저자: Xinna Lin, Siqi Ma, Junjie Shan, Xiaojing Zhang, Shell Xu Hu, Tiannan Guo, Stan Z. Li, Kaicheng Yu | 날짜: 2024 | DOI: arXiv:2407.00466
Essence
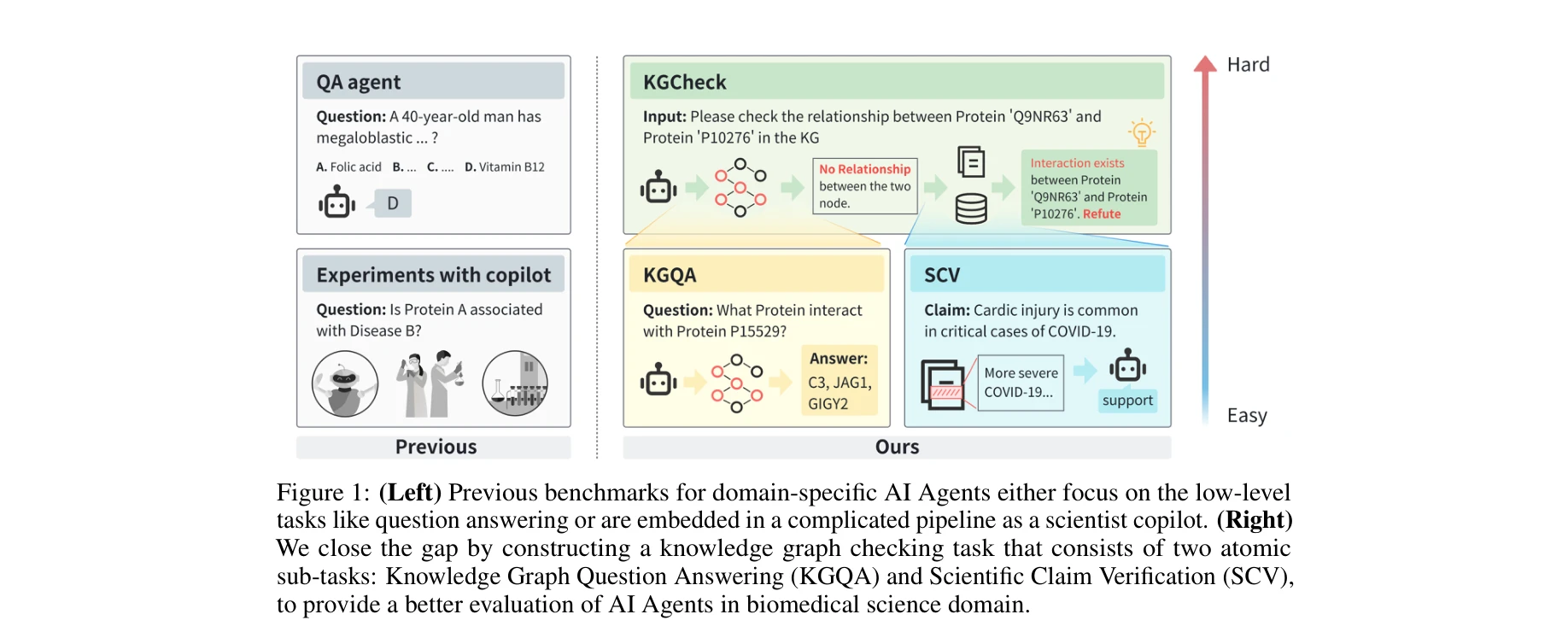
그림 1: (좌) 기존 도메인 특화 AI 에이전트 벤치마크는 질의응답(QA) 같은 저수준 작업에만 집중하거나 과학자 코파일럿 복잡 파이프라인에 내재됨. (우) 본 논문은 지식그래프 질의응답(KGQA)과 과학 주장 검증(SCV)의 두 가지 원자적(atomic) 부작업으로 구성된 지식그래프 검증(KGCheck) 작업을 통해 생의학 AI 에이전트 평가의 격차를 해소함.
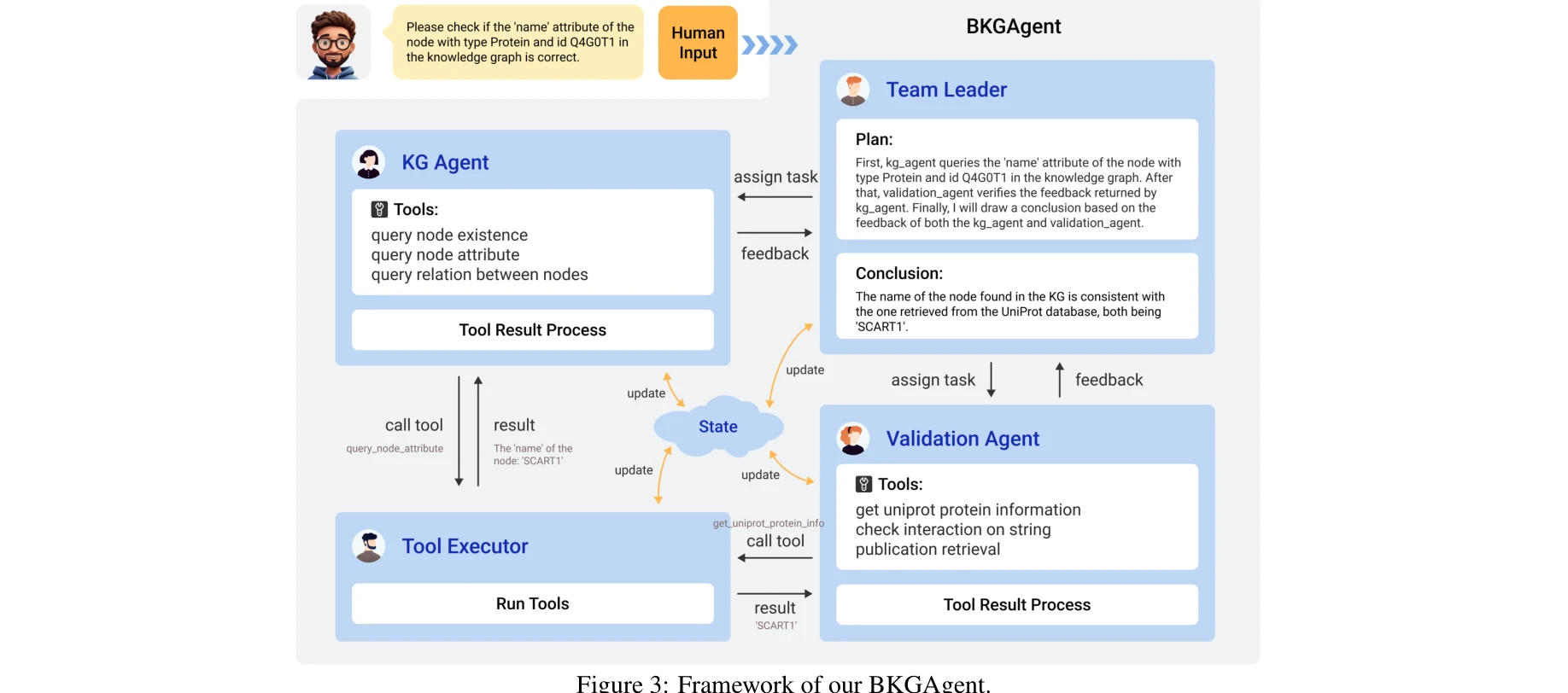
본 논문은 생의학 분야 AI 에이전트의 문헌 이해 능력을 평가하기 위해 BioKGBench 벤치마크를 제안한다. 기존 LLM 기반 평가의 환각(hallucination) 문제를 극복하기 위해 구조화된 지식그래프와 비구조화된 학술논문을 모두 활용하는 혼합형 평가 프레임워크를 도입한다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4/5 Significance: 4.5/5 Clarity: 4/5 Overall: 4.25/5
총평: 본 논문은 생의학 AI 에이전트 평가의 중요한 공백을 메우며, 구조화된 지식그래프와 비구조화된 학술논문을 통합하는 혁신적인 벤치마크를 제시한다. 실제 과학 업무를 반영한 설계와 90개 이상의 지식베이스 오류 발견을 통해 실질적 가치를 입증했으나, 부분그래프 사용과 이진 분류 중심의 평가 설계는 추가 확장의 여지를 남긴다.