Achievement
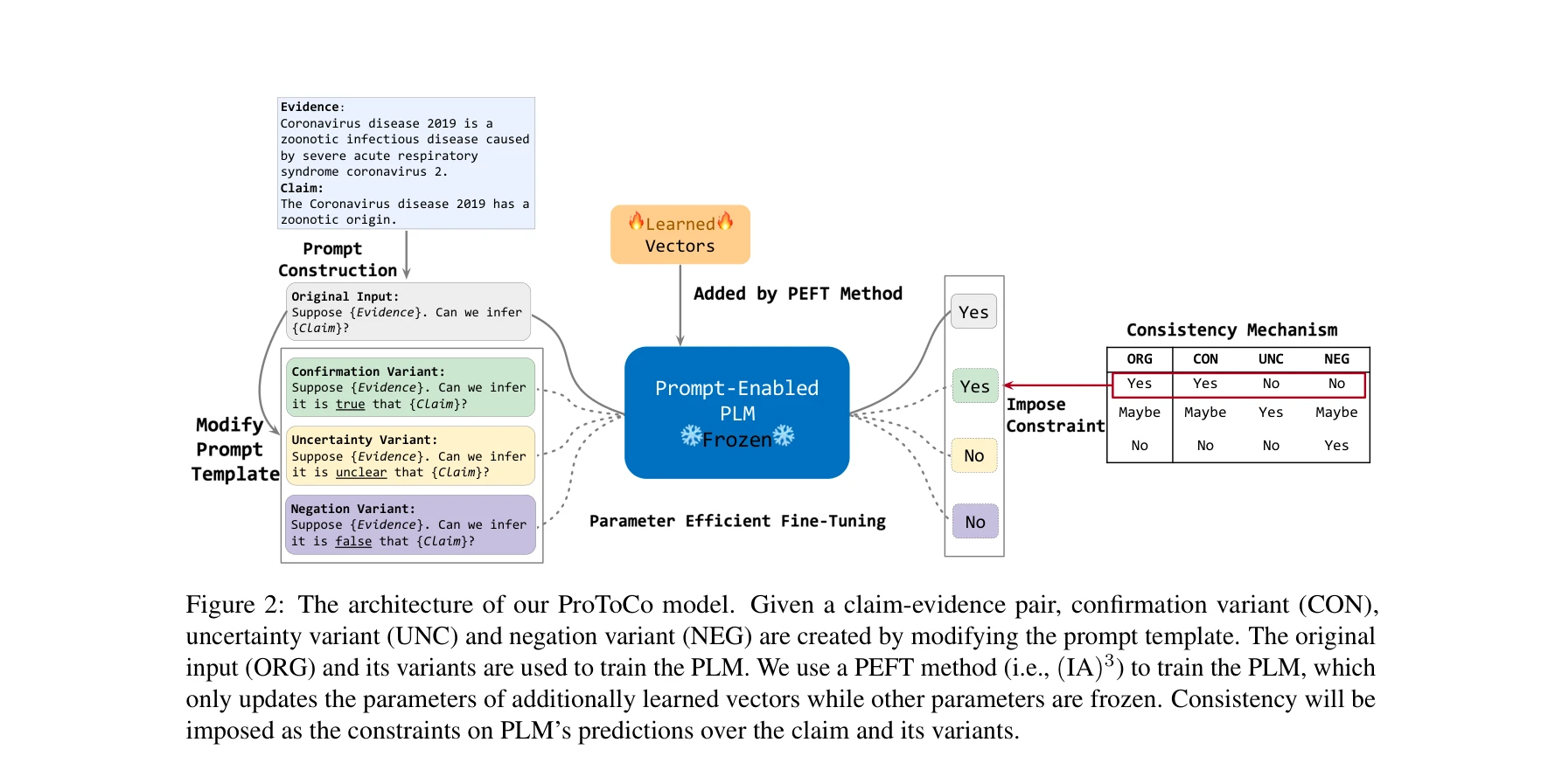
ProToCo의 아키텍처: 클레임-증거 쌍에서 프롬프트 템플릿 변형을 통해 확인(CON), 불확실성(UNC), 부정(NEG) 변형을 생성하고, (IA)3를 이용한 PEFT로 모델 일관성 학습
- Few-shot 성능: 세 개의 공개 사실검증 데이터셋에서 최신 few-shot 기준선 대비 최대 30.4% 상대 F1 개선
- Zero-shot 성능: 레이블 없는 인스턴스만으로도 강력한 영샘플 학습기 T0-3B를 지속적으로 상회
- 대규모 모델 비교: OPT-30B를 능가하고, Self-Consistency 기반 OPT-6.7B를 유의미하게 초과 (few-shot, zero-shot 모두)
