Essence
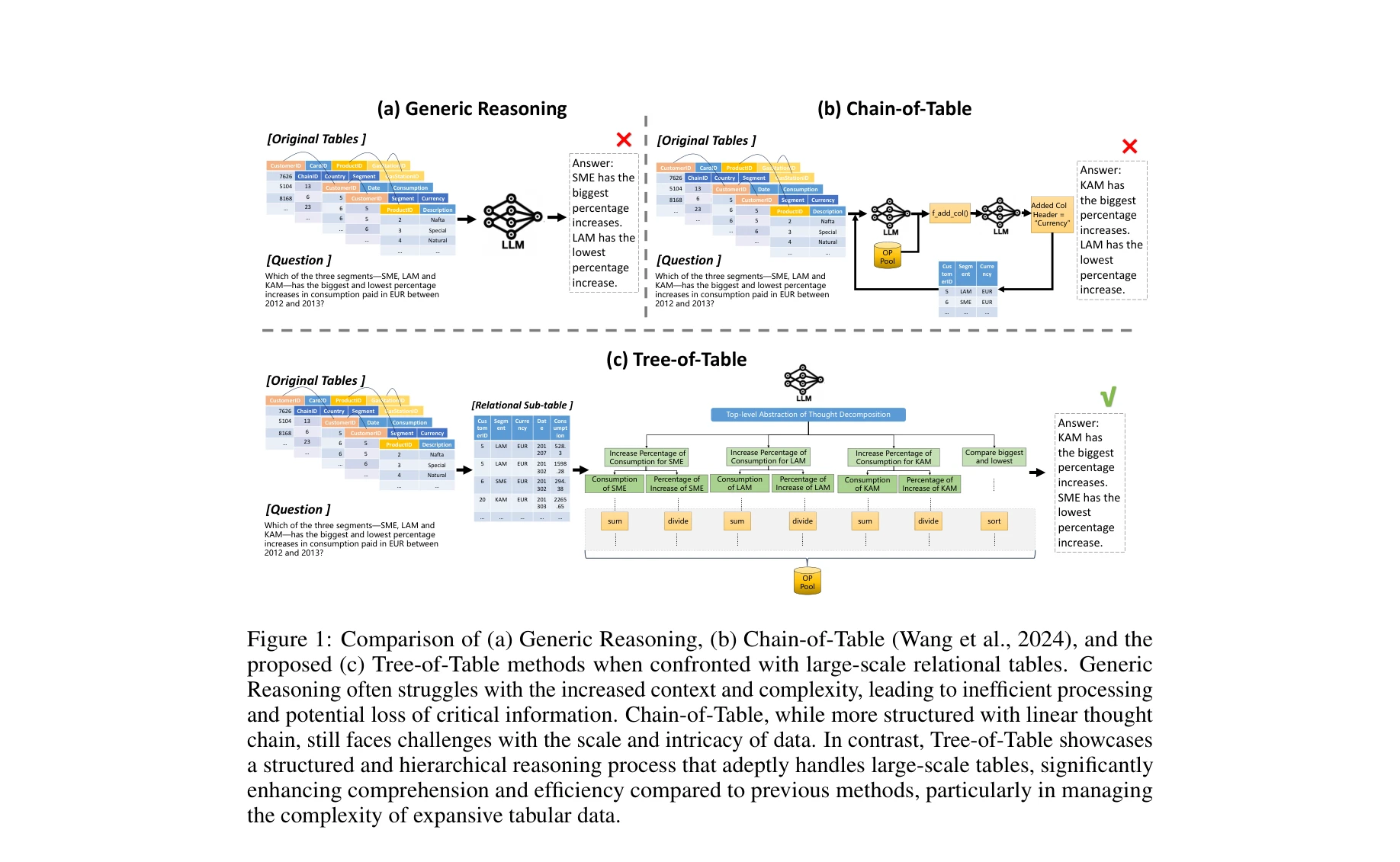
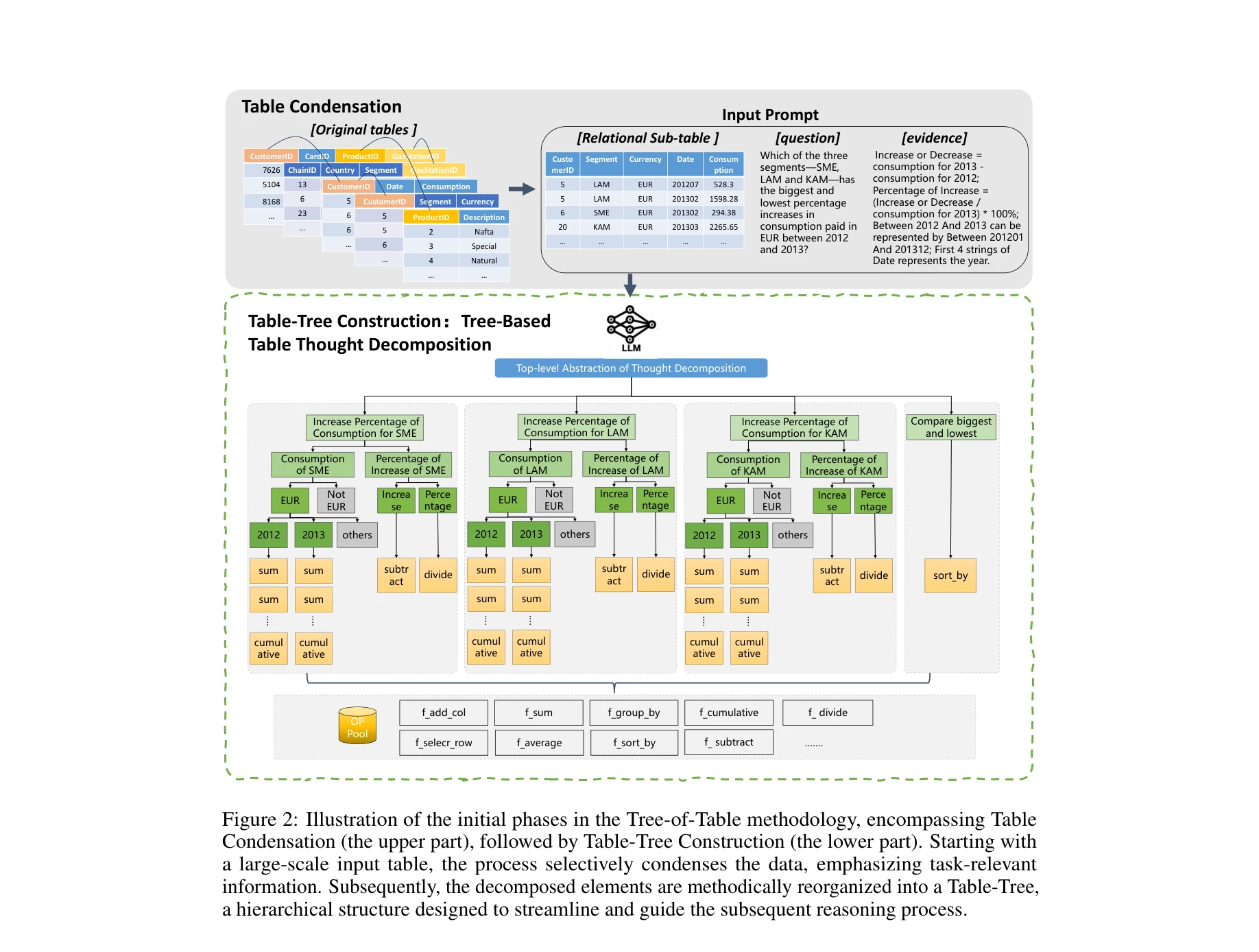
그림 1: (a) 일반적 추론, (b) Chain-of-Table, (c) 제안된 Tree-of-Table 방법의 비교. Tree-of-Table은 대규모 관계형 테이블에 대해 계층적이고 구조화된 추론 프로세스를 통해 우수한 성능을 보여줌
대규모 테이블 이해를 위해 테이블 응축 및 분해를 통해 관련 정보를 추출한 후, 계층적 Table-Tree를 구성하여 트리 구조 추론을 수행하는 새로운 방법론을 제시한다. 이는 기존의 선형 체인 기반 방식의 한계를 극복하고 복잡한 다중 테이블 관계를 효과적으로 처리한다.