Essence

DS-Agent의 개요: (a) CBR 기반 LLM의 구조, (b) 반복 단계에 따른 성능 개선
대규모 언어모델(LLM)의 사례 기반 추론(Case-Based Reasoning, CBR)을 결합하여 자동화된 데이터 과학 작업을 수행하는 DS-Agent 프레임워크를 제시한다. 개발 단계에서는 Kaggle의 전문가 지식을 활용한 반복적 개선을, 배포 단계에서는 저자원 환경에서의 효율적 코드 생성을 달성한다.
저자: Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, Jun Wang | 날짜: 2024 | DOI: N/A
DS-Agent의 개요: (a) CBR 기반 LLM의 구조, (b) 반복 단계에 따른 성능 개선
대규모 언어모델(LLM)의 사례 기반 추론(Case-Based Reasoning, CBR)을 결합하여 자동화된 데이터 과학 작업을 수행하는 DS-Agent 프레임워크를 제시한다. 개발 단계에서는 Kaggle의 전문가 지식을 활용한 반복적 개선을, 배포 단계에서는 저자원 환경에서의 효율적 코드 생성을 달성한다.
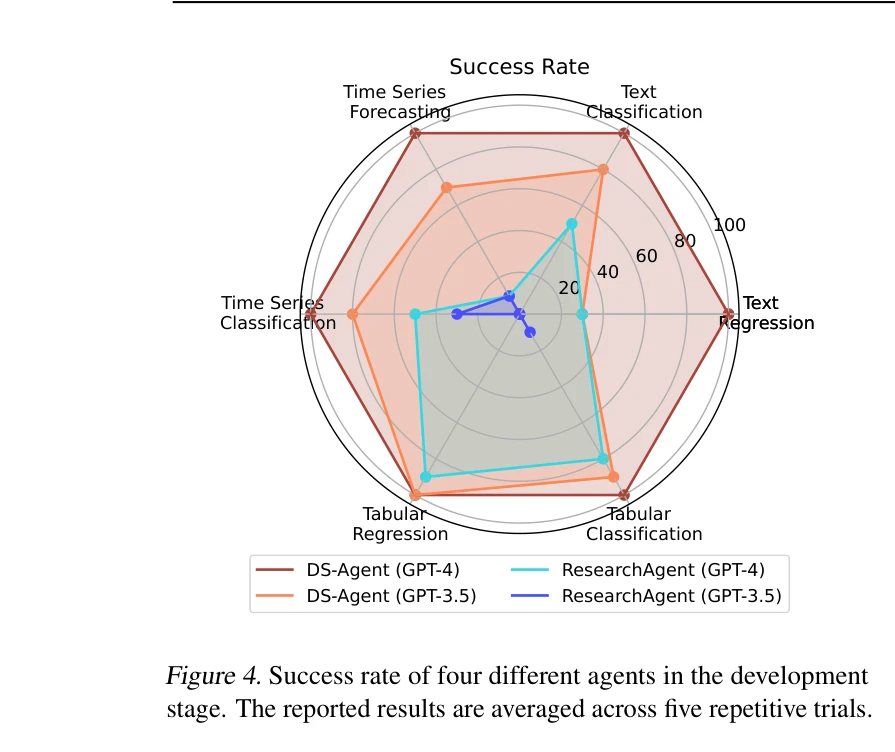
개발 단계에서의 성공률 및 배포 단계에서의 원패스율

CBR 기반 LLM의 구조: RAG와의 비교
$$p_{CBR}(y^t|\tau) = \sum_{l^{t-1}} p_E(l^{t-1}|\tau) \sum_{c^t} p_R(c^t|\tau, l^{t-1})p_{LLM}(y^t|c^t, \tau, l^{t-1})$$
총평: DS-Agent는 LLM과 CBR의 효과적 결합을 통해 데이터 과학 자동화의 실질적 성능 개선을 달성한 의미 있는 연구이다. 특히 저자원 환경에서의 배포 가능성과 오픈소스 LLM 성능 향상은 실용적 가치가 높으나, 제한된 평가 범위와 단순한 검색 메커니즘이 향후 개선 대상이다.