Essence
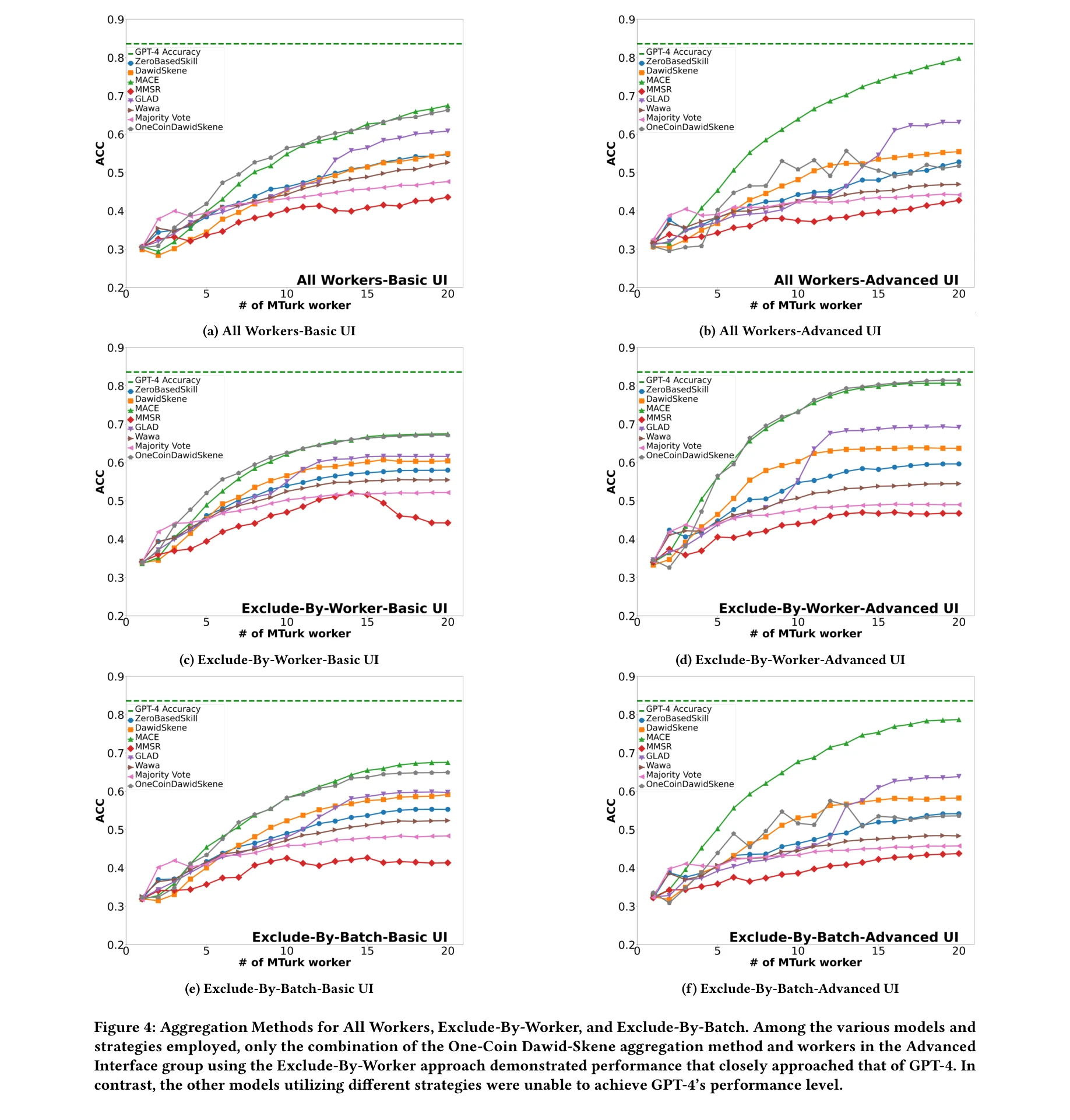
Figure 4: Aggregation Methods for All Workers, Exclude-By-Worker, and Exclude-By-Batch. Among the various models and
GPT-4와 최적화된 크라우드소싱 파이프라인의 데이터 라벨링 능력을 비교한 연구로, GPT-4가 개별 성능에서 우수하지만 라벨 집계(Label Aggregation)를 통해 크라우드 라벨과 결합하면 더 높은 정확도를 달성할 수 있음을 보여줌.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 기존 GPT-4 vs 크라우드 워커 비교 연구의 방법론적 문제점을 충실히 해결하면서, 최적화된 크라우드소싱 파이프라인의 정확성을 검증하고 GPT-4와의 하이브리드 접근이 더 나은 성능을 제공할 수 있음을 입증했다는 점에서 높은 학술적 가치를 가짐. 특히 LLM 시대 크라우드소싱의 새로운 역할을 제시한 중요한 연구임.