저자: Shashank Subramanian, P. Harrington, K. Keutzer, W. Bhimji, D. Morozov, M. W. Mahoney, Amir Gholami | 날짜: 2023 | DOI: 10.48550/arXiv.2306.00258
Essence
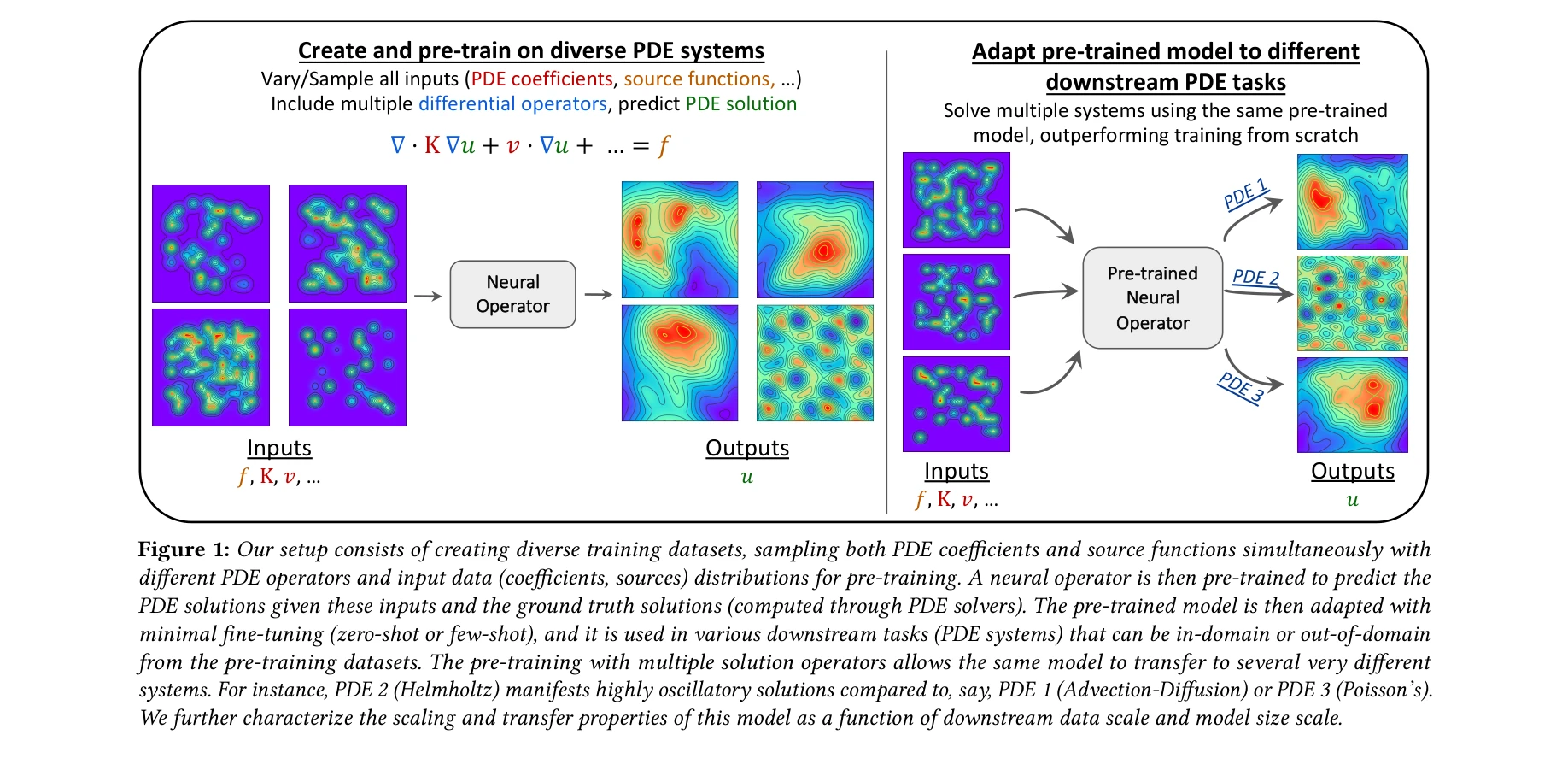
다양한 PDE 시스템에 대한 사전학습과 미세조정 프레임워크
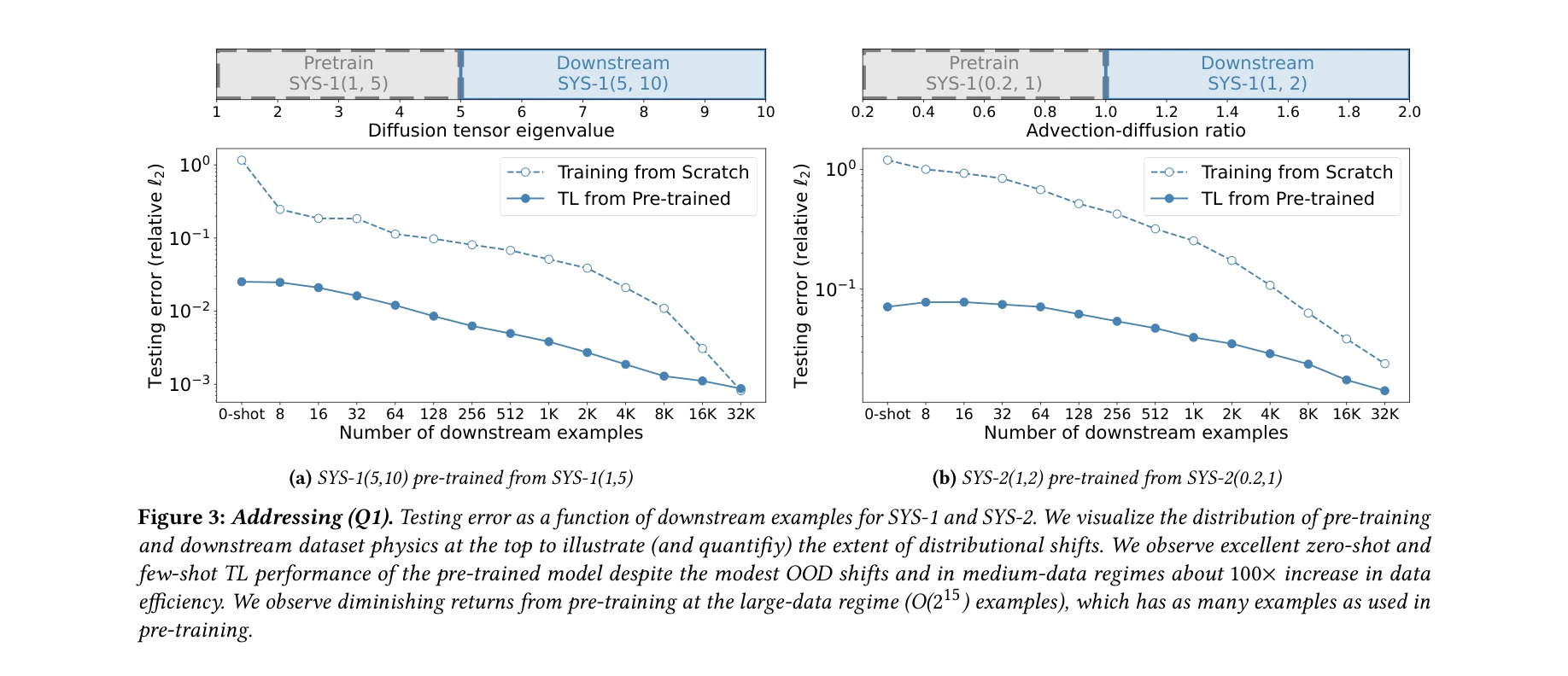
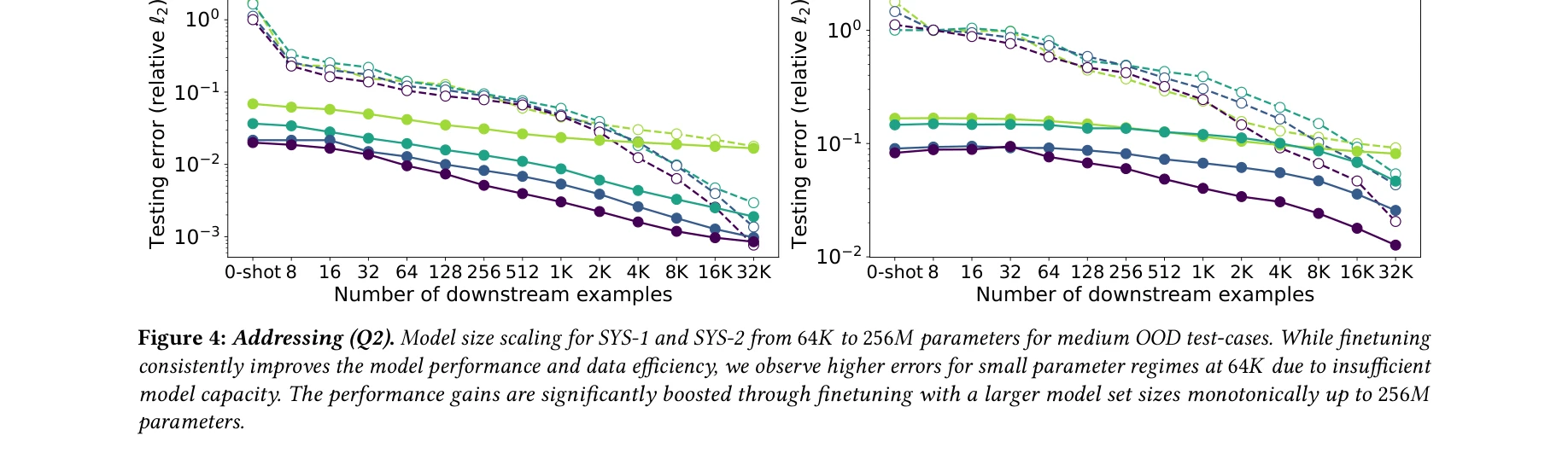
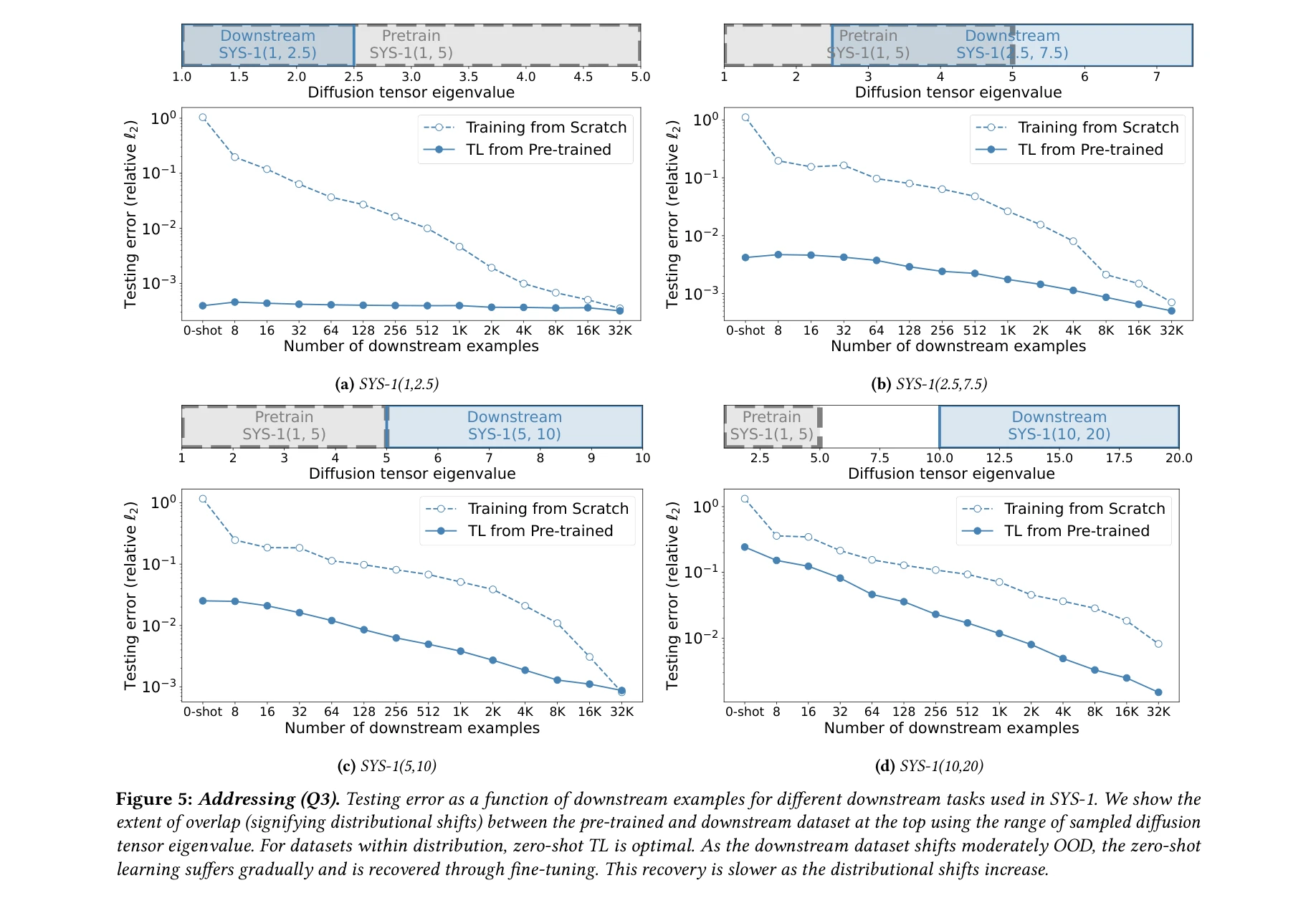
본 논문은 자연언어처리(NLP)와 컴퓨터비전(CV) 분야에서 성공적으로 활용된 파운데이션 모델 패러다임(사전학습-미세조정)을 과학 머신러닝(Scientific Machine Learning, SciML) 분야에 적용 가능한지 체계적으로 검증한다. 편미분방정식(PDE) 학습 작업에서 신경 연산자(Neural Operator)를 다양한 물리 시스템으로 사전학습한 후 미세조정하면, 처음부터 학습한 모델보다 수 자릿수 적은 데이터로 목표 정확도에 도달할 수 있음을 보인다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4/5 Significance: 4.5/5 Clarity: 4/5 Overall: 4.25/5
총평: 본 논문은 SciML 분야에서 파운데이션 모델 패러다임의 가능성을 처음으로 체계적으로 검증한 중요한 연구로, 모델 크기, 데이터 스케일, 물리 파라미터 범위, 다중 연산자 등 여러 차원의 종합 분석을 통해 전이학습의 강력한 이점을 명확히 보인다. 다만 단일 아키텍처와 상대적으로 단순한 PDE 시스템에 국한되었으며, 실제 과학 응용으로의 확장과 물리 기반 제약의 통합이 향후 과제이다. SciML 커뮤니티에 중요한 벤치마크와 로드맵을 제시하는 점에서 의의가 크다.