Essence

전체 관련 업무(Related Work) 섹션을 인용된 논문들과 대상 논문의 전체 텍스트로부터 생성하는 태스크
본 논문은 오픈 액세스 논문의 전체 텍스트를 포함하는 대규모 관련 업무 생성 데이터셋 OARelatedWork를 제시하며, 초록(abstract)만 사용하는 기존 방식에서 벗어나 전체 콘텐츠를 활용한 다중 문서 요약 연구를 추진한다.
저자: Martin Docekal, Martin Fajcik, Pavel Smrz | 날짜: 2024 | DOI: arXiv:2405.01930
전체 관련 업무(Related Work) 섹션을 인용된 논문들과 대상 논문의 전체 텍스트로부터 생성하는 태스크
본 논문은 오픈 액세스 논문의 전체 텍스트를 포함하는 대규모 관련 업무 생성 데이터셋 OARelatedWork를 제시하며, 초록(abstract)만 사용하는 기존 방식에서 벗어나 전체 콘텐츠를 활용한 다중 문서 요약 연구를 추진한다.

문헌의 계층 구조 파싱 예시: 내부 번호 매기기와 앵커 생성 단계
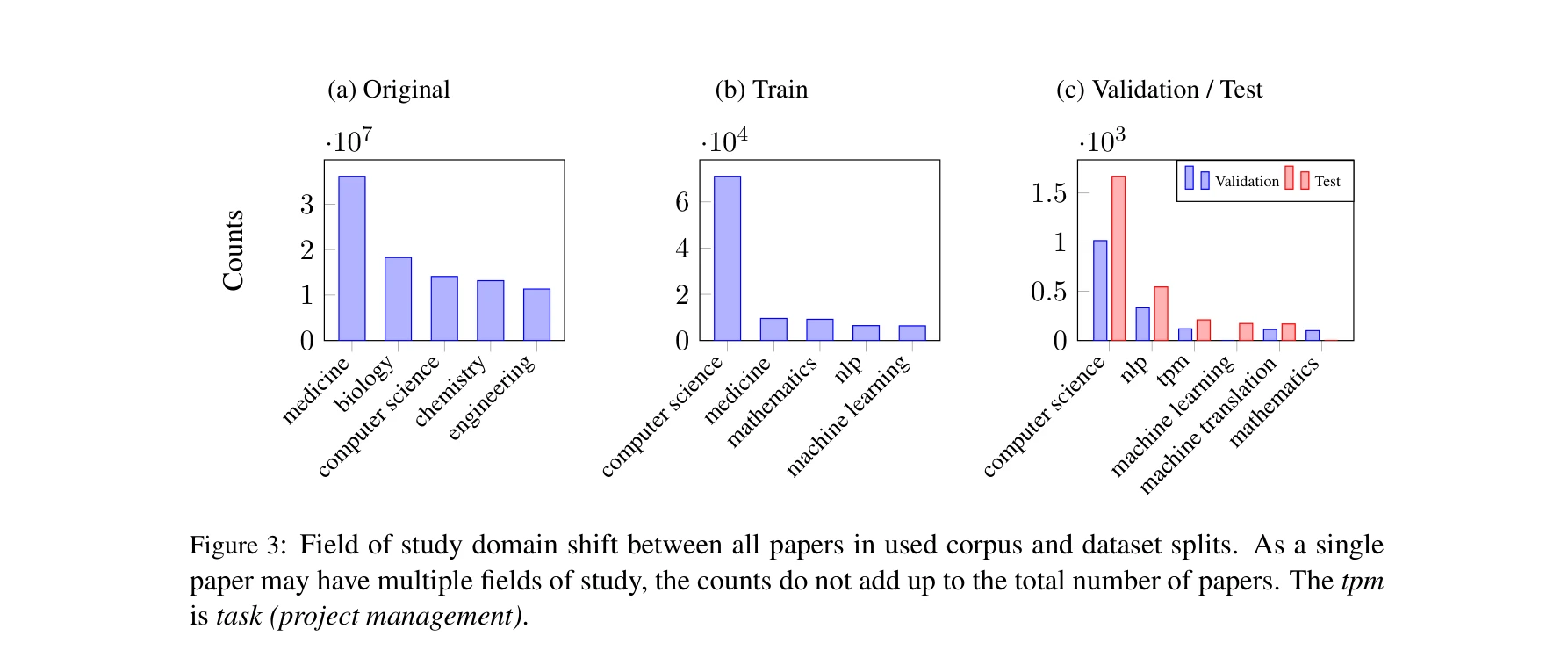
연구 도메인에 따른 데이터셋 분포의 차이
총평: 오픈 액세스 자료만으로 구축한 첫 대규모 관련 업무 데이터셋으로서 학술 요약 분야에 실질적 기여를 하며, 전체 콘텐츠 활용의 이점을 강력히 입증한 점이 주요 강점이다. 다만 자동 파이프라인의 정확성 검증과 다양한 도메인에 대한 확장성 평가가 보완되어야 한다.