How
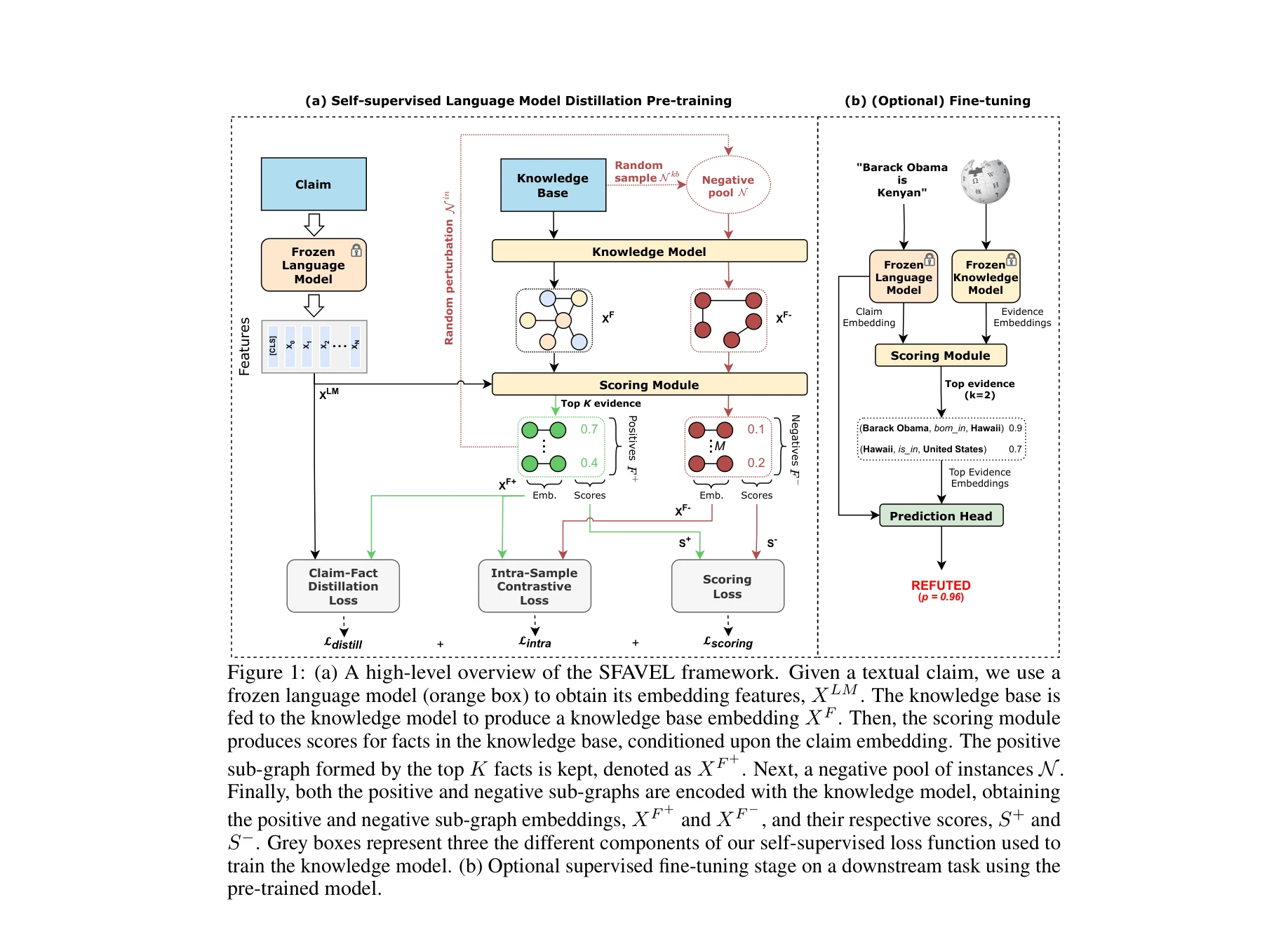
데이터 처리 파이프라인:
- 미표지 클레임 배치 x = {xᵢ}ₙᵢ₌₁과 지식그래프 G(ε, R) (엔티티와 관계 포함) 사용
- 사실 F는 (head, relation, tail) 삼중항으로 표현
사전학습 방법론:
- 언어모델 인코더(Frozen): 입력 클레임으로부터 X_LM 특징 획득 (8개 SOTA 사전학습 모델 중 선택)
- 지식모델: 지식그래프의 모든 사실을 고차원 임베딩 X_F로 변환
- 스코어링 모듈: 클레임 임베딩을 조건으로 하여 각 사실에 대한 점수 S ∈ [0,1] 생성
- 상위-K 증거 선택: 점수가 높은 상위 K개 사실을 양성 부분그래프 X_F⁺로 선택
- 음성 풀: 임의로 샘플링된 사실들로 음성 풀 구성
세 가지 손실함수 조합:
- 증류 손실(ℒ_distill): 클레임과 양성 사실 임베딩 간 대비 손실로 언어모델 지식을 지식모델 공간으로 증류
- 스코어링 손실(ℒ_scoring): 양성 사실에 높은 점수, 음성 사실에 낮은 점수를 부여하도록 스코어링 모듈 학습
- 대비 손실(ℒ_intra): 동일 클레임의 양성 사실들 간 의미 관계 보존, 코사인 유사도 기반 대비 학습
선택적 미세조정: 사전학습된 모델을 지도학습 팩트 검증 분류 작업에 미세조정 가능