저자: Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D'Arcy, David Wadden, Matt Latzke, Mingliang Tian, Peng Ji, Shengyan Liu, Tong Hao, Borong Wu, Yi Xiong, Luke Zettlemoyer, Graham Neubig | 날짜: 2024 | DOI:
Essence
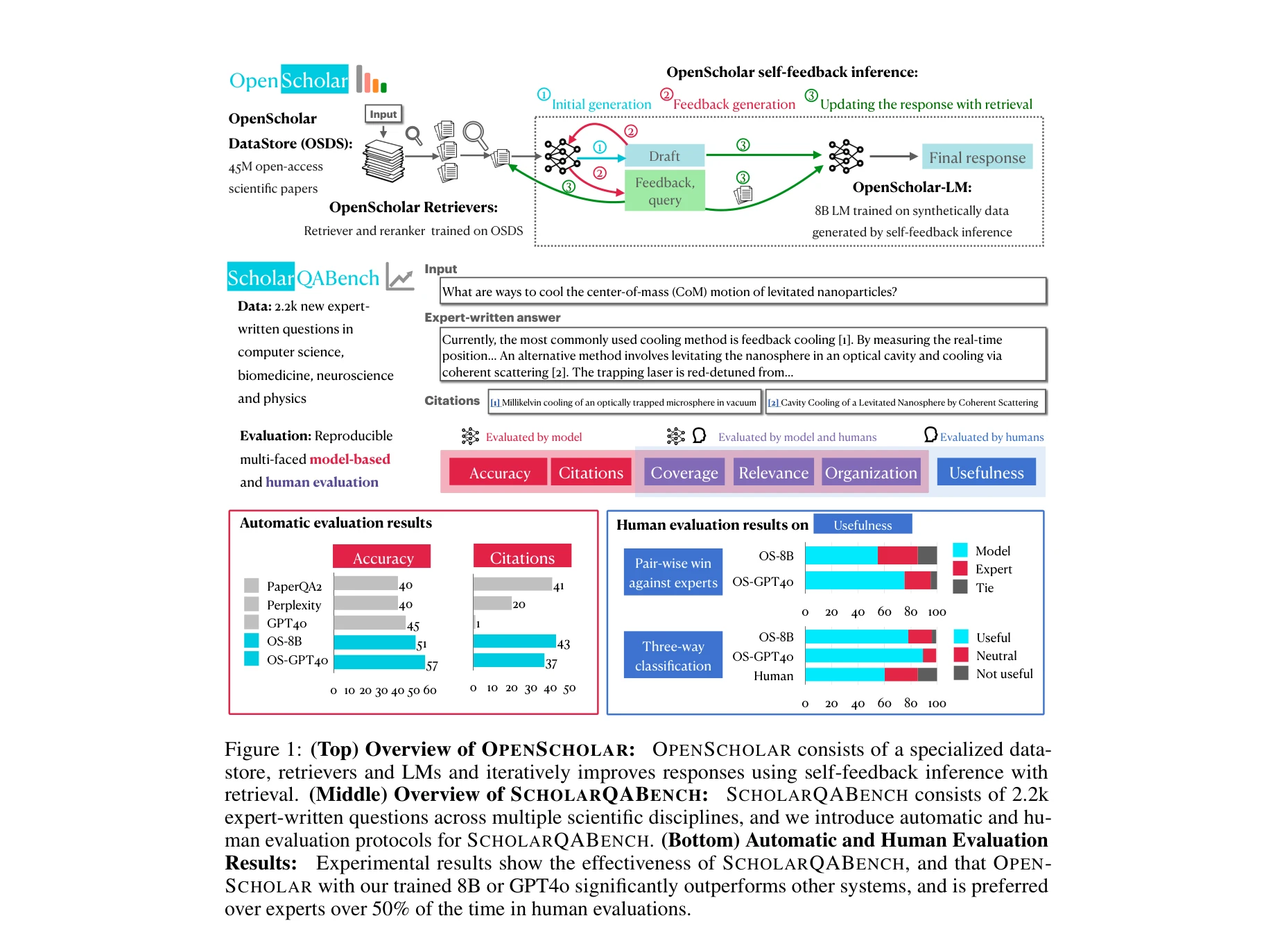
OpenScholar의 전체 개요: 전문화된 데이터스토어, 검색기 및 언어모델로 구성되며, 검색 기반 자체 피드백 추론 루프를 통해 반복적으로 응답을 개선한다.
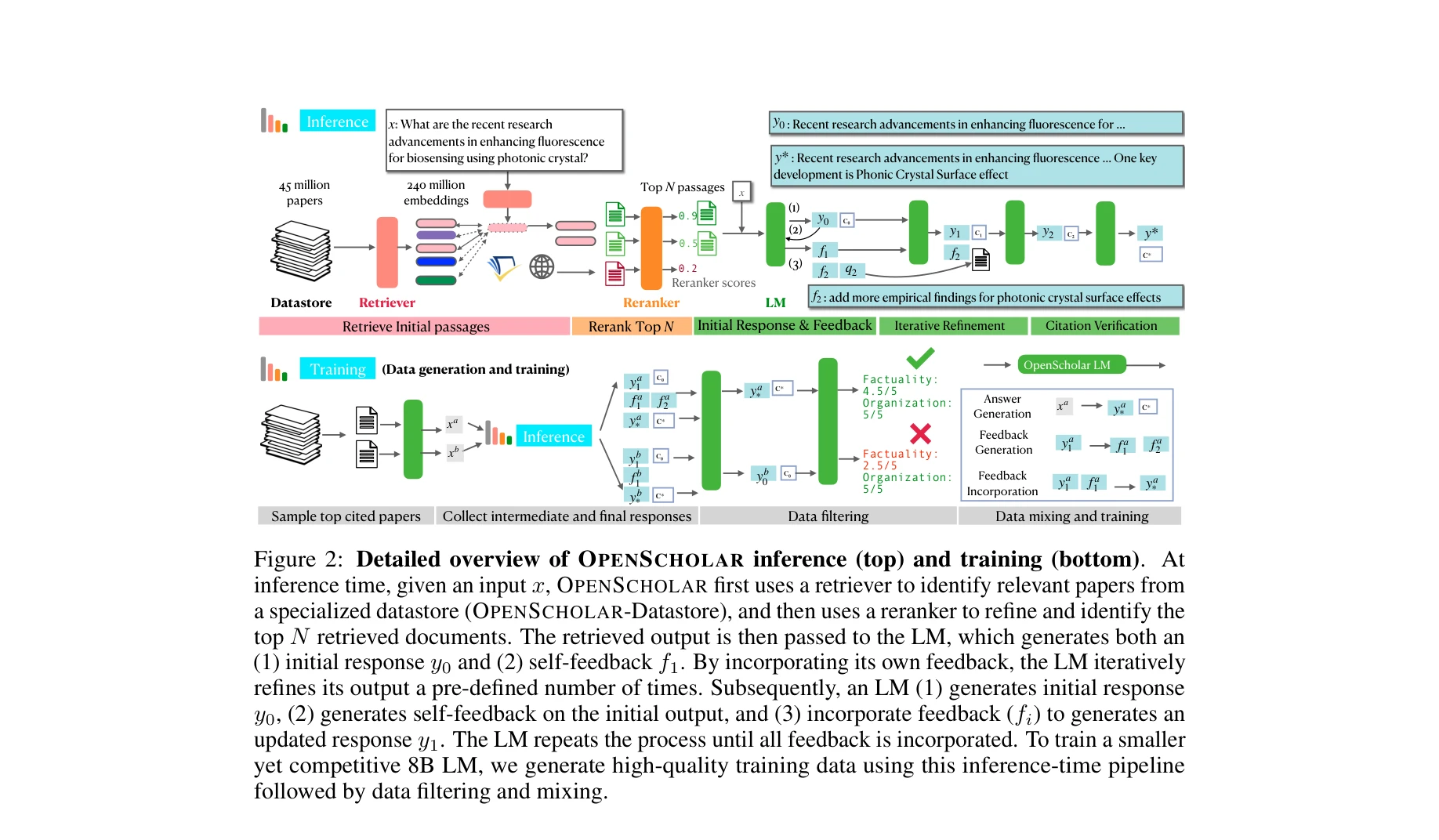
본 논문은 4,500만 개의 오픈 액세스 과학 논문에서 관련 구절을 검색하고 인용 기반 응답을 합성하는 검색 증강 대규모 언어모델(RAG-LM) 기반 시스템 OpenScholar를 제안하며, 함께 과학 논문 합성 평가를 위한 대규모 벤치마크 ScholarQA-Bench를 소개한다.
Evaluation
총평: 본 논문은 과학 문헌 합성을 위한 현실적이고 포괄적인 RAG 시스템을 제시하며, 최대 규모의 공개 데이터스토어와 다중 분야 전문가 벤치마크를 통해 중요한 평가 기반을 마련했다. 특히 인용 정확도 개선과 전문가 수준의 성능 달성이 실무적 가치가 크며, 모든 자원을 공개하여 재현성과 확장성을 확보한 점이 우수하다.