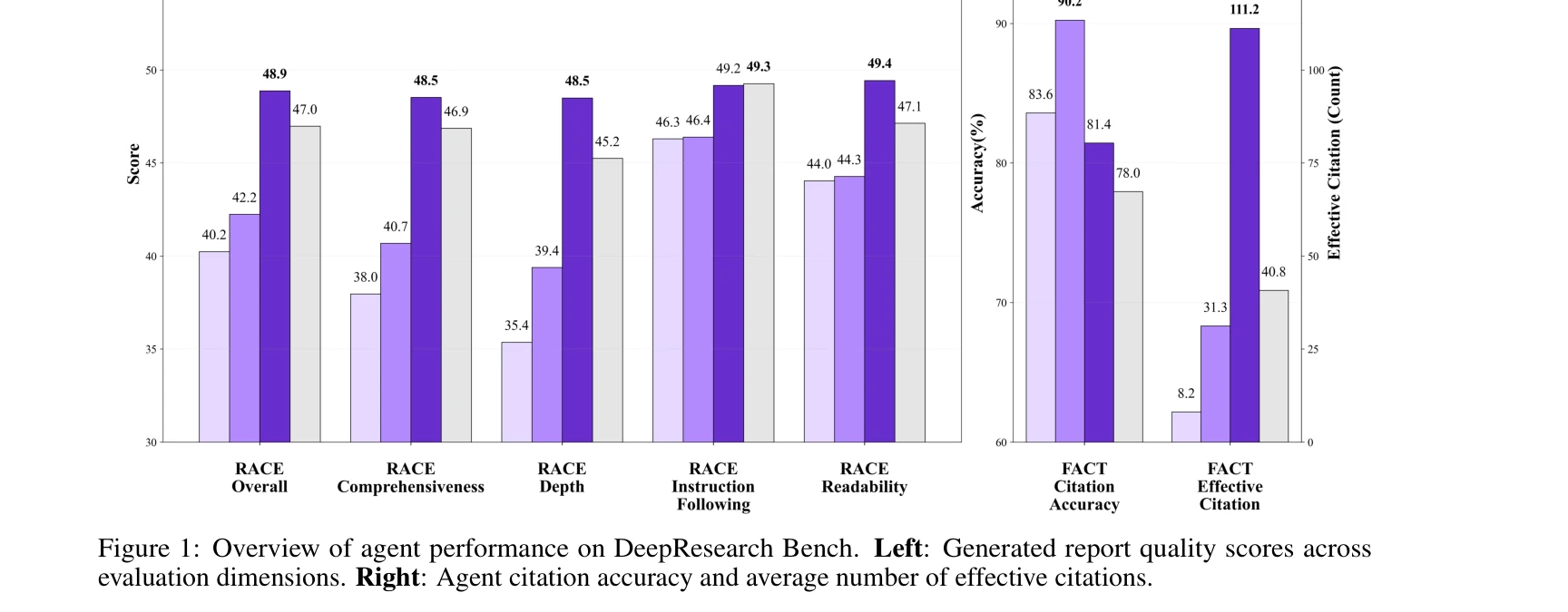
그림 1: DeepResearch Bench에서의 에이전트 성능 개요. 좌측: 평가 차원별 생성된 보고서 품질 점수, 우측: 에이전트 인용 정확도 및 평균 효과적 인용 수
본 논문은 대규모 언어모델 기반 깊이 있는 연구 에이전트(Deep Research Agents, DRAs)를 체계적으로 평가하기 위한 최초의 종합 벤치마크 DeepResearch Bench를 제시한다. 22개 분야의 박사 수준 연구 과제 100개와 두 가지 혁신적인 평가 방법론(RACE, FACT)을 통해 DRA의 보고서 생성 품질과 정보 검색 능력을 정량적으로 평가한다.