Essence
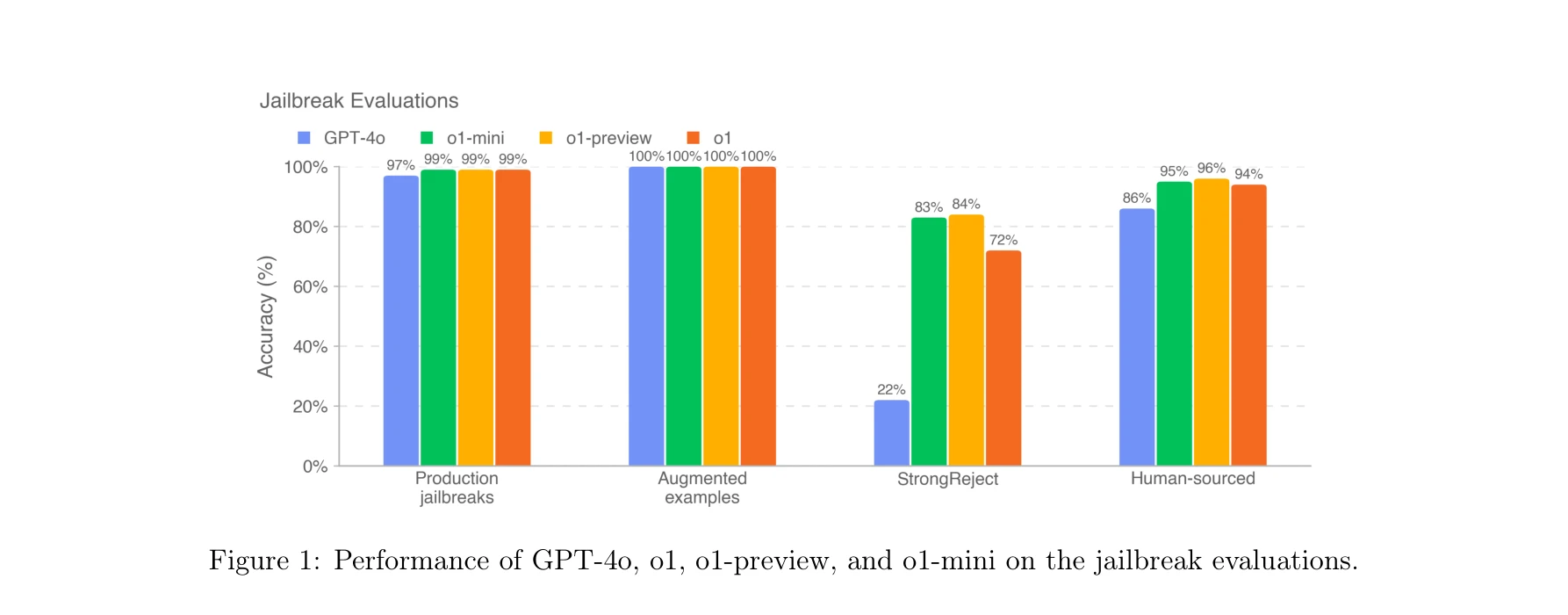
Figure 1: GPT-4o, o1, o1-preview, o1-mini의 jailbreak 평가 성능 비교
OpenAI o1 모델은 대규모 강화학습(reinforcement learning)으로 훈련된 chain-of-thought 추론 능력을 갖춘 모델로, 기존 GPT-4o 대비 안전성과 강건성이 크게 향상되었으며 특히 jailbreak 공격에 대한 저항성이 획기적으로 개선되었다.
저자: OpenAI (Aaron Jaech, Adam Tauman Kalai, Adam Lerer 등) | 날짜: 2024 | DOI: -
Figure 1: GPT-4o, o1, o1-preview, o1-mini의 jailbreak 평가 성능 비교
OpenAI o1 모델은 대규모 강화학습(reinforcement learning)으로 훈련된 chain-of-thought 추론 능력을 갖춘 모델로, 기존 GPT-4o 대비 안전성과 강건성이 크게 향상되었으며 특히 jailbreak 공격에 대한 저항성이 획기적으로 개선되었다.
총평: 본 보고서는 대규모 언어모델의 안전성 평가에 있어 chain-of-thought 추론 능력이 defensive alignment의 새로운 차원을 제시함을 실증적으로 입증했으며, 다층적이고 체계적인 평가 프레임워크를 제시한 점에서 학계와 산업 모두에 중요한 기여를 한다. 다만 chain-of-thought 자체가 야기할 수 있는 deception 위험과 도메인 특화 평가의 부족은 향후 연구의 중요한 과제로 남아있다.