Essence
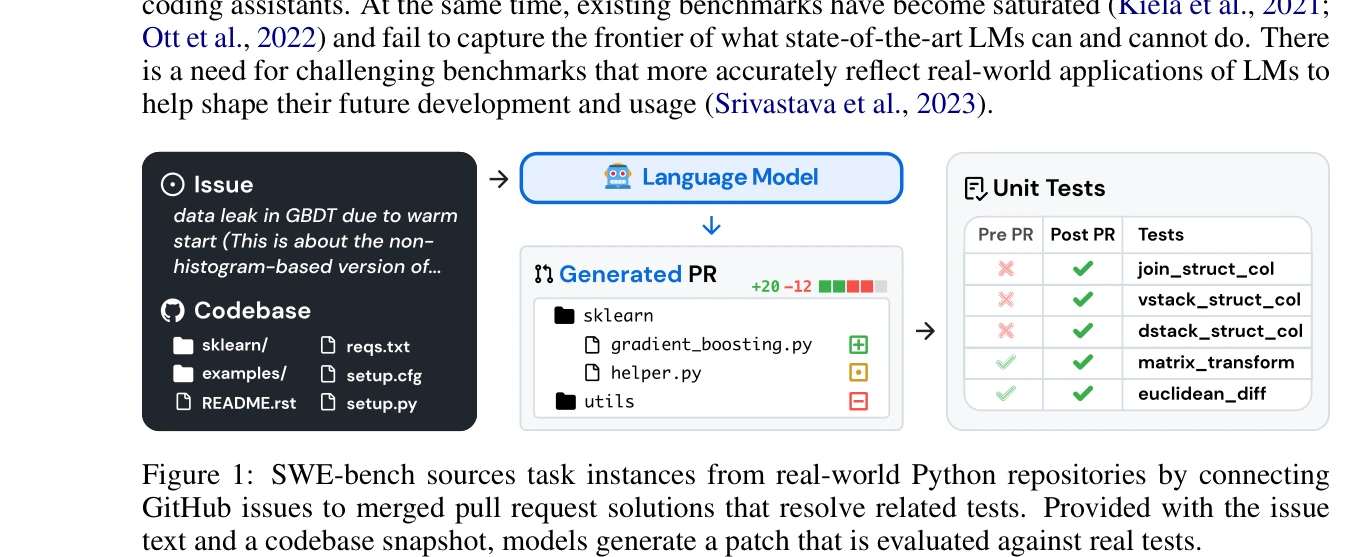
Figure 1: SWE-bench는 GitHub 이슈를 실제 코드베이스와 함께 제시하여 언어 모델이 생성한 패치를 단위 테스트로 검증하는 방식으로 작동
실제 GitHub 이슈 2,294개를 기반으로 한 소프트웨어 엔지니어링 벤치마크 SWE-bench를 제시하며, 최고 성능 모델(Claude 2)도 1.96%의 낮은 해결율만 달성하여 대규모 언어 모델의 실제 소프트웨어 엔지니어링 능력의 한계를 명확히 드러낸다.
저자: Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, Karthik Narasimhan | 날짜: 2024-11-11 | DOI: 10.48550/arXiv.2310.06770
Figure 1: SWE-bench는 GitHub 이슈를 실제 코드베이스와 함께 제시하여 언어 모델이 생성한 패치를 단위 테스트로 검증하는 방식으로 작동
실제 GitHub 이슈 2,294개를 기반으로 한 소프트웨어 엔지니어링 벤치마크 SWE-bench를 제시하며, 최고 성능 모델(Claude 2)도 1.96%의 낮은 해결율만 달성하여 대규모 언어 모델의 실제 소프트웨어 엔지니어링 능력의 한계를 명확히 드러낸다.

Figure 2: 3단계 데이터 파이프라인: (1) 인기 리포지토리 90,000개 PR 수집 → (2) 이슈 해결 + 테스트 기여 PR 필터링 → (3) 실행 기반 필터링으로 2,294개 최종 작업 구성

Figure 3: 12개 리포지토리별 작업 분포 (django 850개가 가장 많고, flask 11개가 가장 적음)
patch 유틸리티로 패치 적용 후 모든 테스트 통과 확인 (fail-to-pass + 회귀 테스트 ~51개)총평: SWE-bench는 기존 코딩 벤치마크의 인공성을 벗어나 실제 GitHub 이슈 해결을 통해 언어 모델의 실무 소프트웨어 엔지니어링 능력을 엄격하게 평가하는 중요한 작업이며, 공개 데이터셋과 자동화된 확장성으로 장기적 학술 가치가 높다. 다만 검색 기반 접근과 초기 평가 모델 제한은 개선 여지가 있다.