저자: Xun Liang, Jiawei Yang, Yezhaohui Wang, Chen Tang, Zifan Zheng, Shichao Song, Zehao Lin, Yebin Yang, Simin Niu, Hanyu Wang, Bo Tang, Feiyu Xiong, Keming Mao, Zhiyu Li | 날짜: 2025 | DOI: arXiv:2502.14776
Essence
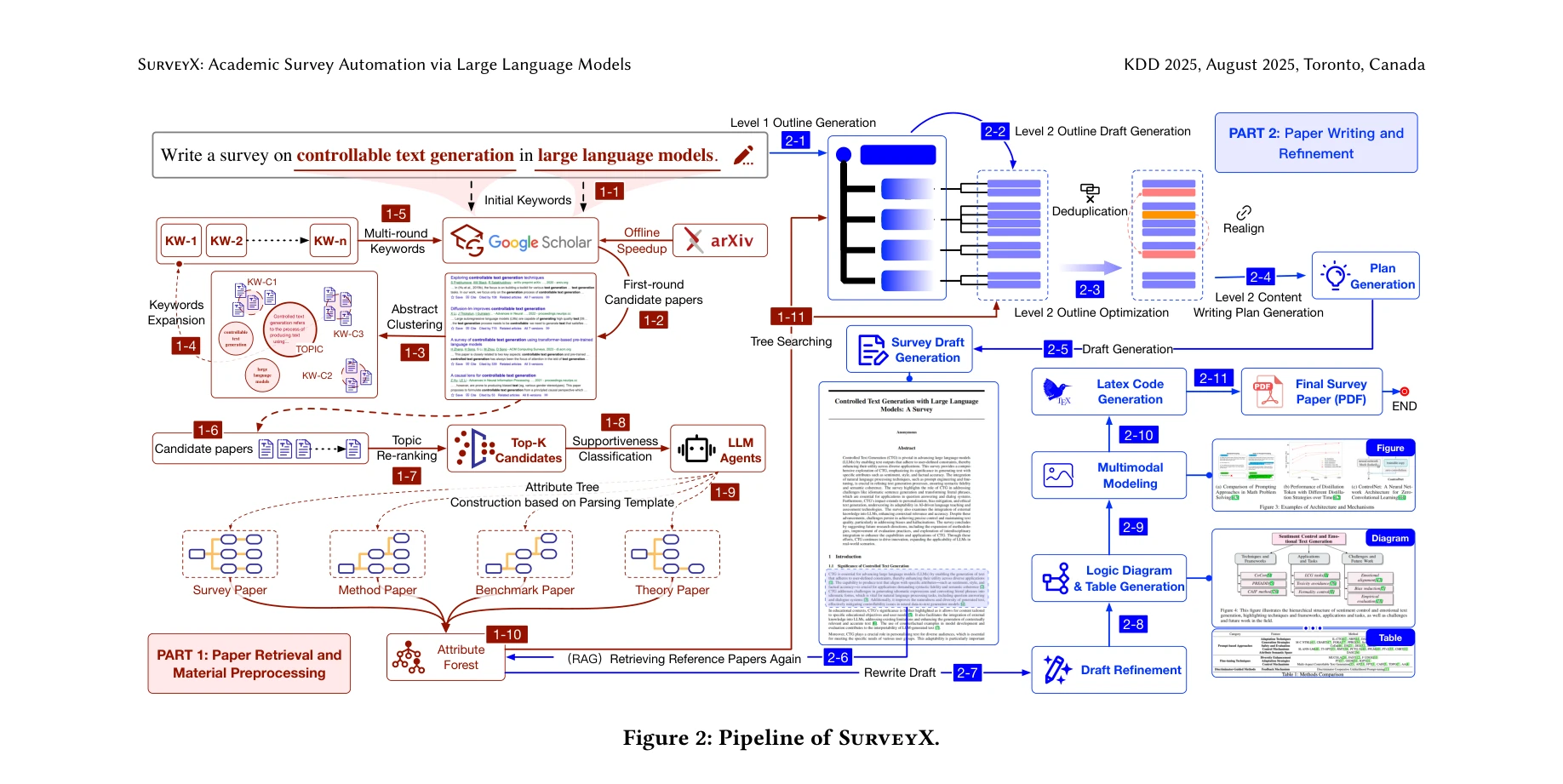
SurveyX의 전체 파이프라인: 준비 단계(Part 1: 논문 검색 및 자료 전처리)와 생성 단계(Part 2: 논문 작성 및 개선)로 구성
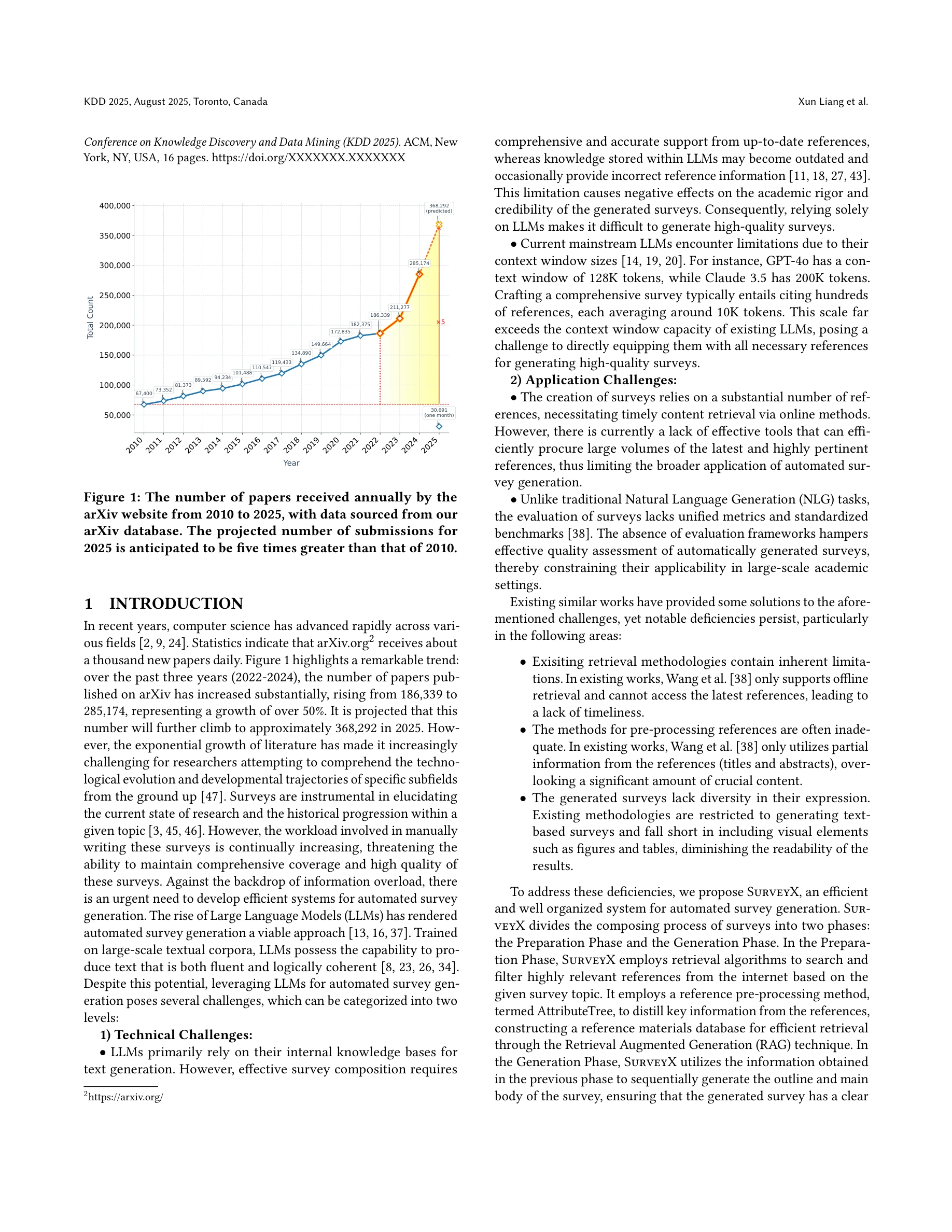
arXiv에 매년 증가하는 학술 논문의 폭증 속에서, 대형언어모델(LLM)을 활용하여 체계적이고 고품질의 학술 서베이를 자동 생성하는 SurveyX 시스템을 제안한다. 이 시스템은 온라인 참고문헌 검색, AttributeTree 전처리 방법, 그리고 다단계 최적화를 통해 기존 자동 서베이 생성 시스템의 한계를 극복한다.
How
SurveyX 파이프라인의 상세 구성: Part 1은 11단계, Part 2는 11단계로 순차적으로 진행
준비 단계 (Preparation Phase):
- 키워드 확장 (1-4단계): 초기 주제에서 출발하여 관련 키워드를 다단계로 확장하여 검색 범위 극대화
- 온라인 검색 및 필터링 (1-5~1-9단계): 다중 라운드 키워드로 후보 논문 검색, 클러스터링, 재순위 지정, 지지도(Supportiveness) 분류로 고품질 논문만 선별
- AttributeTree 구성 (1-10~1-11단계): 파싱 템플릿 이론 기반으로 논문의 핵심 속성을 트리 구조로 추출하여 정보 밀도 향상 및 토큰 효율성 증대
생성 단계 (Generation Phase):
- 개요 생성 (2-1~2-4단계): Level 1 개요(주요 섹션) 생성 후, Level 2 개요(소단계) 생성, 최적화 단계에서 중복 제거 및 논리적 재정렬
- 콘텐츠 작성 (2-5~2-7단계): RAG(Retrieval Augmented Generation) 기법으로 관련 논문 재검색, 초안 생성 후 세밀한 재작성으로 품질 향상
- 멀티모달 모델링 (2-8~2-10단계): 논리 다이어그램, 표, 그림 생성 및 LaTeX 코드 변환으로 최종 PDF 생성
Evaluation
총평: SurveyX는 LLM 기반 자동 서베이 생성의 실용적 한계를 체계적으로 해결하고, 온라인 검색, 지능형 전처리, 멀티모달 확장을 통해 기존 AutoSurvey 대비 명확한 성능 향상을 입증한 의미 있는 연구이나, 평가의 포괄성과 방법론의 이론적 깊이 강화가 필요하다.