Essence
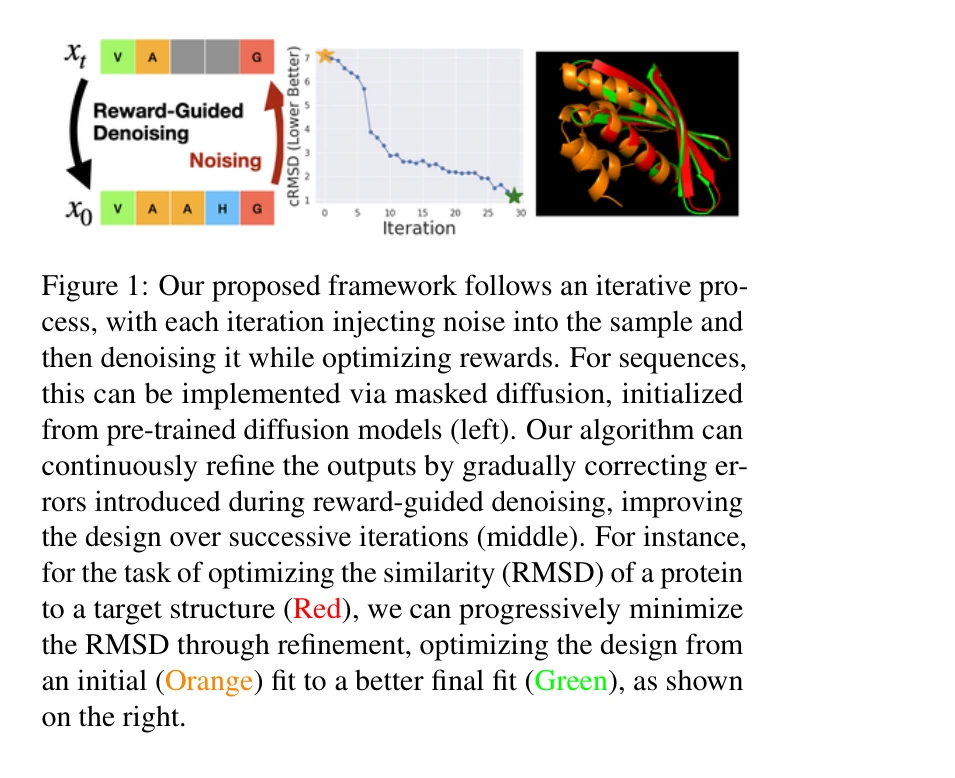
그림 1: 제안된 프레임워크는 반복적 과정을 따르며, 각 반복에서 샘플에 노이즈를 주입한 후 보상을 최적화하면서 디노이징하는 과정
본 논문은 확산 모델(Diffusion Models)에서 테스트 타임 보상 최적화를 위한 반복적 개선 프레임워크를 제안한다. 기존의 단일 샷(single-shot) 방식과 달리, 부분 노이징과 보상 유도 디노이징의 두 단계를 반복하여 점진적으로 설계(design)를 개선할 수 있다.
저자: Masatoshi Uehara, Xingyu Su, Yulai Zhao, Xiner Li, Aviv Regev | 날짜: 2025 | DOI: 10.48550/arXiv.2502.14944
그림 1: 제안된 프레임워크는 반복적 과정을 따르며, 각 반복에서 샘플에 노이즈를 주입한 후 보상을 최적화하면서 디노이징하는 과정
본 논문은 확산 모델(Diffusion Models)에서 테스트 타임 보상 최적화를 위한 반복적 개선 프레임워크를 제안한다. 기존의 단일 샷(single-shot) 방식과 달리, 부분 노이징과 보상 유도 디노이징의 두 단계를 반복하여 점진적으로 설계(design)를 개선할 수 있다.

그림 2: 기존 보상 유도 알고리즘은 소프트 최적 정책 {p⋆_t}로부터 순차적 샘플링으로 볼 수 있으며, 알고리즘의 차이는 p⋆_t 근사 방식에 있다

그림 3: RERD 알고리즘 요약 - 반복적으로 부분 노이징과 보상 유도 디노이징 수행
핵심 알고리즘 구조:
총평: 확산 모델의 테스트 타임 최적화에 혁신적인 반복 개선 접근을 제시하고, 특히 마스크 확산의 토큰 고정 문제 해결과 하드 제약조건 처리는 실질적 기여다. 단백질/DNA 설계에서 일관된 성능 향상을 보이나, 계산 효율성 분석 부재와 실제 생물학적 검증 부족이 한계. 학술적 우수성은 높으나 실무 적용을 위해서는 효율화와 검증이 필요하다.