Essence

PGraphRAG 프레임워크 개요. 사용자 프로필과 상호작용 데이터로부터 사용자 중심 그래프를 구성하고, 그래프에서 구조화된 사용자 관련 정보를 검색하여 언어 모델의 생성을 조건부화함
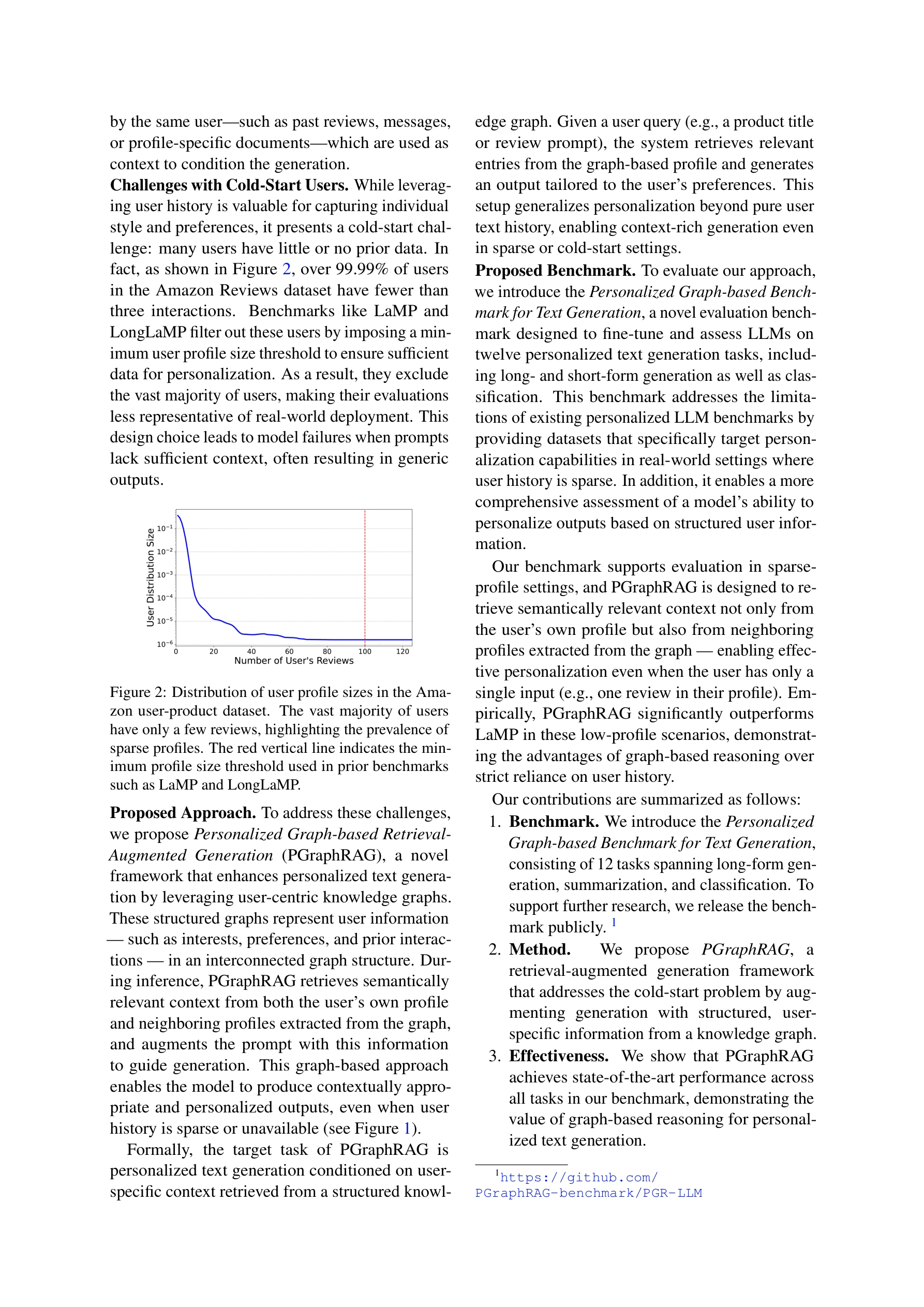
본 논문은 지식 그래프 기반의 개인화된 검색 증강 생성(PGraphRAG)을 제안하여 사용자 이력이 부족한 콜드스타트 환경에서도 LLM의 개인화된 텍스트 생성 능력을 향상시킨다. 구조화된 사용자 정보를 검색 과정에 통합하여 희소 프로필 상황에서도 유의미한 개인화를 가능하게 한다.