Essence
BIA의 입력 처리, 생성 과정, 응답 평가, 피드백 루프, 전달의 5단계 워크플로우
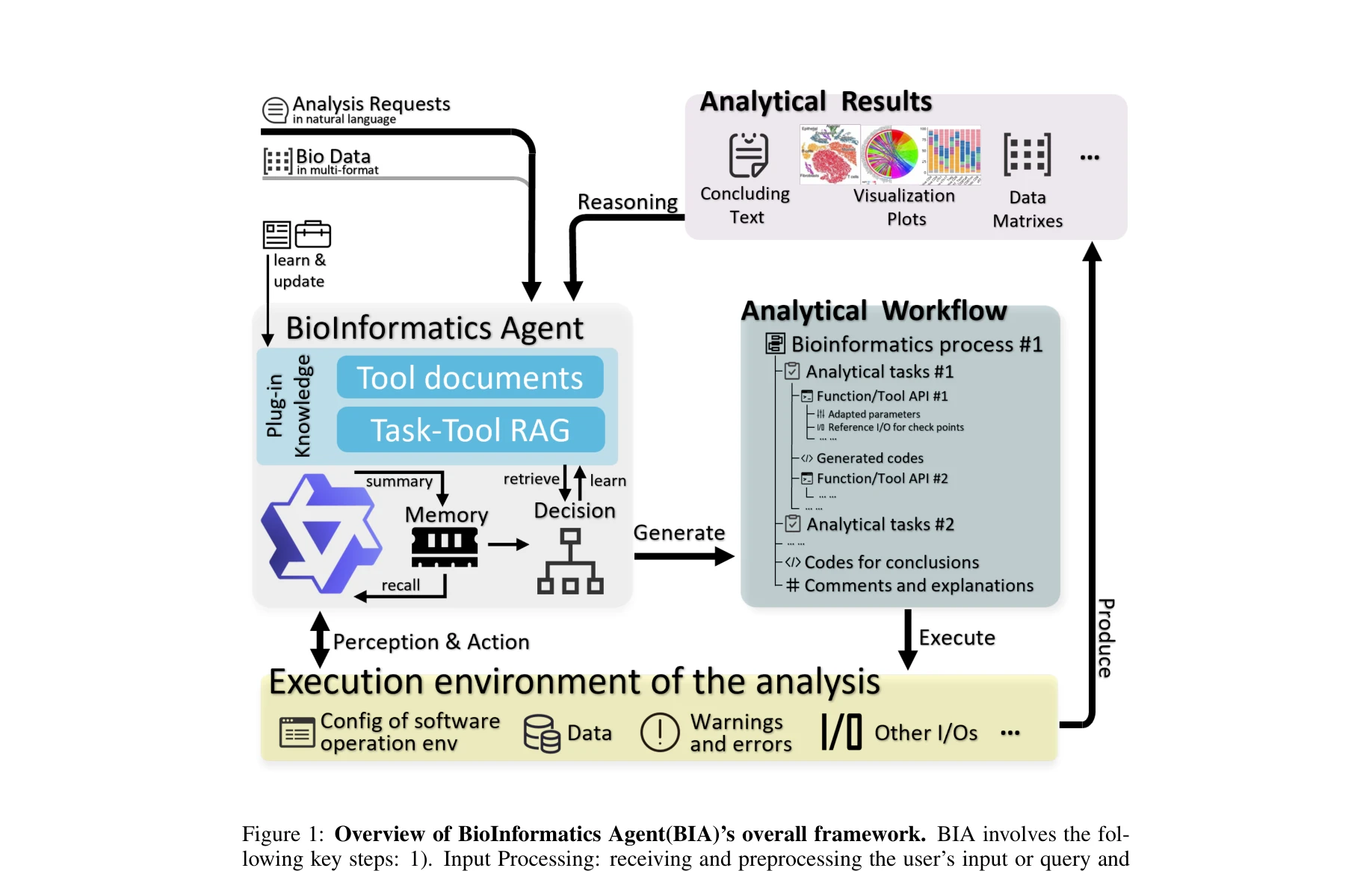
대규모 언어모델(LLM) 기반 생물정보학 에이전트(BIA)를 개발하여 자연어 대화를 통해 단일세포 RNA 시퀀싱(scRNA-seq) 데이터의 자동 분석 파이프라인을 실현했다. 사용자는 복잡한 프로그래밍 없이 생물정보학 분석의 전체 과정을 수행할 수 있다.
저자: Q. Xin, Quyu Kong, Hongyi Ji, Yue Shen, Yuqi Liu | 날짜: 2024 | DOI: 10.1101/2024.05.22.595240
BIA의 입력 처리, 생성 과정, 응답 평가, 피드백 루프, 전달의 5단계 워크플로우
대규모 언어모델(LLM) 기반 생물정보학 에이전트(BIA)를 개발하여 자연어 대화를 통해 단일세포 RNA 시퀀싱(scRNA-seq) 데이터의 자동 분석 파이프라인을 실현했다. 사용자는 복잡한 프로그래밍 없이 생물정보학 분석의 전체 과정을 수행할 수 있다.

BIA의 데이터셋 검색 및 획득 프로세스
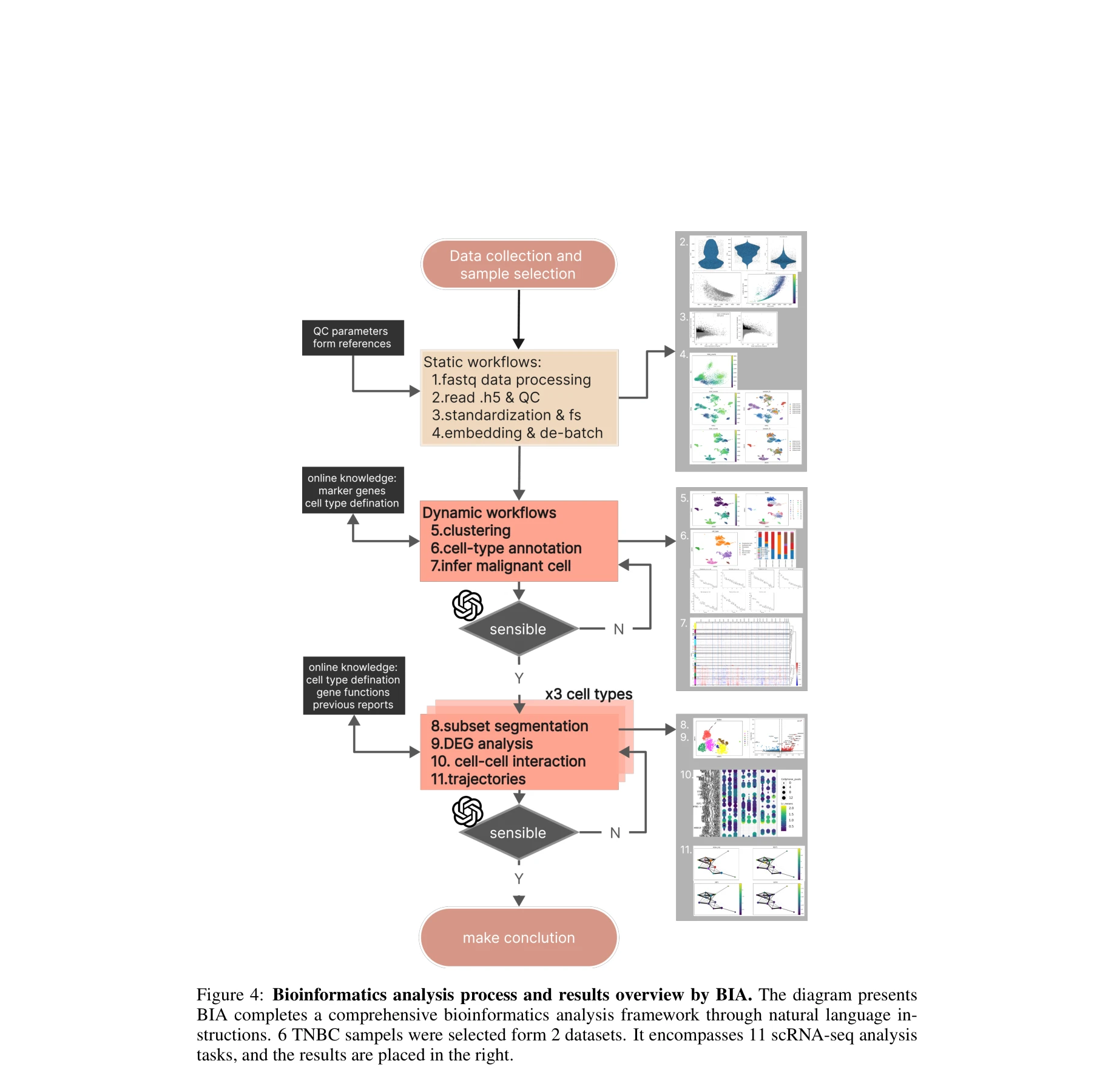
데이터 처리부터 분석 결과 도출까지의 전체 파이프라인
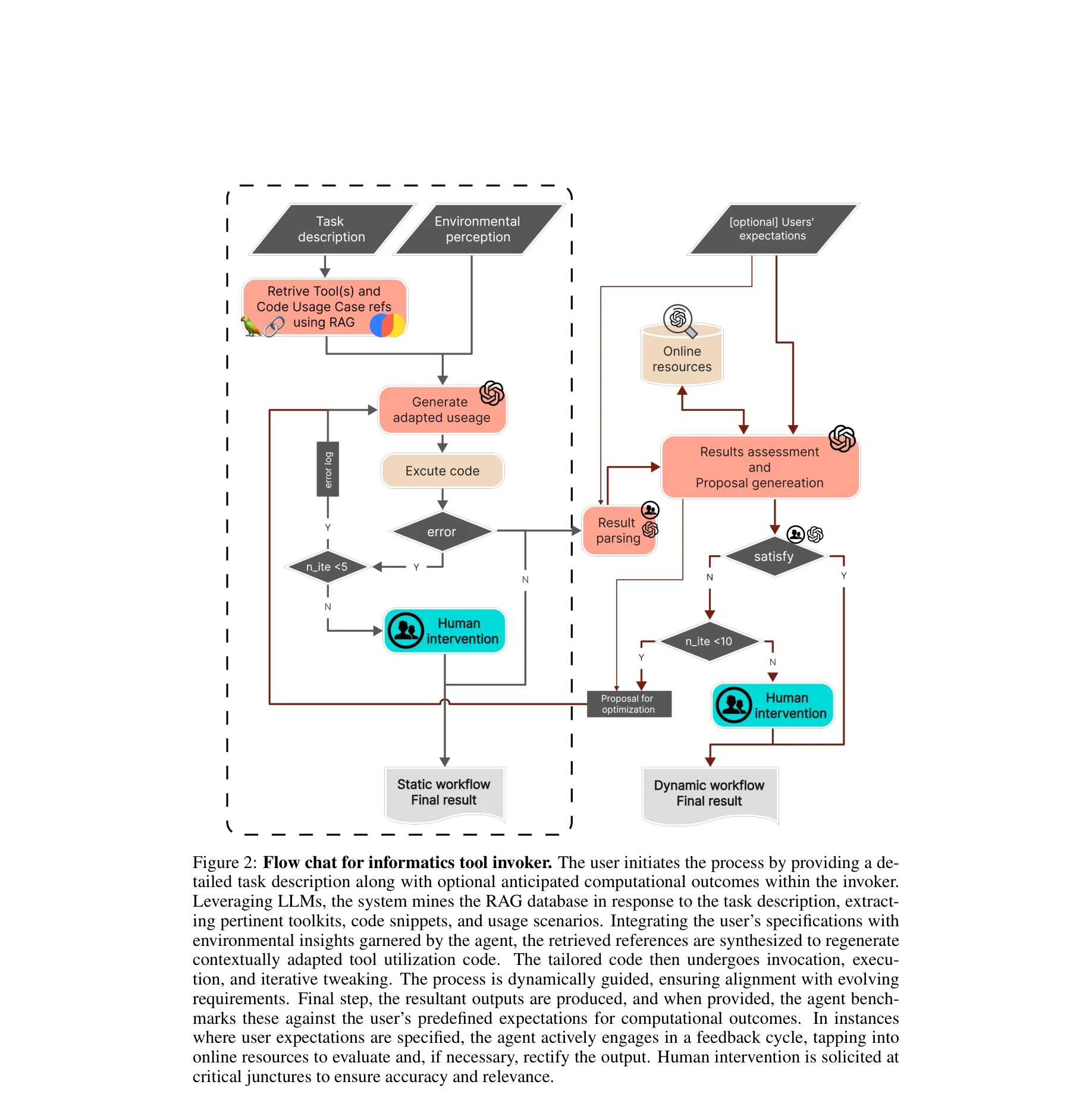
Thought-Action-Observation 루프를 통한 도구 선택 및 실행 메커니즘
search_online_db(query): 공개 저장소에서 메타정보 기반 샘플 검색download_online_db(ids): ID 기반 데이터 및 메타데이터 다운로드metadata_extraction(ids): 전문가가 정의한 필드로 비정형 텍스트에서 구조화 정보 추출총평: BIA는 LLM을 생물정보학 분석에 창의적으로 적용하여 사용자 진입 장벽을 획기적으로 낮출 수 있는 실용적 도구를 제시했으나, 성능 검증의 엄격함 부족과 단일 데이터 모달리티에 대한 제한으로 인해 현재로서는 개념 입증(proof of concept) 수준으로 평가된다.