Essence
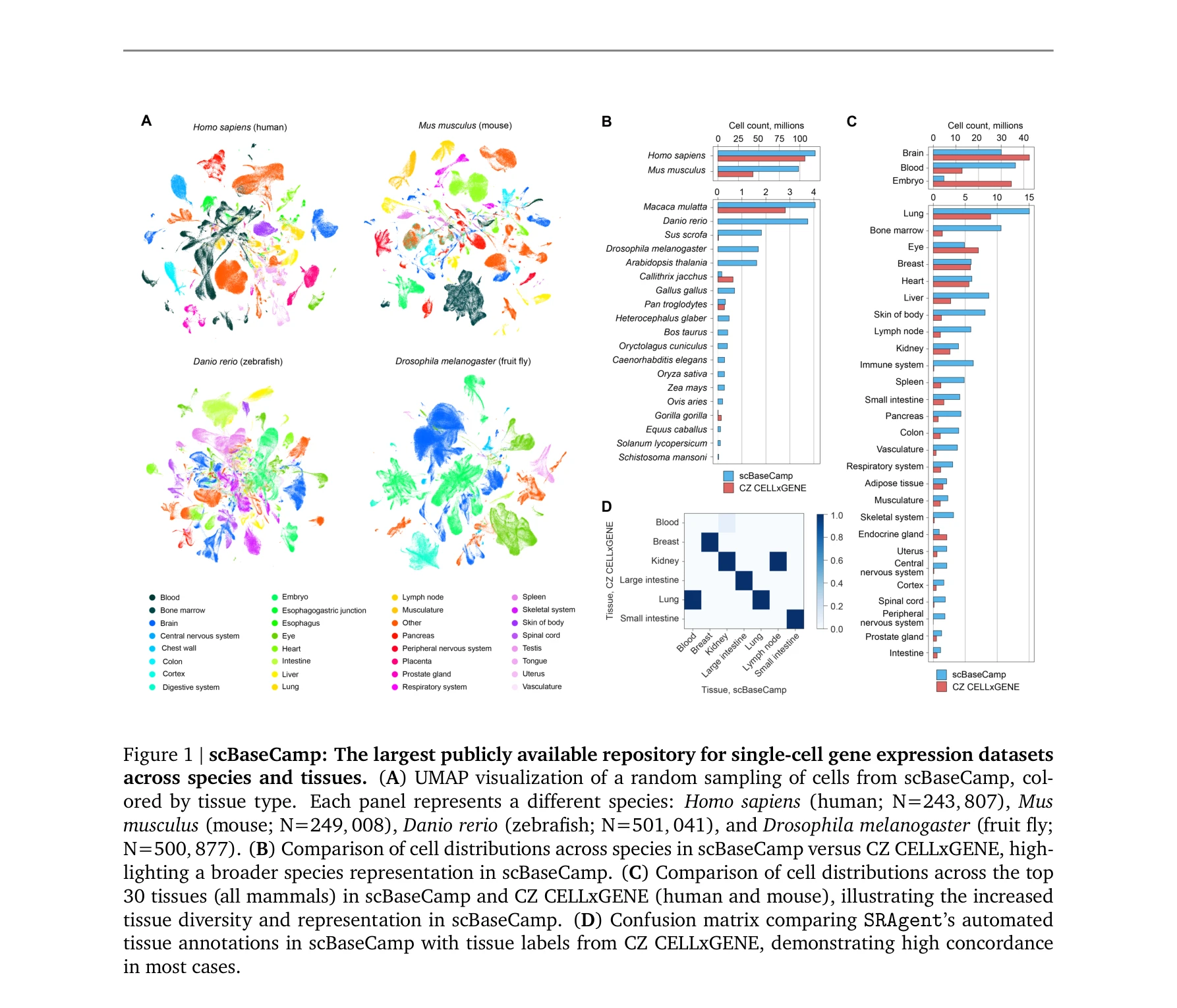
scBaseCamp은 종(species)과 조직(tissue)에 걸쳐 2억 3천만 개 이상의 세포를 포함하는 가장 큰 공개 단일 세포 유전자 발현 데이터셋 저장소이다.
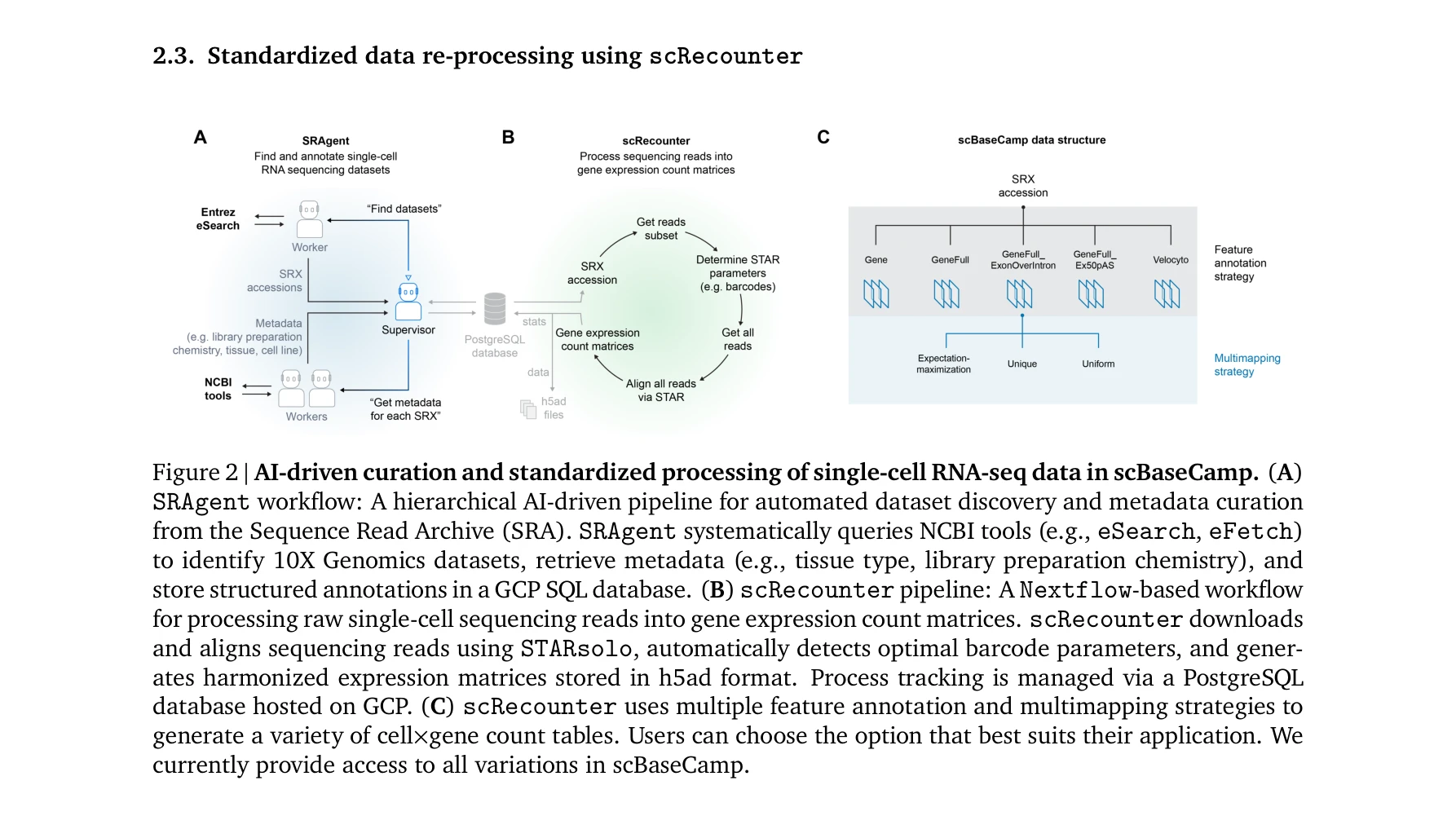
AI 에이전트 기반의 자동화된 워크플로우를 통해 공개 10X Genomics 단일세포 RNA 시퀀싱 데이터를 발굴하고 표준화된 방식으로 처리하여, 가장 규모가 크고 다양한 단일세포 데이터 저장소 scBaseCamp를 구축했다. 이는 AI 기반 가상세포 모델 개발을 위한 훈련 데이터로 활용될 수 있으며, 데이터 처리 파이프라인의 표준화를 통해 분석 아티팩트를 최소화한다.