Essence
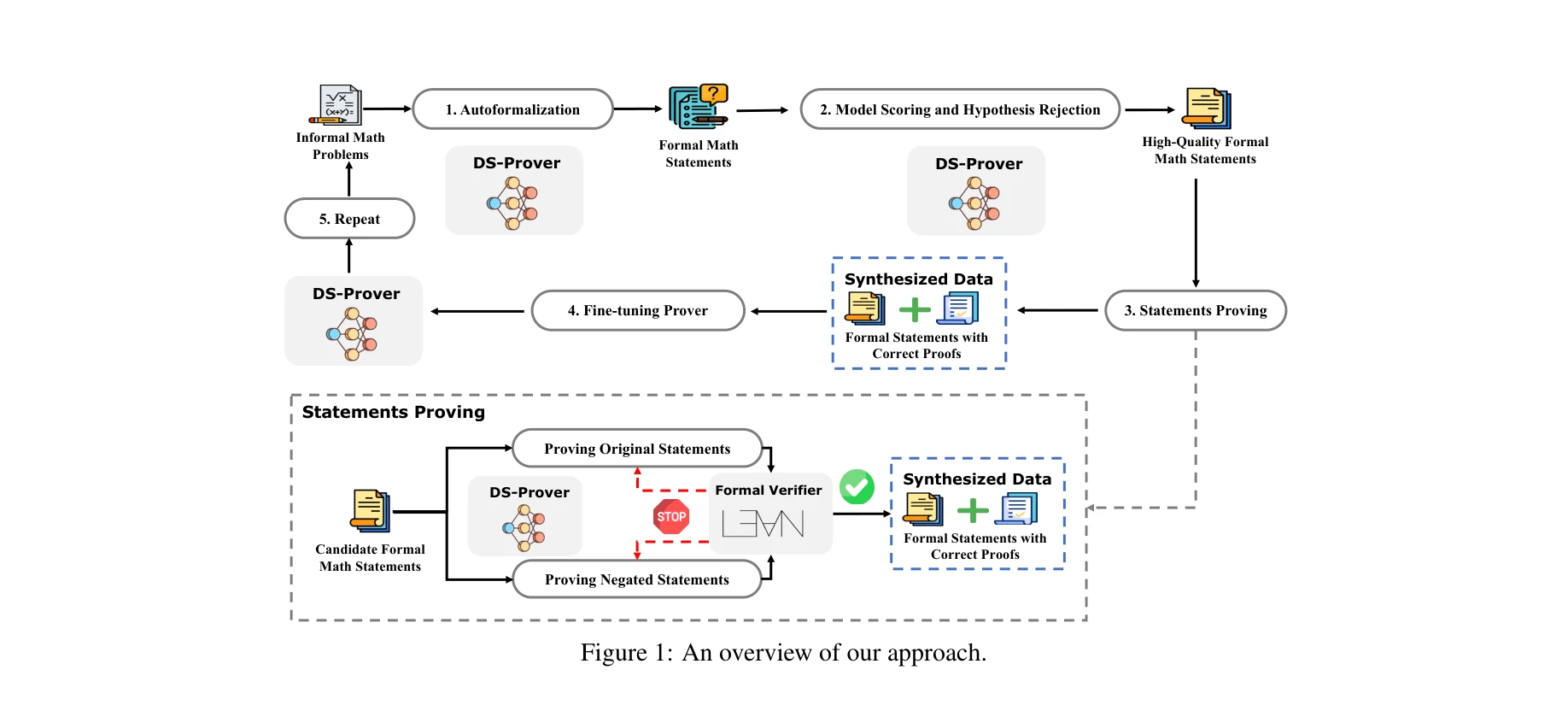
그림 1: 접근 방법의 개요. 비형식 수학 문제에서 형식적 증명 데이터를 생성하는 반복적 파이프라인
이 논문은 비형식적 수학 문제에서 자동으로 대규모 형식 증명 데이터(Lean 4)를 합성하는 방법을 제시하고, 이를 통해 미세조정된 LLM이 GPT-4를 능가하는 정리 증명 성능을 달성했다. 특히 800만 개의 정형화된 명제-증명 쌍을 생성하여 훈련 데이터 부족 문제를 해결했다.
저자: Huajian Xin, Daya Guo, Zhihong Shao, Z. Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, Xiaodan Liang | 날짜: 2024 | DOI: 미공개
그림 1: 접근 방법의 개요. 비형식 수학 문제에서 형식적 증명 데이터를 생성하는 반복적 파이프라인
이 논문은 비형식적 수학 문제에서 자동으로 대규모 형식 증명 데이터(Lean 4)를 합성하는 방법을 제시하고, 이를 통해 미세조정된 LLM이 GPT-4를 능가하는 정리 증명 성능을 달성했다. 특히 800만 개의 정형화된 명제-증명 쌍을 생성하여 훈련 데이터 부족 문제를 해결했다.
![Figure 1 참조]
4단계 반복 파이프라인:
한계점:
후속 연구 방향:
총평: 이 논문은 정형식 증명의 오래된 데이터 부족 문제를 대규모 자동 합성과 반복 검증을 통해 실용적으로 해결한 견고한 연구로, 특히 800만 규모 오픈소스 데이터셋의 공개는 자동정리증명 분야에 상당한 인프라 기여를 할 것으로 예상된다. 다만 정리 증명의 절대 성능은 여전히 제한적이며, 고급 수학으로의 확장 가능성 검증이 필요하다.