Essence
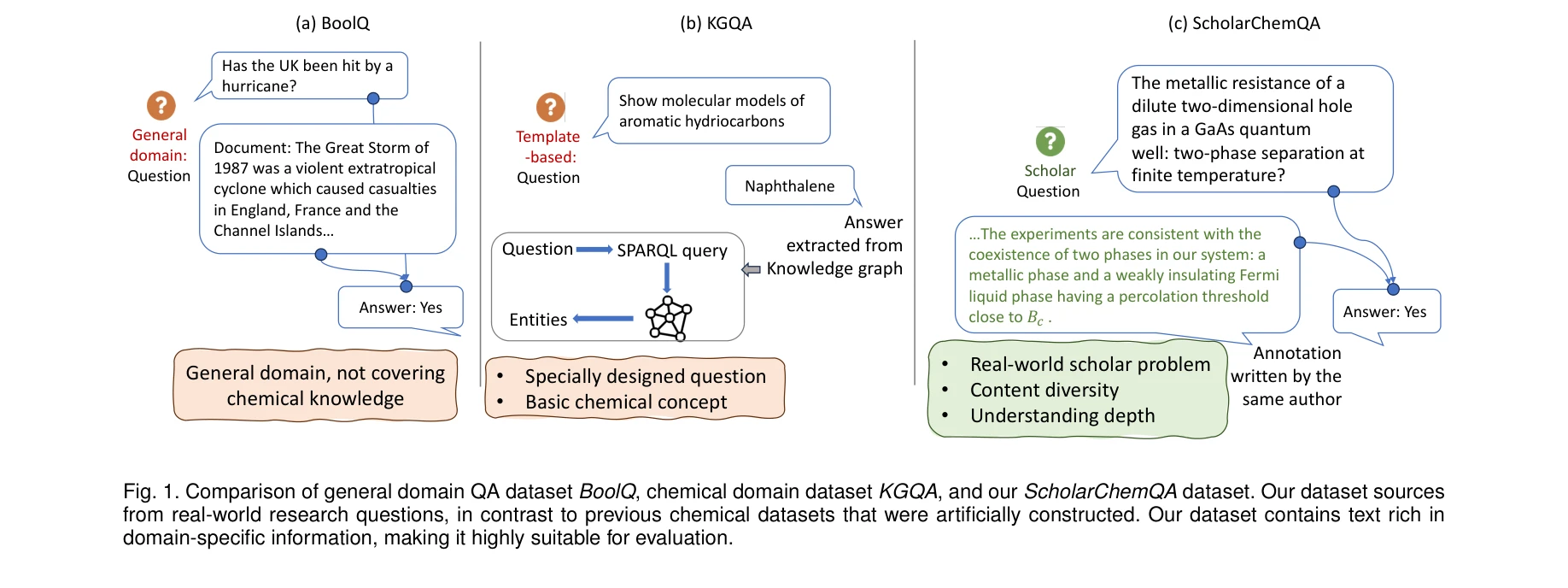
Figure 1: BoolQ(일반 도메인), KGQA(템플릿 기반 화학), ScholarChemQA(실제 논문 기반) 비교
화학 학술 논문으로부터 구성된 첫 대규모 화학 QA 데이터셋 ScholarChemQA를 제시하고, 불균형한 라벨 분포와 대량의 미표지 데이터를 다루는 QAMatch 모델을 제안하여 LLM을 능가하는 성능을 달성했다.
저자: Xiuying Chen, Tairan Wang, Taicheng Guo, Kehan Guo, Juexiao Zhou, Haoyang Li, Mingchen Zhuge, Jürgen Schmidhuber, Xin Gao, Xiangliang Zhang | 날짜: 2024 | DOI: arXiv:2407.16931
Figure 1: BoolQ(일반 도메인), KGQA(템플릿 기반 화학), ScholarChemQA(실제 논문 기반) 비교
화학 학술 논문으로부터 구성된 첫 대규모 화학 QA 데이터셋 ScholarChemQA를 제시하고, 불균형한 라벨 분포와 대량의 미표지 데이터를 다루는 QAMatch 모델을 제안하여 LLM을 능가하는 성능을 달성했다.
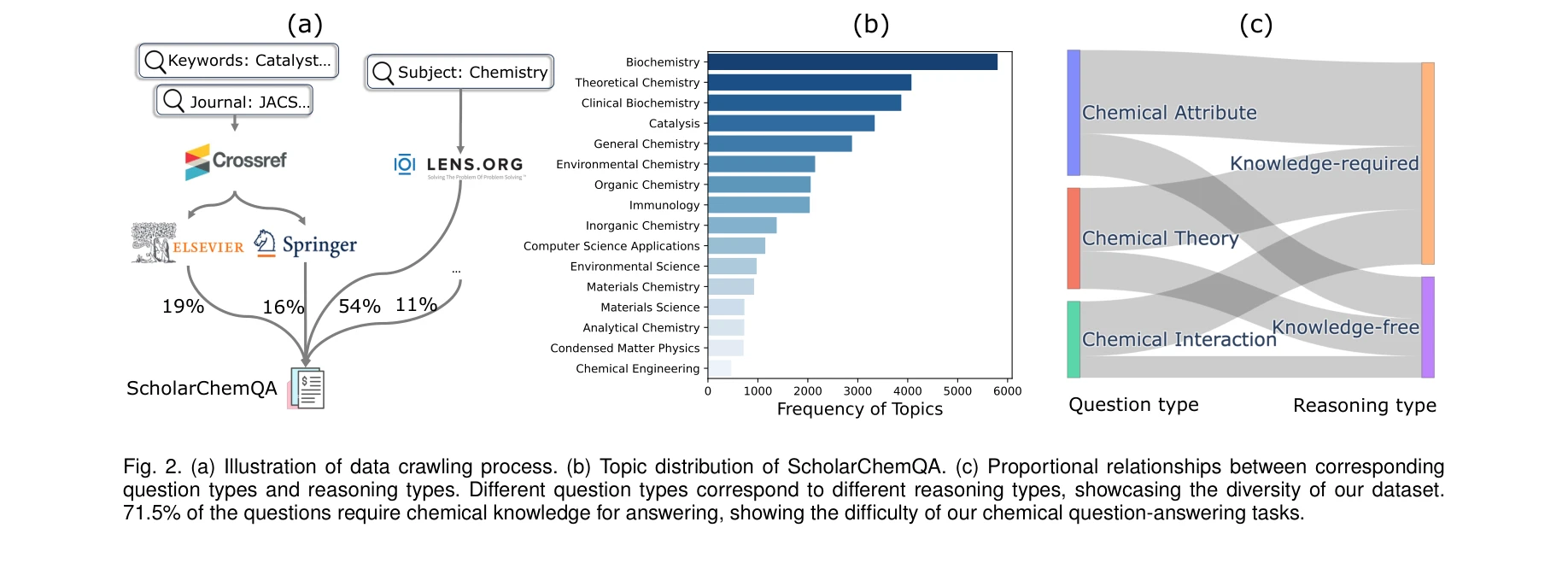
Figure 2: (a) 데이터 크롤링 프로세스 (b) ScholarChemQA의 주제 분포 (c) 라벨 비율 관계
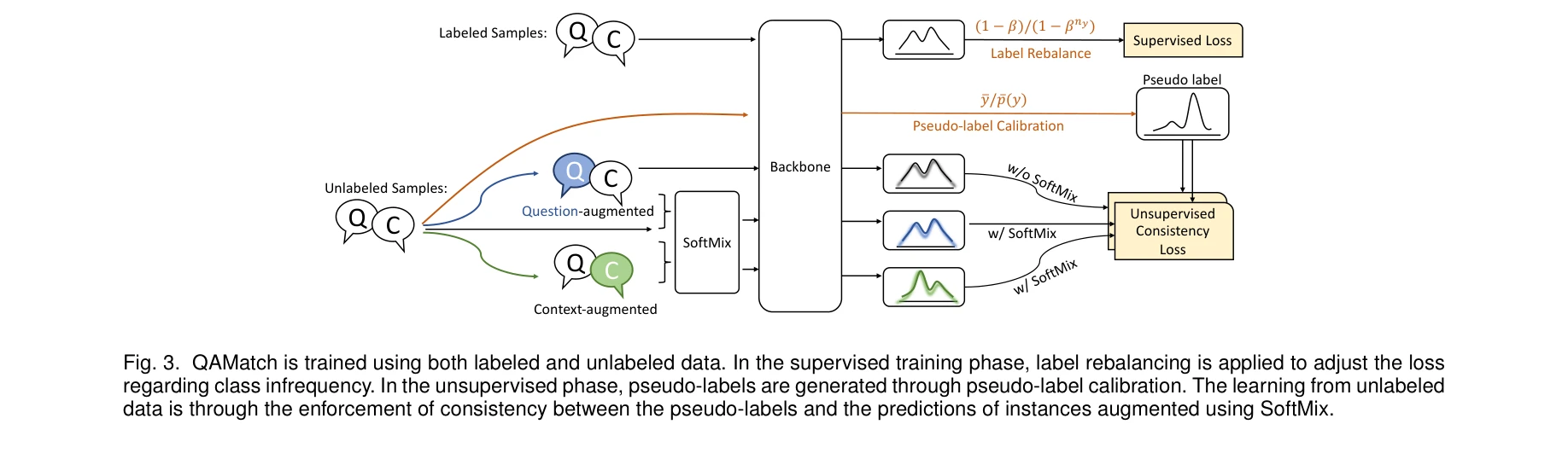
Figure 3: QAMatch의 지도학습(label rebalancing) 및 반지도학습 구조
총평: ScholarChemQA는 학술 화학 분야의 진정한 QA 벤쌍을 제공하고, QAMatch는 반지도학습과 라벨 불균형을 다루는 실용적 솔루션을 제시한다. 화학 분야뿐 아니라 도메인 특화 QA 연구의 방향을 제시하는 의미 있는 기여이나, 데이터셋 규모와 모델 기법의 일반화 검증 측면에서 보완이 필요하다.