Essence
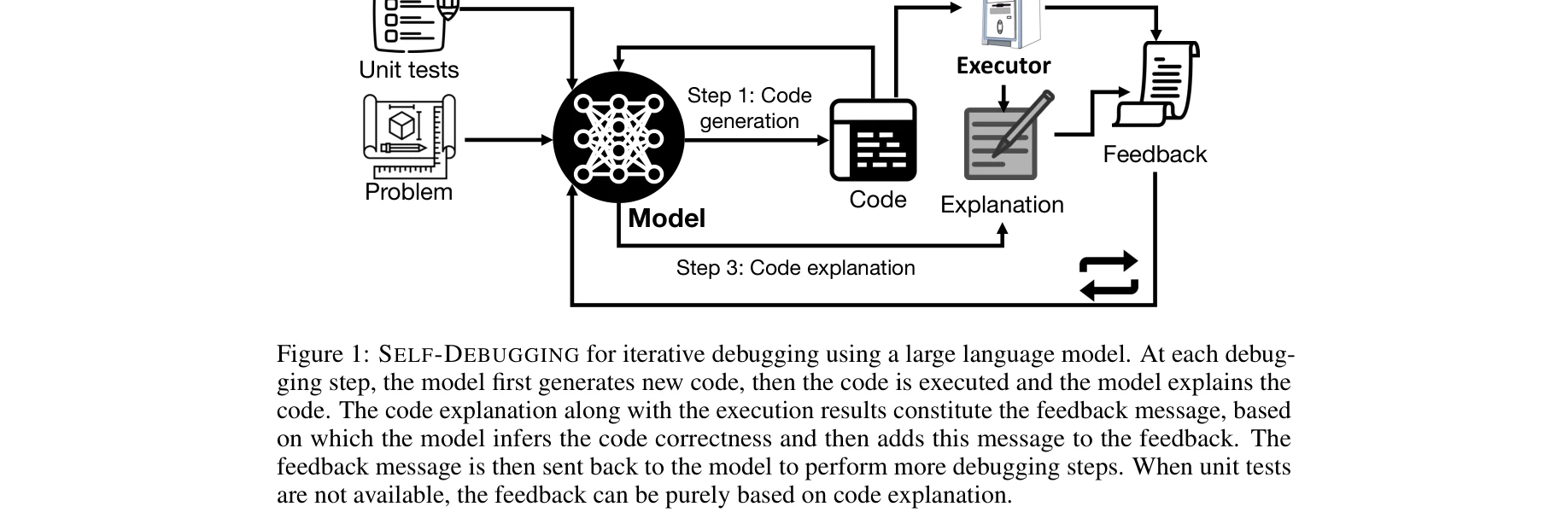
SELF-DEBUGGING의 반복적 디버깅 프로세스: 코드 생성(Step 1) → 코드 실행(Step 2) → 코드 설명(Step 3) → 피드백 생성 단계
본 논문은 대규모 언어 모델(LLM)이 몇 가지 시연(few-shot demonstration)을 통해 자신이 생성한 코드를 자동으로 디버깅하도록 가르치는 SELF-DEBUGGING 기법을 제시한다. 외부 피드백 없이 코드 설명과 실행 결과 분석을 통해 오류를 식별하는 "러버덕 디버깅(rubber duck debugging)" 방식의 자체 수정이 가능함을 보인다.

